 Net5.5G智能云网即将全面发布,打造新一代数字基础设施
Net5.5G智能云网即将全面发布,打造新一代数字基础设施

中科大团队开发首个通用的大语言模型分子交互学习框架,在多个数据集超 4,000,000 个分子对上验证了其可靠性。
简述
分子关系学习(Molecular Relational Learning)旨在理解和建模分子对的交互作用,如分子对交互(Drug-drug Interaction,DDI)、溶液-溶剂交互(Solution-solvent Interaction)。近来,凭借丰富的知识储备和优秀的推演能力,大型语言模型(LLMs)已成为实现分子关系高效学习的重要工具。
尽管这一方法颇有成效,但当前范式的主要问题是数据利用的不充分。如下图(a)所示,当前范式主要依赖于文本数据(如 SMILES),未能充分且显式地利用分子图中固有的丰富结构信息。
加剧这一问题的是统一学习框架的缺失,因为其阻碍了从各个数据集中学习到的关键交互信息与底层交互逻辑的高效共享和整合。如下图 b 所示,这一缺失扩大了数据利用的不充分的影响,使得 LLMs 因高度过拟合的风险而无法建模那些广泛存在的、数据量较少的分子交互任务。
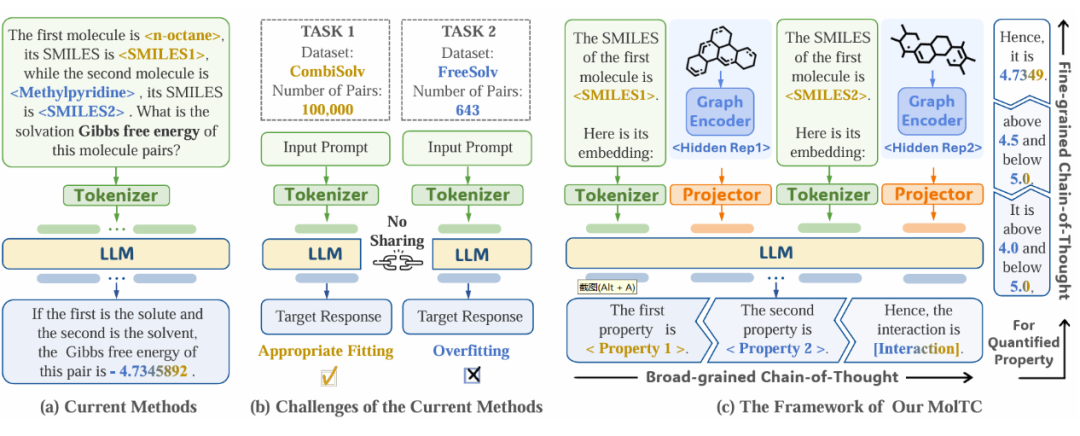
▲ 图1:当前基于 LLMs 的分子交互学习范式与 MolTC 的比较。(a)现行方法的通用范式;(b)将当前范式应用于样本量较少的任务时所带来的挑战;(c)我们的 MolTC 的架构。
为了缓解这一问题,我们提出了一个通用的、基于 LLM 的多模态分子交互学习框架,MolTC(Molecular inTeraction Modeling enhanced by Chain-of-thought theory)。如上图 c 所示,MolTC 通过图编码器(Encoder)和映射器(Projector)高效地建模分子图信息,并创新性地提出了多层级思维链(Multi-hierarchical Chain-of-thought)的概念来引导训练范式的优化。
此外,为了加强数据间的信息共享,我们为其设计了一个新颖的动态参数共享策略,以实现效率和精度的双赢。同时,鉴于这一领域数据集的缺失,我们还构建了一个全面的分子交互指令数据集,MoT-instructions,用于提高当前基于 LLMs 的学习框架(包扩我们的 MolTC)对分子交互任务的理解能力。
我们在涉及超过 4,000,000 个分子对的十二个不同领域数据集上进行了验证实验。结果表明,我们的方法优于当前基于 GNN 的、基于(除 GNN 外)其它传统深度学习架构的、和基于 LLMs 的基线方法。
多模态输入框架
我们首先简要介绍上图 c 中所示的 MolTC 框架。其中,Graph Encoder 采用传统的图神经网络(GNN)架构;Projector 采用在视觉领域常用于多模态对齐的 Querying Transformers (Q-Former)架构,作为 backbone 的 LLM 则是采用在生化任务中表现突出的 Galactica。更多细节劳请移步我们的论文和代码。
基于多层级思维链的训练范式
我们重点介绍基于多层级思维链的 MolTC 训练范式。首先,考虑到从分子对中直接生成复杂相互作用的挑战性,处于上层的思维链指导 MolTC 的预训练过程优先识别并按次序输出输入分子对中,每个分子的关键生化性质,为准确预测它们的交互奠定基础。具体而言,在预训练阶段,Prompts 的统一设计如下:

预训练阶段的数据来自多个权威的、包含分子-性质对的生化数据库如 Drugbank 和 PubChem。为了提高 MolTC 在不同分子交互场景下的泛化能力,我们对上述数据库中的分子进行随机组合,来构造不同的分子对。
随后,在微调阶段,针对定性分子交互分析任务,Prompts 直接根据特定的下游任务进行定制。而针对传统 LLMs 较难处理的定量分析任务,下层的思维链指导 MolTC 优先为目标数值预估一个大致的范围,然后逐步将其细化到一个精确的值。以溶液-溶剂交互任务为例,其 Prompts 的设计如下:

动态参数共享策略
为了提高上述训练范式的效率,MolTC 引入了一种新颖的参数共享策略。具体而言,我们首先考虑分子交互任务的以下关键属性:
(1)交互中分子角色的重要性。例如,在溶液-溶剂交互场景中,水和乙醇互为溶剂会产生不同的能量释放。某些时候,角色的颠倒甚至会导致交互反应的停滞。
(2)交互中分子顺序的重要性。例如,在药物对交互场景中,药物引入顺序的不同可能会导致不同的治疗效果。
(3)分子角色/顺序带来的特征重要性的差异。例如,在发色团-溶液对中,一个化学基团在溶液内会对交互属性产生关键的影响,但其在发色团中时,则可能对交互无足轻重。
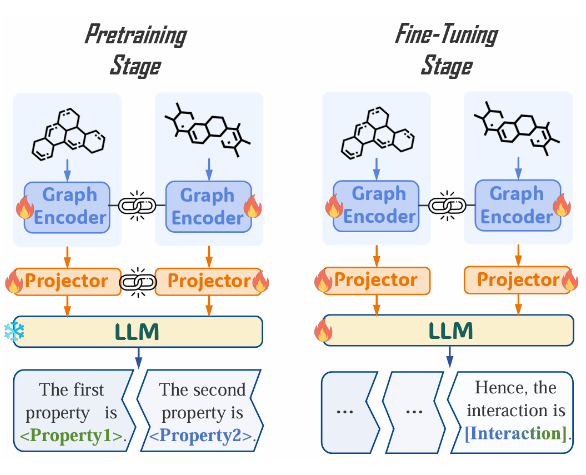
▲ 图2:应用动态参数共享策略后的的 MolTC 训练范式。其中,链环表示两个模块之间的参数共享;雪花表示参数冻结;火焰表示参数更新。
这些属性自然地启发 MolTC 适应性地优先考虑俩个分子内的不同信息,即根据角色和顺序为分子创建独特的编码。具体而言,为了学习到这种差异性,同时维持分子对中学习到的共性信息的共享,我们引入了如下参数共享策略:
(1)考虑 Graph Encoder 专注于提取底层的分子图结构,并未将语义与分子结构进行对齐,因此,在预训练和微调阶段,MolTC 共享俩个 Graph Encoder 的参数,以增强其学习效率。
(2)考虑 Projector 专注于实现分子结构与语义信息的对齐,因此,在预训练阶段,MolTC 共享俩个 Projector 的参数以提高系统的泛化性和鲁棒性;在微调阶段,MolTC 终止这一共享,实现根据不同下游任务中的分子角色和顺序量身定制的语义映射。
MoT-instruction数据集开发
在 MolTC 的训练过程中,鉴于当前缺乏一个通用的、为大模型分子关系学习量身定制的指令数据集,我们首先给出这一数据集应当满足的关键性质:(1)它应包含横跨多个领域的、可以进行交互的大量分子对;(2)它应详细描述这些分子对中每个分子的重要生化属性,以及(3)它应根据思维链的形式阐述分子对的交互性质。
具体来说,我们通过以下三步构建上述 MoT-instructions 数据集:
(1)我们首先收集多个具有代表性的分子交互数据集,并从 DrugBank 和 PubChem 等权威生化数据库中获取这些交互所涉及分子的生化属性;
(2)随后,我们进行最优指令确定。具体而言,我们根据训练 MolTC 得到的预测性能作为指标,来对定量交互 instructions 中的数值区间进行设定。并结合该值的统计数据(如均值和方差)得出最优区间设定和统计数据之间的规律,推广至更多的定量交互数据集中;
(3)最后,我们将交互涉及的每个属性单独抽取至一个独立的数据空间,以在排除交互属性中缺失值、模糊值的干扰下,不浪费分子对所提供的其他有用信息。
实验
为了更全面地评估 MolTC 的有效性,我们将基线算法分为三类:基于 GNN 的、基于其他深度学习模型的以及基于 LLMs 的方法。部分定性和定量的实验结果如下表所示。更多结果如消融实验结果烦请移步我们的文章或代码。
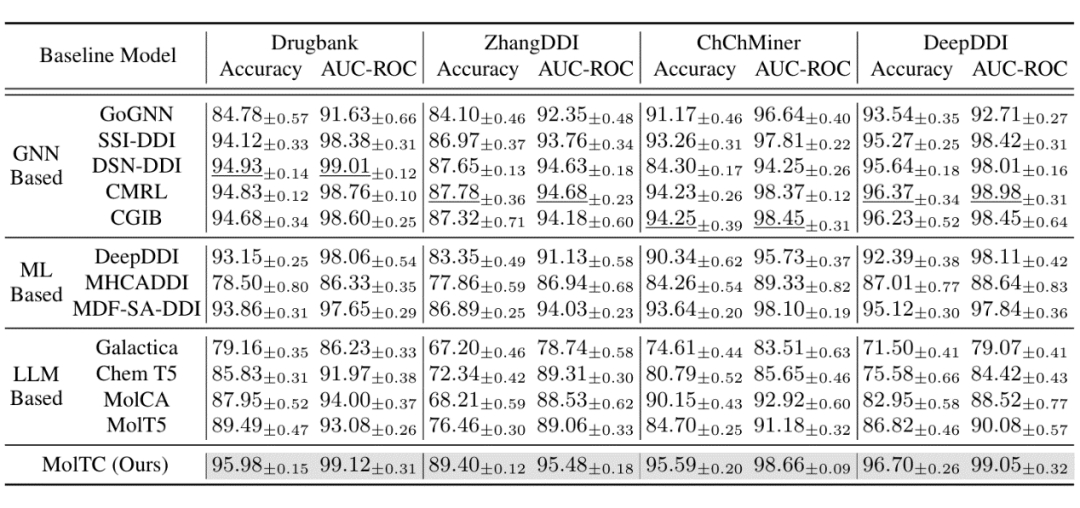
▲ 表1:定性实验结果(以药物对交互任务为例)
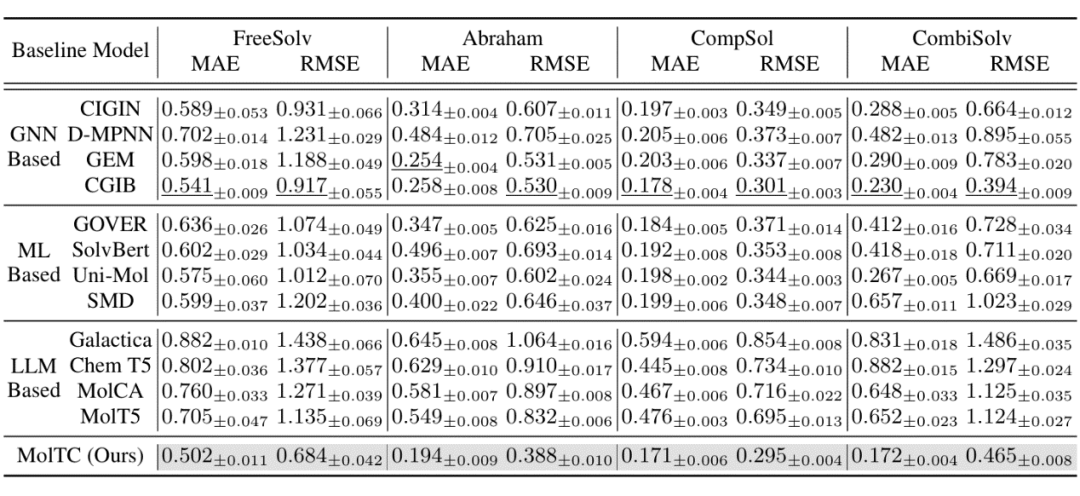
▲ 表2:定量实验结果(以溶液溶剂交互任务为例)
审核编辑:刘清
-
编码器
+关注
关注
45文章
4013浏览量
143462 -
语言模型
+关注
关注
0文章
575浏览量
11345 -
GNN
+关注
关注
1文章
31浏览量
6819 -
LLM
+关注
关注
1文章
350浏览量
1397
原文标题:MWC 2024 | 倒计时1天!Net5.5G智能云网即将全面发布,打造新一代数字基础设施
文章出处:【微信号:Huawei_Fixed,微信公众号:华为数据通信】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
2026年云网智联大会在北京成功举办
Molex产品组合推动下一代数据中心高速互连
华为面向Net5.5G产品方案推动产业加速迈向智能时代
华为在MWC 2026升级面向Net5.5G的IP承载网
华为在MWC 2026正式发布新一代智能电信云解决方案TICC 2.0
新一代AtomGit平台暨人工智能开源社区发布
华为发布以AI-Centric全面升级的AI WAN解决方案
IDC副总裁畅谈Net5.5G的创新场景
【内测活动同步开启】这么小?这么强?新一代大模型MCP开发板来啦!
华为Net5.5G助力IP网络迈入智能新时代
摩尔线程“AI工厂”:以系统级创新定义新一代AI基础设施

Net5.5G的四大技术亮点
华为开发者大会2025(HDC 2025)亮点:华为云发布盘古大模型5.5 宣布新一代昇腾AI云服务上线




评论