 Groq LPU崛起,AI芯片主战场从训练转向推理
Groq LPU崛起,AI芯片主战场从训练转向推理
前言: 人工智能推理的重要性日益凸显,高效运行端侧大模型及AI软件背后的核心技术正是推理。不久的未来,全球芯片制造商的主要市场将全面转向人工智能推理领域。
Groq LPU崛起,AI芯片主战场转向
与AI训练相比,AI推理与用户终端场景需求更为紧密,训练后的大规模模型需通过AI推理实际应用到场景中。
然而,目前基于英伟达GPU的AI推理方案成本较高,性能和时延问题影响了用户体验。
在Groq LPU亮相之前,大型AI模型的训练和推理均依赖于英伟达GPU,并采用CUDA软件技术栈。
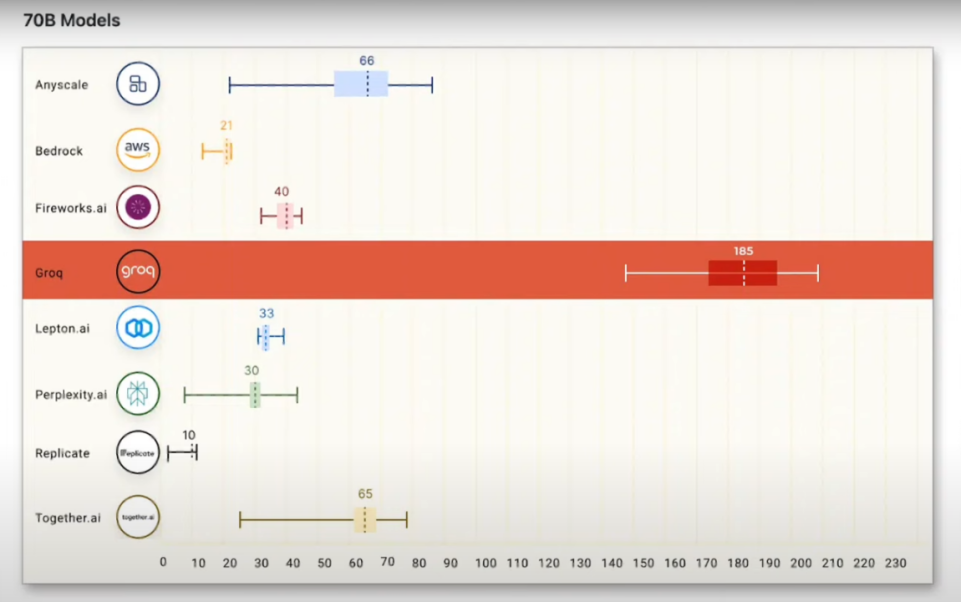
然而,Groq LPU的迅速崛起使市场开始猜测AI芯片的主战场或将从训练转向推理。
Groq LPU推理卡从硬件层面解决了性能和成本问题,使AI推理大规模部署成为可能,推动更多AI推理类应用落地。
与此同时,AI推理需求的增长将进一步推动云端推理芯片的发展,尤其是更多可替代英伟达GPU的新一代专用推理芯片将应用于数据中心。
在推理阶段,AI模型需以极致速度运行,旨在为终端用户提供更多的Token,从而加快响应用户指令的速度。
需求带动,重心从训练转向推理
AI推理领域与大规模消费电子等应用终端需求紧密相关,因此,行业发展重心有望从[训练]全面转向[推理]。
相较于AI训练,推理领域在[海量数据轰炸]应用背景下的GPU并行化算力需求远低于训练领域。
推理进程涉及已训练模型的决策或识别,擅长处理复杂逻辑任务和控制流任务的以CPU为核心的中央处理器足以高效应对诸多推理场景。
当前,AI市场主要集中在使用大数据训练大语言模型的[训练]阶段,英伟达成为这一领域的主要受益者。
然而,随着AI大模型变得更精简、可在设备上运行并专注于推理任务,芯片制造商的市场重心将转向[推理],即模型应用。
展望产业发展趋势,AI算力负载有望逐步从训练向推理端迁移,从而降低AI芯片门槛。
覆盖可穿戴设备、电动汽车及物联网等领域的芯片公司有望全面渗透至AI推理芯片领域。
预计数据中心也将对专门用于已训练模型推理任务的处理器产生兴趣,共同推动推理市场规模超越训练市场。
预计在一到两年内,AI大模型在训练端和推理端都将产生巨量的算力/AI芯片需求。
如果未来大模型广泛商用落地,推理端的算力/AI芯片的需求量将明显高于训练端。
经过两到三年的AI训练用数据中心升级周期后,市场将看到更多来自推理芯片供应商的销量。
AI推理渐多,企业与资本也向推理转移
AMD CEO苏姿丰认为:未来大模型推理市场的规模将远远大于模型训练市场。
英特尔CEO基辛格表示:当推理发生时,就不存在CUDA依赖性了,并不是说英特尔不会在训练领域展开竞争,而是从根本上说,推理市场才是竞争的焦点。
扎克伯格认为:很明显,下一代服务需要构建全面的通用智能、构建最好的AI助手、为企业创造者以及更多要在AI各个领域取得进步——从推理到规划到编码到记忆和其他认知能力。
伴随着企业AI应用逐步成熟,企业将把更多算力从模型训练转移到AI推理工作中。
在芯片需求方面,训练芯片注重通用性,而推理芯片则与已训练完成的大模型具有高度绑定性。
随着大模型应用的不断深化,推理需求也逐渐从云端迁移至边缘/终端,并呈现出定制化的发展趋势。
在全球AI芯片市场,先推理后训练成为主流路径,例如英特尔收购的AI芯片公司Habana以及我国诸多AI初创公司。
这一选择背后,是下游市场的催化作用:随着AI模型训练逐渐成熟,AI应用逐步落地,云端推理市场已逐渐超过训练市场。
人工智能计算资源正由训练大规模AI模型逐步转向推理,因此在客户端、边缘和云之间需要构建更为均衡的基础设施。
据估计,全球已有超过18家致力于AI大模型训练和推理的芯片设计初创公司,累计获得超过60亿美元融资,整体估值超过250亿美元。
这些创业公司得到了诸如红杉资本、OpenAI、五源资本、字节跳动等强大投资方的支持。
同时,微软、英特尔、AMD等科技巨头也在加大[造芯]力度,使得英伟达面临前所未有的竞争压力。
与英伟达竞速,各企业从细分领域突破
为降低模型训练与推理成本,业界持续探索实现高能效和高性能芯片架构的更多可能性。
观察诸如Meta、亚马逊、Alphabet等科技巨头,它们均在研发自家的AI芯片。
这些芯片更具专业性和明确目标,相较之下,英伟达的芯片则具备更高的通用性。
①AMD:最新发布的MI300包括两大系列,MI300X系列是一款大型GPU,拥有领先的生成式AI所需的内存带宽和大语言模型所需的训练和推理性能;
MI300A系列集成CPU+GPU,基于最新的CDNA3架构和Zen4 CPU,可以为HPC和AI工作负载提供突破性能。
去年12月,AMD在推出旗舰MI300X加速卡之外,还宣布Instinct MI300A APU已进入量产阶段,预估今年开始交付,上市后有望成为世界上最快的HPC解决方案。
去年7月,英特尔公司在北京发布了一款针对中国市场、采用7纳米工艺的AI芯片Habana Gaudi2,该芯片可运行大语言模型,加速AI训练及推理。
其运行ResNet-50的每瓦性能约为英伟达A100的2倍,性价比相较于AWS云中基于英伟达的解决方案高出40%。
②英特尔:宣布与Arm公司合作,使其至强产品部署到Arm CPU上,并推出AI推理和部署运行工具套件OpenVINO。
此外,开源模型如LIama2陆续发布,促使更多企业直接使用这些模型,仅需AI推理芯片即可应用,从而减少了对算力训练芯片的需求。
英特尔去年年底推出了新的计算机芯片,其中包括用于生成人工智能软件的人工智能芯片Gaudi3。
Gaudi3将于今年推出,将与英伟达和AMD等竞争对手的芯片竞争,为大型且耗电的人工智能模型提供动力。
③Meta:计划在今年投产自研芯片,降低AI加速卡采购成本,减少对英伟达的依赖。
该芯片功耗仅25瓦,为英伟达相同产品功耗的0.05%,并采用RISC-V开源架构。市场消息透露,该芯片由台积电7纳米工艺生产。
Meta近期宣布已构建自有DLRM推理芯片,并已广泛部署。
这款ASIC内部被称为[Artemis],主要性能集中在推理领域,基于去年宣布的第二代内部芯片产品线。
扎克伯格在视频中透露了Meta人工智能计划的更新路线图:Meta将围绕即将推出的Llama3构建全新的Meta AI路线图,目前正在推进Llama3的AI训练。
Llama3将与Google最近发布的Gemini模型、OpenAI的GPT-4,以及即将推出的GPT-5模型竞争。
④英伟达:去年8月,英伟达宣布推出新一代GH200 Grace Hopper超级芯片,新芯片将于今年第二季投产。
GH200和GH200NVL将采用基于Arm的CPU和Hopper解决大型语言模型的训练和推理问题。
英伟达计划基于x86架构推出B100替代H200,并基于ARM架构的推理芯片GB200替代GH200。
此外,英伟达还规划了B40产品来替代L40S,以提供更好的面向企业客户的AI推理解决方案。
根据英伟达计划于今年发布Blackwell架构,采用该架构的B100 GPU芯片预计将大幅提高处理能力。
初步评估数据表明,与现有采用Hopper架构的H200系列相比,性能提升超过100%。
⑤亚马逊:去年初,AWS发布专为人工智能打造的Inferentia2(Inf2),计算性能提高三倍,加速器总内存提高25%,支持分布式推理。
通过芯片之间的直接超高速连接,Inf2支持分布式推理,可以处理多达1750亿个参数,使其成为当今人工智能芯片市场上最强大的内部制造商。
单点突破有收获,国产有望追平
与此同时,我国华为、天数智芯等AI芯片制造商也在积极布局大模型训练推理及AI算力产品。
当前,我国厂商如寒武纪、燧原、昆仑芯等的产品已具备与市场主流的Tesla T4正面竞争的实力:其能效比为1.71TOPS/W,与T4的1.86TOPS/W差距微小。
选择GPGPU的登临科技、天数智芯、燧原科技已实现训练与推理的全面覆盖,而ASIC类芯片如平头哥,则需专注于推理或训练场景。
①亿铸科技:基于CIM框架、RRAM存储介质的研发的[全数字存算一体]大算力芯片,通过降低数据搬运提高运算能效比,同时借助数字存算一体方法确保运算精度,适用于云端AI推理和边缘计算。
②寒武纪:思元370作为寒武纪第三代云端产品,运用7纳米制程工艺,成为我国首款采用Chiplet技术的AI芯片,其最大算力可达256TOPS(INT8)。
寒武纪主要采用ASIC架构,虽通用性较差,但在特定应用场景下,其算力可超越GPU。
有测试结果显示,590性能接近A100的90%性能;590基本支持主流模型,综合性能接近A100的80%水平。
此外,思元370也是寒武纪首款采用Chiplet技术的AI芯片,集成了390亿个晶体管,最大算力高达256TOPS(INT8)。
③平头哥:去年8月,平头哥发布首个自研RISC-V AI平台,支持运行170余个主流AI模型,推动RISC-V进入高性能AI应用时代。
同时,平头哥宣布玄铁处理器C920全新升级,C920执行GEMM计算较Vector方案可提速15倍。
④壁仞科技:其BR100系列基于自主原创的芯片架构开发,采用成熟的7纳米工艺制程,集成770亿晶体管,16位浮点算力达到1000T以上、8位定点算力达到2000T以上,单芯片峰值算力达到PFLOPS级别。
同时,BR100结合了包括Chiplet等在内的多项业内前沿芯片设计、制造与封装技术,具有高算力、高能效、高通用性等优势。
⑤燧原科技:成立5年多来,已建成云端训练和云端推理两条产品线,并开发出云燧T10、云燧T20/T21训练产品以及云燧i10、云燧i20等推理产品。
据媒体报道,燧原科技第三代AI芯片产品将于今年初上市。
⑥华为:昇腾310是面向推理和边缘计算场景的低功耗芯片,是国内面向边缘计算场景最强算力的AI SoC。
昇腾310芯片可以实现高达16Tops的现场算力,支持同时识别包括车、人、障碍物、交通标志在内的200个不同的物体;一秒钟内可处理上千张图片。
华为昇腾系列AI芯片具备一项独特优势,即采用了华为自主研发的统一且可扩展的架构。
这一架构实现了从极低功耗到极高算力场景的全覆盖,使得一次开发即可适用于所有场景的部署、迁移及协同,从而显著提升了软件开发效率。
结尾:
随着大模型在各类场景中的应用日益广泛,推理环节的重要性日益凸显。
因此,我们需要关注推理芯片的计算需求和系统配置,以降低成本、提升易用性,进而促进大模型在各个领域的迅速普及。
审核编辑:刘清
-
人工智能
+关注
关注
1796文章
47643浏览量
239921 -
中央处理器
+关注
关注
1文章
125浏览量
16569 -
AI芯片
+关注
关注
17文章
1904浏览量
35184 -
OpenAI
+关注
关注
9文章
1123浏览量
6660 -
大模型
+关注
关注
2文章
2544浏览量
3068
原文标题:深度丨AI芯片主战场:从训练转向推理?
文章出处:【微信号:World_2078,微信公众号:AI芯天下】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
刷屏的Groq芯片,速度远超英伟达GPU!成本却遭质疑
生成式AI推理技术、市场与未来

亚马逊转向Trainium芯片,全力投入AI模型训练
AI推理CPU当道,Arm驱动高效引擎

FPGA和ASIC在大模型推理加速中的应用

NVIDIA助力丽蟾科技打造AI训练与推理加速解决方案

沙特阿美携手Groq打造全球最大推理数据中心
AMD助力HyperAccel开发全新AI推理服务器

苹果承认使用谷歌芯片来训练AI
AI推理,和训练有什么不同?

开发者手机 AI - 目标识别 demo
英伟达要小心了!爆火的Groq芯片能翻盘吗?AI推理速度「吊打」英伟达?
Groq收购Definitive intelligence,提升云平台能力
Groq推出大模型推理芯片 超越了传统GPU和谷歌TPU





 工商网监
工商网监
评论