 英伟达联手推出StarCoder2 LLM系列模型,成代码生成领域新标杆
英伟达联手推出StarCoder2 LLM系列模型,成代码生成领域新标杆

近期,英伟达与Hugging Face及ServiceNow携手推出新品StarCoder2系列LLMs模型,致力于在代码生成领域建立新的行业标杆,凭借诸多优势凸显性能、透明度以及经济性。
此系列共包含三款模型,其中ServiceNow负责训练的30亿参数模型、Hugging Face训练的70亿参数模型以及英伟达训练的150亿参数模型。
新一代模型得以实现,借助Stack v2代码集,该数据集容量是上一代Stack v1的7倍之多。此外,创新性的训练技术使其能够更精准地解析低资源编程语言、数学和程序源代码讨论等内容。
经过619门编程语言的训练后,StarCoder2支持多种专业任务,例如源代码生成、工作流创建以及文本摘要等。英伟达承诺,开发者可借此进行代码填充、高层次代码摘要以及代码片段搜索等操作,以提升工作效率。
相比初版StarCoder LLM,这款30亿参数的最新模型对优质参数进行了更为精确的筛选,性能相当于初版150亿参数模型的StarCoder。
特别值得关注的是,StarCoder2特许使用BigCode Open RAIL-M许可证,无需支付任何版权费用即可享受使用权。IT之家建议有需用户前往BigCode项目GitHub页面下载源代码,同时亦可在Hugging Face获取模型信息。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
编程语言
+关注
关注
10文章
1965浏览量
39883 -
数据集
+关注
关注
4文章
1240浏览量
26262 -
英伟达
+关注
关注
23文章
4116浏览量
99645
发布评论请先 登录
相关推荐
热点推荐
Flex推出适用于英伟达Omniverse DSX Blueprint的全新参考设计
Flex(纳斯达克股票代码:FLEX)今日宣布推出适用于英伟达Omniverse DSX Blueprint的全新参考设计,以加速千兆级AI工厂的部署。这些预制模块化设计基于Flex的
硅光成AI胜负手?英伟达20亿美元战略投资Marvell
纳入英伟达 AI 生态体系,并在硅光子技术领域展开深度合作,旨在帮助客户更高效地搭建 AI 算力基础设施。 构建 “异构计算” 新范式 根据双方签署的战略协议,此次合作的核心围绕NVLink Fusion——
新思科技与英伟达多项硬核科技成果亮相GTC 2026
新思科技(Synopsys, Inc.,纳斯达克股票代码:SNPS)在英伟达 GTC 2026 大会(NVIDIA GTC 2026)上,展示了其与英伟
RAG(检索增强生成)原理与实践
引言
在大语言模型(LLM)蓬勃发展的今天,如何让AI更准确地回答特定领域的问题成为了一个关键挑战。RAG(Retrieval-Augmented Generation,检索增强生成)
发表于 02-11 12:46
什么是大模型,智能体...?大模型100问,快速全面了解!
一、概念篇1.什么是大模型?大模型是指参数规模巨大(通常达到数十亿甚至万亿级别)、使用海量数据训练而成的人工智能模型。2.什么是大语言模型(

迈向吉瓦级AI工厂的能源变革:英伟达Rubin平台电源架构解析
转变。英伟达(NVIDIA)推出的Rubin平台,作为Blackwell架构的继任者,不仅是算力密度的又一次飞跃,更是对数据中心能源基础设施的一次极限挑战。

黄仁勋:未来十年很多汽车是自动驾驶 英伟达发布Alpamayo汽车大模型平台
最看好的AI落地场景就是自动驾驶。在演讲中黄仁勋提到,未来十年,世界上很大一部分汽车将是自动驾驶或高度自动驾驶的。你期待吗? 英伟达发布Alpamayo汽车大模型平台 英伟
NVIDIA新闻:英伟达10亿美元入股诺基亚 英伟达推出全新量子设备
研发并推出相关产品。 英伟达CEO黄仁勋出现在美国华盛顿的GTC DC大会上的演讲中表示;“今天我们宣布与诺基亚建立了合作关系,诺基亚是世界第二大电信制造商,这是一个价值3万亿美元的产业。”黄仁勋说,全世界有数百万个基站,双方合
英伟达与意法半导体合作实现数据中心领域重要突破
近期,英伟达(NVIDIA)已完成对意法半导体(ST)12kW配电概念验证板的设计验证测试,这一成果标志着该项目正式迈入生产验证测试阶段。
基于米尔瑞芯微RK3576开发板的Qwen2-VL-3B模型NPU多模态部署评测
模型(如 Qwen2-VL-2B)进行专项优化,token 生成速度达 10+每秒,适配本地化多模态交互需求;
算力分配:RK3576 的 NPU 集成 512KB 共享内存,减少数据
发表于 08-29 18:08
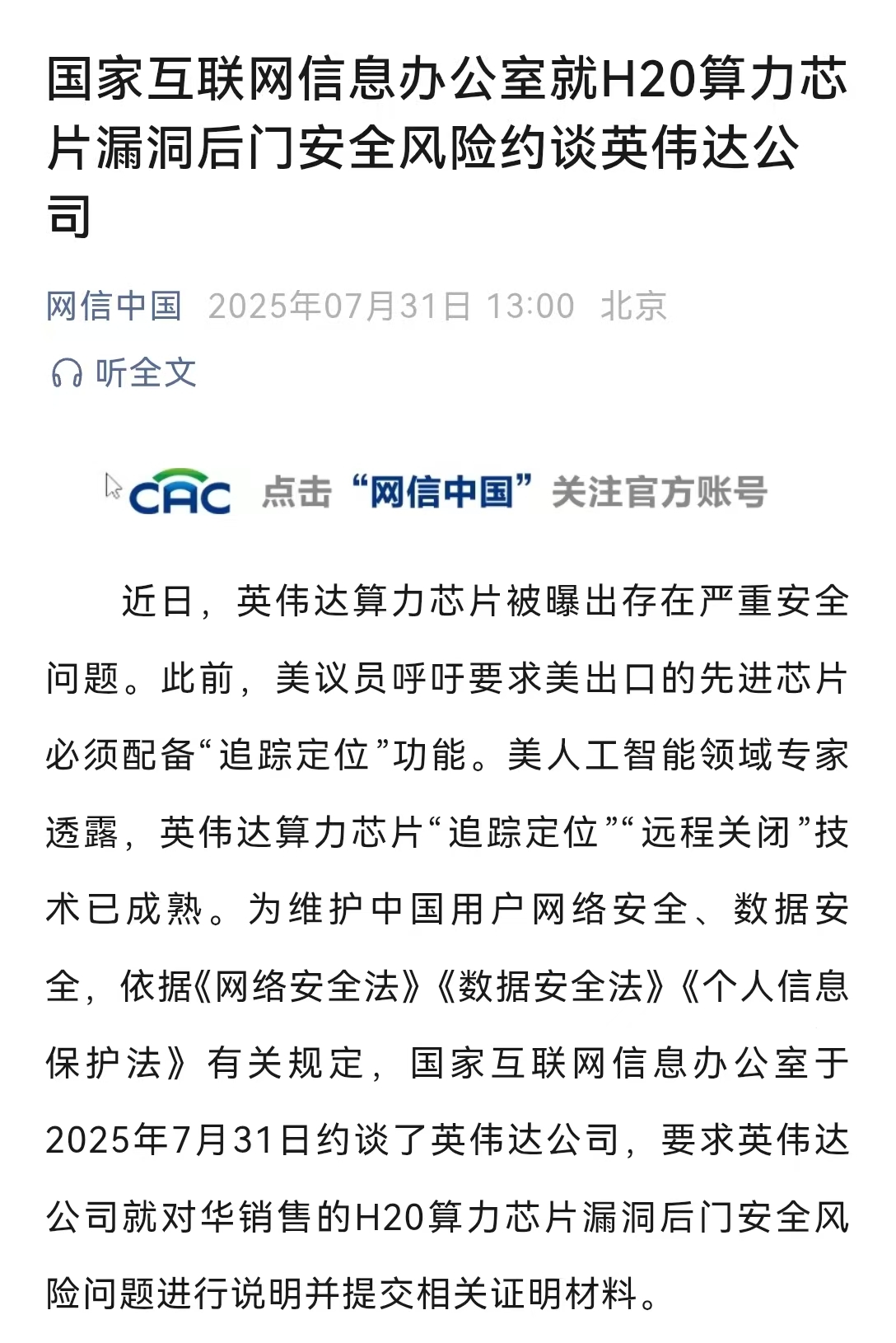
国家网信办约谈英伟达
近日,英伟达算力芯片被曝出存在严重安全问题。此前,美议员呼吁要求美出口的先进芯片必须配备“追踪定位”功能。美人工智能领域专家透露,英伟达算力
摆脱依赖英伟达!OpenAI首次转向使用谷歌芯片
地使用非英伟达芯片,更显示出其正在逐步摆脱对英伟达芯片的深度依赖,在算力布局上迈出了重要战略调整的一步。 OpenAI 依赖英伟
使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践
针对基于 Diffusion 和 LLM 类别的 TTS 模型,NVIDIA Triton 和 TensorRT-LLM 方案能显著提升推理速度。在单张 NVIDIA Ada Lovelace

芯华章携手EDA国创中心推出数字芯片验证大模型ChatDV
面向国家在集成电路EDA领域的重大需求,芯华章携手全国首家集成电路设计领域国家级创新中心——EDA国创中心,针对日益突出的芯片设计验证痛点,强强联手,共同推出具有完全自主知识产权的基于



评论