 SRAM如何克服其扩展问题?有哪些方法呢?
SRAM如何克服其扩展问题?有哪些方法呢?
在高级节点使用 SRAM 需要新的方法。
SRAM无法扩展,这给功耗和性能目标带来了挑战,迫使设计生态系统提出从硬件创新到重新思考设计布局的策略。与此同时,尽管 SRAM 的初始设计已经存在很长的历史,并且目前还存在扩展限制,但它已成为人工智能的主力存储器。
SRAM 配置有六个晶体管,这使其访问时间比 DRAM 更快,但代价是在读取和写入时消耗更多能量。相比之下,DRAM 采用一个晶体管/一个电容器的设计,这使得它更便宜。但 DRAM 会影响性能,因为电容器因电荷泄漏而需要刷新。因此,自推出 60 多年以来,SRAM 一直是优先考虑较低延迟和可靠性的应用中的首选存储器。
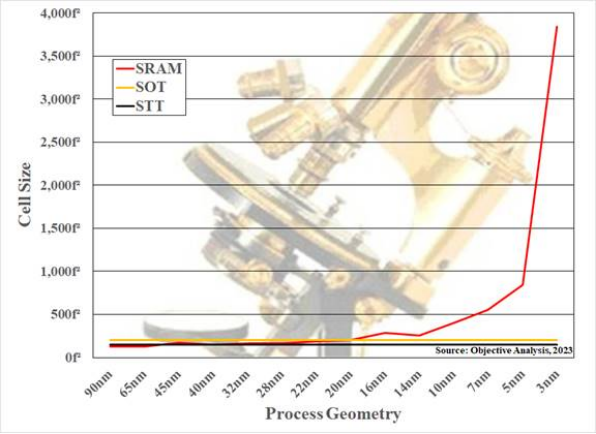
图 1:SRAM 单元尺寸缩小得比进程更慢。来源:新兴内存技术报告
事实上,对于 AI/ML 应用来说,SRAM 不仅仅具有其自身的优势。“SRAM 对于 AI 至关重要,尤其是嵌入式 SRAM。它是性能最高的存储器,您可以将其直接与高密度逻辑芯片集成。仅出于这些原因,这一点就很重要。”Alphawave Semi首席技术官托尼·陈·卡鲁松 (Tony Chan Carusone) 说道。
功耗和性能挑战
但是,在跟上 CMOS 缩放的步伐时,SRAM 却表现不佳,这对功耗和性能产生了影响。“在传统的平面器件缩放中,栅极长度和栅极氧化物厚度一起按比例缩小,以提高性能和对短沟道效应的控制。更薄的氧化物可以在更低的 VDD 电平下实现性能增益,这有利于 SRAM 减少泄漏和动态功耗。”西门子 EDA的存储器技术专家 Jongsin Yun 说道。“然而,在最近的技术节点迁移中,我们几乎没有看到氧化层或 VDD 电平进一步缩小。此外,晶体管的几何收缩导致金属互连更薄,从而导致寄生电阻增加,这就导致更多的功率损耗和 RC 延迟。
随着人工智能设计越来越需要更多的内部存储器访问,SRAM 在技术节点迁移中进一步扩大其功耗和性能优势已成为一项重大挑战。”
这些问题加上 SRAM 的高成本,不可避免地会导致性能下降。Rambus的杰出发明家 Steve Woo 表示:“如果无法获得足够的 SRAM 来满足处理器内核的数据存储需求,那么内核最终将不得不将数据移至更远的地方。” “在 SRAM 和 DRAM 之间移动数据需要额外的电力,因此系统消耗更多的电力,从 DRAM 访问数据需要更长的时间,因此性能会下降。”
imecDTCO 项目总监 Geert Hellings 表示:“展望纳米片,SRAM 的尺寸缩放预计会非常小。” “可以说,如果所有其他工艺/布局裕度保持不变,用纳米片(~15nm 宽)替换鳍片(约 15nm 宽)将使 SRAM 位单元高度增加 40nm(每个 4 个鳍片)。显然,这不是一个很好的价值主张。因此,工艺/布局余量的改进有望抵消这一点。然而,将SRAM从finFET扩展到纳米片是一场艰苦的战斗。
Flex Logix曾在几个最低节点工作过,包括台积电的 N7 和 N5,最近还收到了英特尔 1.8A节点的 PDK。Flex Logix 首席执行官 Geoffrey Tate 表示:“我们使用先进节点的客户都抱怨该逻辑的扩展性比 SRAM 更好、更快。” “这对于处理器来说是一个问题,因为拥有比整个处理器更大的缓存内存是不寻常的。但如果你把它放在芯片外,你的性能就会急剧下降。”
台积电正在聘请更多内存设计师来提高 SRAM 密度,但他们是否能从 SRAM 中获得更多收益还有待观察。Tate说:“有时,你可以通过雇佣更多的人来让事情变得更好,但仅限于一定程度。” “随着时间的推移,客户将需要考虑不再像现在那样频繁使用 SRAM 的架构。”
事实上,早在 20 纳米时代,SRAM 就无法与逻辑相称地扩展,这预示着当片上存储器变得比芯片本身更大时,将会出现功耗和性能挑战。针对这些问题,系统设计人员和硬件开发人员都在应用新的解决方案并开发新技术。
沿着这些思路,AMD采取了不同的方法。Rambus 的 Woo 表示:“他们推出了一种名为 3D V-Cache 的技术,该技术允许将单独芯片上的附加 SRAM 高速缓存存储器堆叠在处理器顶部,从而增加处理器内核可用的高速缓存量。” “额外的芯片增加了成本,但允许访问额外的 SRAM。另一种策略是拥有多级缓存。处理器内核可以拥有只有它们才能访问的私有(非共享)一级和二级缓存,以及在处理器内核之间共享的更大的末级缓存 (LLC)。由于处理器拥有如此多的内核,共享 LLC 允许某些内核使用更多容量,以便在所有处理器内核上更有效地使用总容量。”
纠错
缩放也增加了可靠性问题。Flex Logix 首席技术官 Cheng Wang 表示:“SRAM 传统上使用比逻辑单元更激进、更小的尺寸,但它与传统逻辑门不同,传统逻辑门永远不会发生争用,并且您总是在其中写入新值。” 由于 SRAM 只有六个晶体管,因此您无法添加大量门来使其在写入时变弱,在不写入时放大。你也不能让 SRAM 太小,因为这可能会因 α 粒子等问题导致单粒子扰动 (SEU),其中离子的能量压倒 SRAM 单元中的能量,随着 SRAM 缩小,这种情况更容易发生。
Wang 表示,纠错可能会成为一项常见要求,特别是对于汽车设备。
权衡
这导致设计方面发生很多变化。“每个人都试图在芯片上使用更少的 SRAM。”Wang 说。设计人员采取的另一种方法是尽可能只使用单核存储器。“在较旧的工艺节点中,当我们编写寄存器文件时,使用双核内存的可能性要大得多,”他说。“但所有这些都增加了面积。因此,在较低的节点中,设计人员试图让所有东西都从内存中的单个端口运行,因为这些是可用的最小、最密集的全功率选项。他们不一定会放弃SRAM,但他们会尽可能地使用单核存储器。他们试图使用更小的内存,并选择SRAM作为可用带宽,而不是真正的大存储。大型存储要么转移到 DRAM,如果你能承受延迟,要么转移到 HBM,如果你能负担得起成本。
替代方法:新架构
为了不断提高 SRAM 的功耗性能,我们已经评估和应用了超出位单元设计的许多更新,包括 SRAM 外围设计中的附加支持电路,Yun 表示。
“SRAM 和外围设备不再共享电源。取而代之的是,采用双电源轨来单独利用最有效的电压水平,”西门子的 Yun 说道。“在某些设计中,SRAM 可以进入休眠模式,施加保留数据所需的最低电压,直到 CPU 下次访问数据。这带来了显著的功耗优势,因为漏电流与 VDD 呈指数关系。一些 SRAM 设计采用了额外的电路来解决操作弱点,旨在提高最低工作电压。”
例如,高密度 (HD) SRAM 单元可以通过对 6 个晶体管使用单鳍晶体管来实现最小的几何形状。然而,由于相同尺寸的上拉 (PU) 和通栅极 (PG) 晶体管在写入操作期间存在争用问题,HD 单元在低电压操作中面临挑战。
“在SRAM辅助电路中,如负位线,瞬态电压崩溃技术被广泛采用,以缓解这些问题并增强低电压操作,”Yun说。“为了减轻寄生电阻效应,最新的位单元设计使用双轨或三轨金属线作为合并位线(BL)或字线(WL)。BL方法根据操作选择性地连接金属轨道,降低有效电阻并平衡阵列顶部和底部之间的放电率。在持续的开发中,正在探索埋地电源轨以进一步降低布线电阻。这涉及将所有电源轨放置在晶体管下方,从而缓解晶体管上方的信号路径拥塞。”
其他存储器、其他结构
新的嵌入式存储器类型通常被提出作为 SRAM 的替代品,但每种类型都有自己的一系列问题。“主要的竞争者MRAM和ReRAM仅占用一个晶体管面积,”Yun 说。“虽然它比 SRAM 中的晶体管大,但它们的整体单元尺寸仍约为 SRAM 的三分之一,最终的宏观尺寸目标(包括外围电路)约为 SRAM 尺寸的一半。有明显的尺寸优势,但写入速度的表现仍然远慢于SRAM。实验室在写入速度和耐用性方面取得了一些成果,但在汽车用闪存替代 MRAM 生产之后,高速 MRAM 的开发计划已经延长。L3 缓存替换的尺寸优势当然值得考虑,但 eflash 类型 MRAM 的生产必须有一个提前的提升。”
如果物理学不允许使用更小的 SRAM,则替代方案将需要重新考虑架构并采用小芯片。“如果 SRAM 无法在 N3 或 N2 中扩展,那么可以将更先进的逻辑芯片与采用旧技术制造的 SRAM 芯片结合起来,”imec 的 Hellings 说。“这种方法将受益于逻辑 PPA 的改进,同时为 SRAM 使用经济高效的(较旧的,可能更高的产量和更便宜的)技术节点。原则上,AMD 基于 V 缓存的系统可以进行扩展,仅将逻辑芯片移动到下一个节点,然后需要使用 3D 集成或小芯片方法 (2.5D) 组合两个芯片。”
Ambiq 首席技术官 Scott Hanson 指出,chiplet 解决方案非常适合正在进行的集成革命。“模拟电路很久以前就停止了缩放,出于功耗、性能和成本方面的原因,从 DRAM 到 SRAM 到 NVM 的所有类型的存储器都更喜欢在不同的节点上制造。逻辑芯片更喜欢在仍然满足成本和泄漏要求的最小节点上制造。通过多芯片集成,可以将芯片组合到单个封装中。许多人在移动和数据中心领域都听说过这一点,但它也在人工智能和物联网领域迅速发生。”
在有限的情况下,系统技术协同优化 (STCO) 也可以提供帮助。“对于某些应用,原则上不需要片上缓存,”Hellings 说。“例如,在人工智能训练中,训练数据仅使用一次,而模型参数应该可以在芯片上轻松访问。软件和芯片架构可以绕过缓存层次结构,促进这种一次性数据移动,具有很大的潜力。”
所有这些都激发了人们对新布局和互连协议(例如 UCIe 和 CXL)的兴趣。“当你有更大的人工智能工作负载时,内存会随着计算而扩展,但如果其中一个组件的扩展速度比另一个组件快一点,根据系统的设计方式,你会遇到不同的瓶颈,”新思科技的战略营销经理 Ron Lowman 说。“人工智能工作负载大大增加了所需处理器阵列的数量。他们甚至突破了芯片掩模版尺寸的限制,因此现在您需要用于芯片到芯片系统的高速互连(例如 UCIe),这意味着多芯片系统不可避免地要处理人工智能工作负载。”
解决问题的新堆栈
华邦电子通过其 CUBE 堆栈(定制超带宽元素)重新思考了内存架构。“我们使用 DRAM 作为存储单元,但也通过过孔进行 3D 堆叠,”华邦 DRAM 营销经理 Omar Ma 解释道。“您可以提供从底部基板一直到 SoC 芯片的连接。它更具成本效益,因为 DRAM 不使用 SRAM 的六个晶体管。”
CUBE 可以提供足够高的密度来替代 SRAM 直至 3 级缓存。“为了达到一定的带宽要求,只有两个选择——提高时钟速度或增加 I/O 数量,”Omar Ma 解释道。“使用 CUBE,您可以根据需要增加它们,同时减少时钟。这在系统层面带来了很多好处,包括减少对电力的需求。” CUBE 目前处于原型阶段,但预计将于 2024 年第四季度或 2025 年初投入生产。
结论
SRAM 被完全取代,这似乎不太可能,至少在短期内是这样。“几年前,英特尔演示了使用铁电存储器作为缓存,”Objective Analysis 总经理吉姆·汉迪 (Jim Handy) 说。“他们说这是 DRAM,但说实话,这是 FRAM。他们表示,优势在于他们能够使用3D NAND技术使其变得非常紧密。换句话说,他们展示了一个拥有大量内存的微小空间。其中一种类型的研究工作(无论是像英特尔所展示的那样还是 MRAM 等其他方法)很可能最终会取代 SRAM 的位置,但这可能不会很快发生。”
Handy 预计它会导致架构和操作系统软件发生变化。“你不太可能看到同一个处理器同时具有 SRAM 缓存和铁电缓存,因为软件必须进行一些更改才能利用这一点,”他说。“此外,缓存的结构将略有不同。主缓存可能会稍微缩小,而辅助缓存可能会变得非常大。在某个时候,具有 SRAM 缓存的处理器将会问世。下一代处理器将具有铁电或 MRAM 缓存或类似的东西,并对软件进行重大更改以使该配置更好地工作。”
审核编辑:刘清
-
CMOS
+关注
关注
58文章
5710浏览量
235429 -
电容器
+关注
关注
64文章
6217浏览量
99553 -
存储器
+关注
关注
38文章
7484浏览量
163775 -
sram
+关注
关注
6文章
767浏览量
114677 -
VDD
+关注
关注
1文章
311浏览量
33191
原文标题:SRAM如何克服其扩展问题?
文章出处:【微信号:ICViews,微信公众号:半导体产业纵横】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
开源芯片系列讲座第24期:基于SRAM存算的高效计算架构


SRAM和DRAM有什么区别
无损检测的方法有哪些?其原理分别是什么?
STM32U5如何把数据保存到SRAM2中?
Microchip推出容量更大、速度更快的串行SRAM产品线

Microchip推出容量更大、速度更快的串行 SRAM产品线
Microchip Technology扩展了旗下串行SRAM产品线,容量最高可达4Mb
请问DMA总线访问APB外设和SRAM1,CPU操作CCM RAM,这个是同时进行的还是分时复用的呢?
SRAM CLA和SRAM有什么区别





 工商网监
工商网监
评论