 字节跳动发布文生图开放模型,迅速冲上Hugging Face Spaces热榜
字节跳动发布文生图开放模型,迅速冲上Hugging Face Spaces热榜
很高兴跟大家分享我们最新的文生图模型 —— SDXL-Lightning,它实现了前所未有的速度和质量,并且已经向社区开放。
闪电般的图片生成
生成式 AI 正凭借其根据文本提示(text prompts)创造出惊艳图像乃至视频的能力,赢得全球的瞩目。当前最先进的生成模型依赖于扩散过程(diffusion),这是一个将噪声逐步转化为图像样本的迭代过程。这个过程需要耗费巨大的计算资源并且速度较慢,在生成高质量图像样本的过程中,单张图像的处理时间约为 5 秒,其中通常需要多次(20 到 40 次)调用庞大的神经网络。这样的速度限制了有快速、实时生成需求的应用场景。如何在提升生成质量的同时加快速度,是当前研究的热点领域,也是我们工作的核心目标。
SDXL-Lightning 通过一种创新技术——渐进式对抗蒸馏(Progressive Adversarial Distillation)——突破了这一障碍,实现了前所未有的生成速度。该模型能够在短短 2 步或 4 步内生成极高质量和分辨率的图像,将计算成本和时间降低十倍。我们的方法甚至可以在 1 步内为超时敏感的应用生成图像,虽然可能会稍微牺牲一些质量。
除了速度优势,SDXL-Lightning 在图像质量上也有显著表现,并在评估中超越了以往的加速技术。在实现更高分辨率和更佳细节的同时保持良好的多样性和图文匹配度。
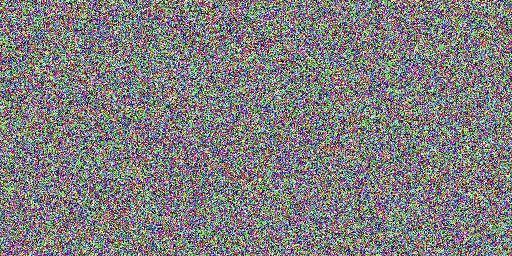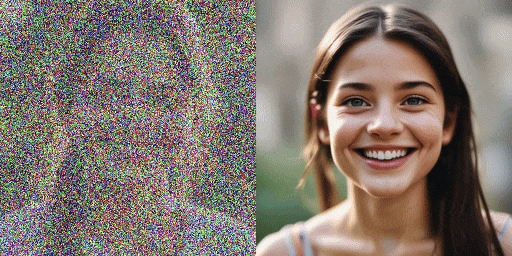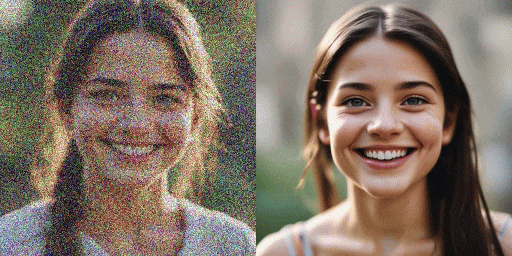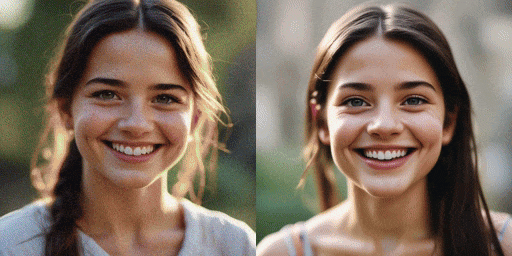
速度对比示意
原始模型(20 步),SDXL-Lightning 模型(2 步)
模型效果
SDXL-Lightning 模型可以通过 1 步、2 步、4 步和 8 步来生成图像。推理步骤越多,图像质量越好。
以下是 4 步生成结果——
以下是 2 步生成结果—— 与以前的方法(Turbo 和 LCM)相比,我们的方法生成的图像在细节上有显著改进,并且更忠实于原始生成模型的风格和布局。

回馈社区,开放模型
开源开放的浪潮已经成为推动人工智能迅猛发展的关键力量,字节跳动也自豪地成为这股浪潮的一部分。我们的模型基于目前最流行的文字生成图像开放模型 SDXL,该模型已经拥有一个繁荣的生态系统。现在,我们决定将 SDXL-Lightning 开放给全球的开发者、研究人员和创意从业者,以便他们能访问并运用这一模型,进一步推动整个行业的创新和协作。
在设计 SDXL-Lightning 时,我们就考虑到与开放模型社区的兼容。社区中已有众多艺术家和开发者创建了各种各样的风格化图像生成模型,例如卡通和动漫风格等。为了支持这些模型,我们提供 SDXL-Lightning 作为一个增速插件,它可以无缝地整合到这些多样风格的 SDXL 模型中,为各种不同模型加快图像生成的速度。 
SDXL-Lightning 模型也可以和目前非常流行的控制插件 ControlNet 相结合,实现极速可控的图片生成。
SDXL-Lightning 模型也支持开源社区里目前最流行的生成软件 ComfyUI,模型可以被直接加载来使用:
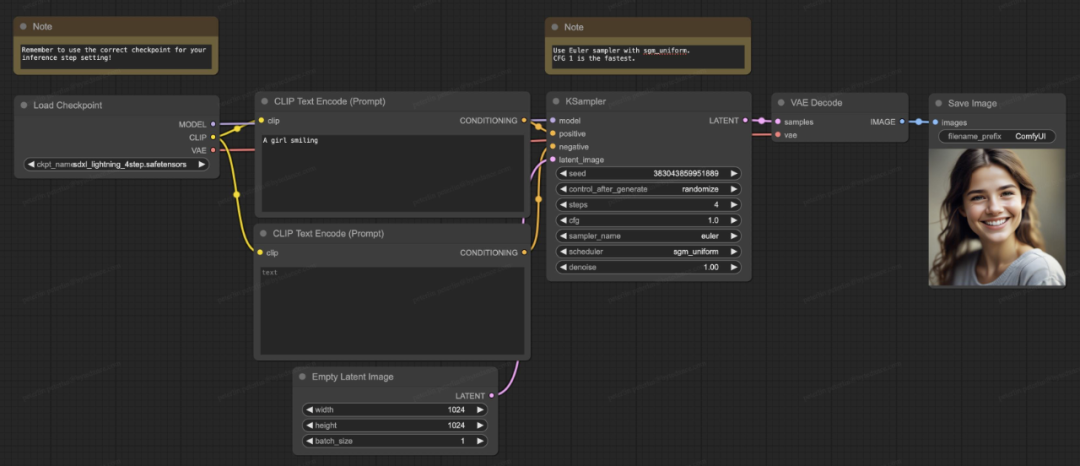
关于技术细节
从理论上来说,图像生成是一个由噪声到清晰图像的逐步转化过程。在这一过程中,神经网络学习在这个转化流(flow)中各个位置上的梯度。
生成图像的具体步骤是这样的:
首先我们在流的起点,随机采样一个噪声样本,接着用神经网络计算出梯度。根据当前位置上的梯度,我们对样本进行微小的调整,然后不断重复这一过程。每一次迭代,样本都会更接近最终的图像分布,直至获得一张清晰的图像。 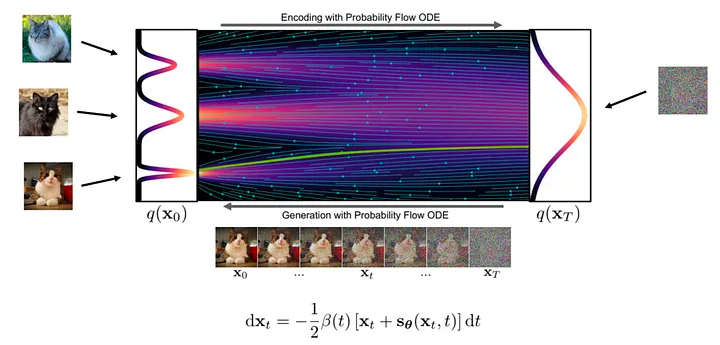
图:生成流程(来自:https://arxiv.org/abs/2011.13456)
由于生成流复杂且非直线,生成过程必须一次只走一小步以减少梯度误差累积,所以需要神经网络的频繁计算,这就是计算量大的原因。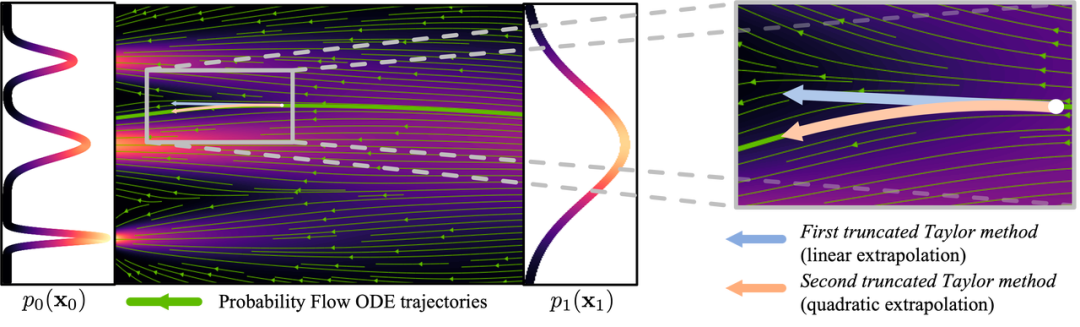
图:曲线流程(图片来自:https://arxiv.org/abs/2210.05475)
为了减少生成图像所需的步骤数量,许多研究致力于寻找解决方案。一些研究提出了能减少误差的采样方法,而其他研究则试图使生成流更加直线化。尽管这些方法有所进展,但它们仍然需要超过 10 个推理步骤来生成图像。
另一种方法是模型蒸馏,它能够在少于 10 个推理步骤的情况下生成高质量图像。不同于计算当前流位置下的梯度,模型蒸馏改变模型预测的目标,直接让其预测下一个更远的流位置。具体来说,我们训练一个学生网络直接预测老师网络完成了多步推理后的结果。这样的策略可以大幅减少所需的推理步骤数量。通过反复应用这个过程,我们可以进一步降低推理步骤的数量。这种方法被先前的研究称之为渐进式蒸馏。
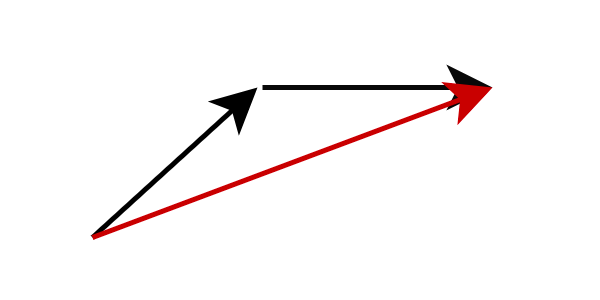
图:渐进式蒸馏,学生网络预测老师网络多步后的结果
在实际操作中,学生网络往往难以精确预测未来的流位置。误差随着每一步的累积而放大,导致在少于 8 步推理的情况下,模型产生的图像开始变得模糊不清。
为了解决这个问题,我们的策略是不强求学生网络精确匹配教师网络的预测,而是让学生网络在概率分布上与教师网络保持一致。换言之,学生网络被训练来预测一个概率上可能的位置,即使这个位置并不完全准确,我们也不会对它进行惩罚。这个目标是通过对抗训练来实现的,引入了一个额外的判别网络来帮助实现学生网络和教师网络输出的分布匹配。
这是我们研究方法的简要概述。在技术论文(https://arxiv.org/abs/2402.13929)中,我们提供了更深入的理论分析、训练策略以及模型的具体公式化细节。
SDXL-Lightning 之外
尽管本研究主要探讨了如何利用 SDXL-Lightning 技术进行图像生成,但我们所提出的渐进式对抗蒸馏方法的应用潜力不局限于静态图像的范畴。这一创新技术也可以被运用于快速且高质量生成视频、音频以及其他多模态内容。我们诚挚邀请您在 HuggingFace 平台上体验 SDXL-Lightning,并期待您宝贵的意见和反馈。
审核编辑:刘清
-
神经网络
+关注
关注
42文章
4771浏览量
100721 -
LCM
+关注
关注
6文章
57浏览量
34556 -
字节跳动
+关注
关注
0文章
317浏览量
8925 -
生成式AI
+关注
关注
0文章
502浏览量
471
原文标题:就是“快”!字节跳动发布文生图开放模型,迅速冲上Hugging Face Spaces 热榜
文章出处:【微信号:AI前线,微信公众号:AI前线】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
字节跳动否认与中兴通讯合作传闻
字节跳动自研视频生成模型Seaweed开放
华发数智携手字节跳动共同发布AI数字人及大模型综合解决方案
Hugging Face科技公司推出SmolLM系列语言模型
字节跳动发布豆包MarsCo智能开发工具
字节跳动否认AI手机研发项目
快手自研文生图大模型“可图”开放,支持AI图像创作及定制
谷歌发布AI文生图大模型Imagen
字节跳动发布豆包大模型
南开大学和字节跳动联合开发一款StoryDiffusion模型
ServiceNow、Hugging Face 和 NVIDIA 发布全新开放获取 LLM,助力开发者运用生成式 AI 构建企业应用

字节跳动辟谣推出中文版Sora 期待国产Sora大模型
字节跳动辟谣推出中文版Sora
字节跳动推出一款颠覆性视频模型—Boximator





 工商网监
工商网监
评论