 MySQL单表数据量限制:为何2000万行成为瓶颈?
MySQL单表数据量限制:为何2000万行成为瓶颈?
最近看到一篇《我说MySQL每张表最好不要超过2000万数据,面试官让我回去等通知》的文章,非常有趣。
文中提到,他朋友在面试的过程中说,自己的工作就是把用户操作信息存到MySQL里,因为数据量超大(5000万条左右),需要每天定时生成3张表,然后将数据取模分别存到这三张表里。
下面是两人的对话:
面试后续暂且不论,不过,互联网江湖上的确流传着一个说法:单表数据量超过500万行时就要进行分表分库,已经超过2000万行时MySQL的性能就会急剧下降。
那么,MySQL一张表最多能存多少数据?
今天我们就从技术层面剖析一下,MySQL单表数据不能过大的根本原因是什么?
猜想一:是索引深度吗?
很多人认为:数据量超过500万行或2000万行时,引起B+tree的高度增加,延长了索引的搜索路径,进而导致了性能下降。事实果真如此吗?
我们先理一下关系,MySQL采用了索引组织表的形式组织数据,叶子节点存储数据,非叶子节点存储主键与页面号的映射关系。若用户的主键长度是8字节时,MySQL中页面偏移占4个字节,在非叶子节点的时候实际上是8+4=12个字节,12个字节表示一个页面的映射关系。
MySQL默认是16K的页面,抛开它的配置header,大概就是15K,因此,非叶子节点的索引页面可放15*1024/12=1280条数据,按照每行1K计算,每个叶子节点可以存15条数据。同理,三层就是15*1280*1280=24576000条数据。只有数据量达到24576000条时,深度才会增加为4,所以,索引深度没有那么容易增加,详细数据可参考下表:

搜索路径延长导致性能下降的说法,与当时的机械硬盘和内存条件不无关系。
之前机械硬盘的IOPS在100左右,而现在普遍使用的SSD的IOPS已经过万,之前的内存最大几十G,现在服务器内存最大可达到TB级。
因此,即使深度增加,以目前的硬件资源,IO也不会成为限制MySQL单表数据量的根本性因素。
那么,限制MySQL单表不能过大的根本性因素是什么?
猜想二:是SMO无法并发吗?
我们可以尝试从MySQL所采用的存储引擎InnoDB本身来探究一下。
大家知道InnoDB引擎使用的是索引组织表,它是通过索引来组织数据的,而它采用B+tree作为索引的数据结构。
B+Tree操作非原子,所以当一个线程做结构调整(SMO,Struction-Modification-Operation)时一般会涉及多个节点的改动。
SMO动作过程中,此时若有另一个线程进来可能会访问到错误的B+Tree结构,InnoDB为了解决这个问题采用了乐观锁和悲观锁的并发控制协议。
InnoDB对于叶子节点的修改操作如下:
方式一,先采用乐观锁的方式尝试进行修改
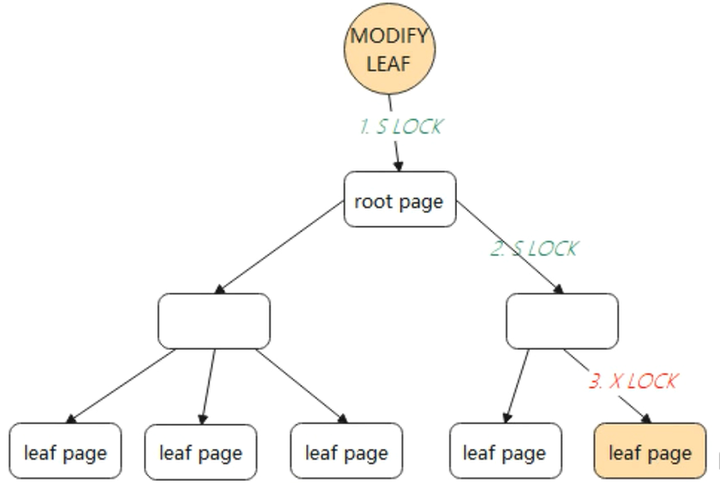
对根节点加S锁(shared lock,叫共享锁,也称读锁),依次对非叶子节点加S锁。
如果叶子节点的修改不会引起B+Tree结构变动,如分裂、合并等操作,那么只需要对叶子节点进行加X锁(exclusive lock,叫排他锁,也称为写锁)即可完成修改。如下图中所示 :
方式二,采用悲观锁的方式
如果对叶子结点的修改会触发SMO,那么会采用悲观锁的方式。
采用悲观锁,需要重新遍历B+Tree,对根节点加全局SX锁(SX锁是行锁),然后从根节点到叶子节点可能修改的节点加X锁。
在整个SMO过程中,根节点始终持有SX锁(SX锁表示有意向修改这个保护的范围,SX锁与SX锁、X锁冲突,与S锁不冲突),此时其他的SMO则需要等待。
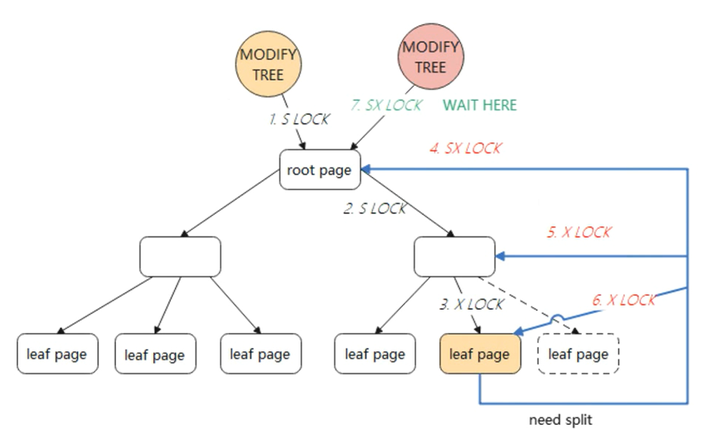
因此,InnoDB对于简单的主键查询比较快,因为数据都存储在叶子节点中,但对于数据量大且改操作比较多的TP型业务,并发会有很严重的瓶颈问题。
在对叶子节点的修改操作中,InnoDB可以实现较好的1与1、1与2的并发,但是无法解决2的并发。因为在方式2中,根节点始终持有SX锁,必须串行执行,等待上一个SMO操作完成。这样在具有大量的SMO操作时,InnoDB的B+Tree实现就会出现很严重的性能瓶颈。
解决方案
目前业界有一个更好的方案B-Link Tree,与B+Tree相比,B-Link Tree优化了B+Tree结构调整时的锁粒度,只需要逐层加锁,无需对root节点加全局锁。因此,可以做到在SMO过程中写操作的并发执行,保持高并发下性能的稳定。
B-Link Tree主要改进点有2个:
1.中间节点增加link指针,指向右兄弟节点;
2.每个节点内增加字段high key,存储该节点中最大的key值。
新增的link指针是为了解决SMO过程中并发写的问题,在SMO过程中,B-Link Tree对修改节点逐层加锁,修改完一层即可放锁,然后去加上一层节点的锁继续修改。这样在InnoDB引擎中被SMO阻塞的写操作可以有机会在SMO操作过程中并发进行。
如下图所示,在节点2分裂为节点2和4的过程中,只需要在最后一步将父节点1指向新节点4时,对父节点1加锁,其他操作均无需对父节点加锁,更无需对root节点加锁,因此,大大提升了SMO过程中写操作的并发度。
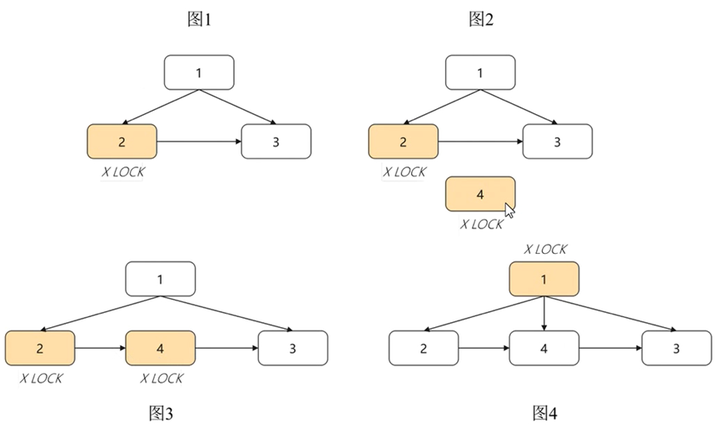
由此可见,与B+Tree全局加锁对比,B-Link Tree在高并发操作下的性能是显著优于B+Tree的。GaussDB当前采用的就是B-Link Tree索引数据结构。
InnoDB的索引组织表更容易触发SMO
索引组织表的叶子节点,存储主键以及应对行的数据,InnoDB默认页面为16K,若每行数据的大小为1000字节,每个叶子节点仅能存储16行数据。
在索引组织表中,当叶子节点的扇出值过低时,SMO的触发将更加频繁,进而放大了SMO无法并发写的缺陷。
目前业界有一个堆组织表的数据组织方案,也是华为云数据库GaussDB采用的方案。它的叶子节点存储索引键以及对应的行指针(所在的页面编号及页内偏移),堆组织表叶子节点可以存更多的数据,分析可得在同样的数据量与业务并发量下,堆组织表会比索引组织表发生SMO概率低许多。
性能对比
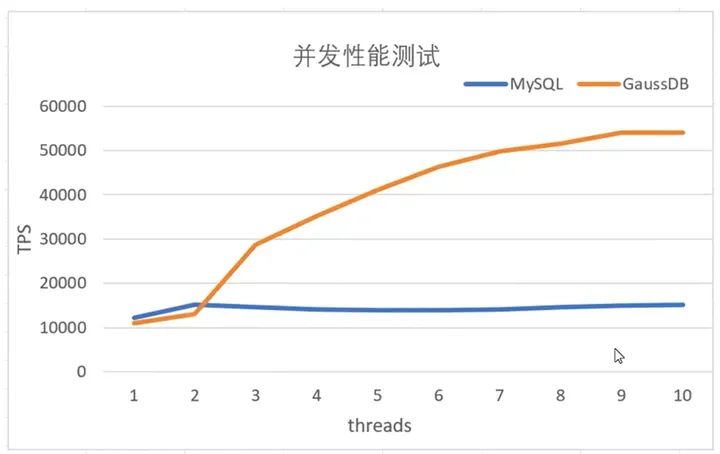
在8U32G的两台服务器分别搭建了MySQL(B+Tree和索引组织表)与GaussDB(B-Link Tree和堆组织表)的环境,进行了如下性能验证:
实验场景:在基础表的场景上,测试增量随机插入性能。
1.基础表总大小10G,包含主键随机分布的1000w行数据,每行数据1k;
2.插入主键随机分布的1000w行数据,每行数据大小1k,测试并发插入性能。
结论:随着并发数的上升,GaussDB能稳步提升系统的TPS,而MySQL并发数的提高并不能带来TPS的显著提升。
综上所述,MySQL无法支持大数据量下并发修改的根本原因,是由于其索引并发控制协议的缺陷造成的,而MySQL选择索引组织表,又放大了这一缺陷。所以,开源MySQL数据库更适用于主键查询为主的简单业务场景,如互联网类应用,对于复杂的商业场景限制比较明显。
相比之下 ,采用B-Link Tree和堆组织表的GaussDB数据库在性能和场景应用方面更胜一筹。
审核编辑:黄飞
-
服务器
+关注
关注
12文章
9368浏览量
86287 -
数据库
+关注
关注
7文章
3860浏览量
64832 -
指针
+关注
关注
1文章
482浏览量
70646 -
MySQL
+关注
关注
1文章
833浏览量
26804
原文标题:为什么MySQL单表不能超过2000万行?
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
谁说MySQL单表行数不要超过2000W?
MySQL表分区类型及介绍
800万行代码的鸿蒙系统,在世界上处于什么水平?
【HarmonyOS】800万行代码的鸿蒙系统,在世界上处于什么水平?
RoHS金属物质含量限制参考
基于Power图求解容量限制P种植问题建模
B+树索引如何对Mysql单表数据量造成影响
涛思数据开源TDengine,10多万行C代码,登顶GitHub!

为什么 MySQL 单表不能超过 2000 万行?

如何提高Mysql数据库的访问瓶颈





 工商网监
工商网监
评论