 LLM中的大规模激活
LLM中的大规模激活

Massive Activations in Large Language Models摘要:我们在大型语言模型(LLM)中观察到一种经验现象-很少有激活表现出比其他激活大得多的值(例如,100,000倍)。我们称之为大规模激活。首先,我们证明了广泛存在的大规模激活在各种LLM和表征他们的位置。其次,我们发现它们的值在很大程度上保持不变,无论输入,它们作为不可或缺的偏置项在LLM中。第三,这些大规模的激活导致注意概率集中到它们相应的标记上,并进一步导致自我注意输出中的隐式偏差项。最后,我们还研究了Vision Transformers中的大规模激活。
https://arxiv.org/abs/2402.17762
Q1: 这篇论文试图解决什么问题?
A: 这篇论文主要研究了大型语言模型(LLMs)中的一个现象,即在模型的隐藏状态中存在极少数激活值(activations)远大于其他激活值的情况,这些被称为“massive activations”。论文试图解决的问题包括:
1.现象的普遍性:作者首先展示了这种massive activations在不同LLMs中的普遍存在,并对其进行了特征定位。
2.功能角色:研究这些massive activations在LLMs中的功能角色,即它们是否对模型性能有实质性影响,还是仅仅是无关紧要的异常值。
3.与自注意力机制的关联:探讨massive activations与自注意力机制之间的关系,以及它们如何影响模型的注意力分布。
4.作为固定偏差的作用:分析massive activations如何在LLMs中充当固定但重要的偏差项,并探究这种偏差对模型性能的影响。
5.在视觉变换器(Vision Transformers, ViTs)中的应用:将研究扩展到ViTs,观察是否也存在类似的massive activations现象,并分析其在ViTs中的作用。
6.消除massive activations的可能性:通过实验,作者探索了通过在自注意力中显式引入偏差项来消除massive activations的可能性。
总的来说,这篇论文试图深入理解LLMs内部表示中massive activations的本质、功能和影响,以及它们如何与模型的自注意力机制相互作用。这些发现有助于我们更好地理解大型模型的内部工作机制,可能对改进模型设计和训练方法具有重要意义。
Q2: 有哪些相关研究?
A: 论文中提到了与massive activations现象相关的一些研究领域和具体工作,包括:
自回归Transformers的有趣属性:
Timkey和Schijndel (2021) 观察到GPT-2的倒数第二层中存在特征维度,其激活值高达3000,这些维度在评估表示相似性的标准度量中占主导地位。
Heimersheim和Turner (2023) 发现GPT-2中初始token的特征范数比其他token增长得更快。
Kovaleva等人 (2021) 和 Zhao等人 (2023) 展示了GPT-2和LLaMA2-13B中LayerNorm的异常权重的存在,并表明将它们设置为零会导致模型性能的灾难性下降。
异常特征(Outlier Features):
Dettmers等人 (2022) 展示了LLMs中异常特征的存在,这些特征在大多数序列维度中具有较大的激活值。尽管massive activations和异常特征在表面上看似相似,但论文中讨论了它们的根本区别,并表明massive activations不能归因于异常特征的存在。
注意力集中模式(Attention Concentration Patterns):
Clark等人 (2019b)、Kovaleva等人 (2019) 和 Bondarenko等人 (2021) 发现BERT中的注意力倾向于集中在“separate”token [SEP]上。
Xiao等人 (2023b) 展示了LLMs将大部分注意力分配给起始词token。
Darcet等人 (2023) 揭示了ViTs中注意力的异常现象。
Robinson等人 (2023) 发现ViTs中的稀疏激活模式,这些模式将注意力吸引到特定token上。
自注意力中的偏差(Biases in Self-Attention):
Namazifar等人 (2023) 提出了在自注意力的线性层中使用简单的加性偏差项。
Su等人 (2021) 和 Press等人 (2021) 引入了位置偏差来编码每个token的位置信息。
Evan (2023) 和 Bondarenko等人 (2023) 提出了具有手动设计的softmax操作符的偏差变体。
Vision Transformers(ViTs)中的massive activations:
Darcet等人 (2023) 提出了在标准ViTs中引入额外的可学习token(称为register tokens),并展示了训练带有register tokens的ViTs可以导致平滑的注意力图,从而提高了下游任务的性能。
这些相关研究为理解LLMs和ViTs的内部机制提供了背景知识,并且与本文研究的massive activations现象有着直接或间接的联系。
Q3: 论文如何解决这个问题?
A: 论文通过以下步骤来解决大型语言模型(LLMs)中massive activations的问题:
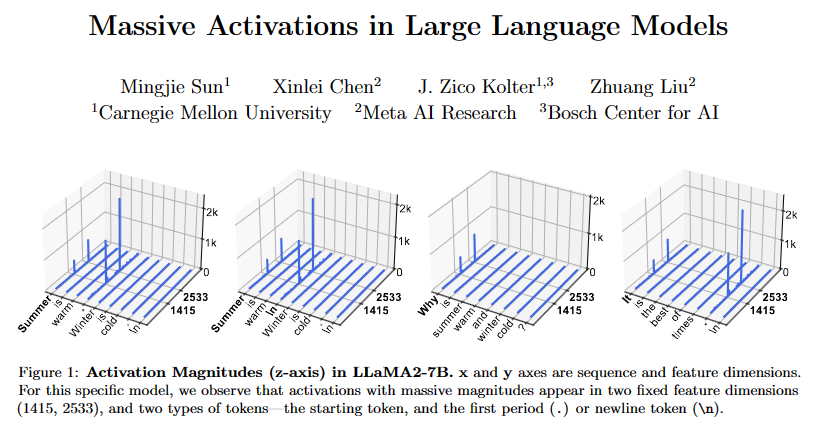
现象观察:首先,作者在不同的LLMs中观察并确认了massive activations的普遍存在。他们通过可视化技术展示了这些激活值在特定特征维度上的异常高值。
特征定位:作者确定了massive activations在模型的哪些层和特征维度上出现,以及它们与序列中的哪些token相关联。他们发现这些激活通常出现在模型的起始token和分隔符token(如句点或换行符)。
功能分析:通过干预实验(例如,将massive activations设置为零或其均值),作者分析了这些激活对模型性能的影响。他们发现,massive activations对模型性能至关重要,且其值在输入变化时保持相对恒定,类似于固定偏差。
自注意力机制的深入研究:作者探讨了massive activations如何影响自注意力机制,特别是它们如何导致注意力集中在与这些激活相关的token上。他们通过分解注意力输出来展示这些token如何作为隐含的注意力偏差项。
显式偏差的引入:为了消除massive activations,作者尝试在自注意力中显式引入偏差项。他们通过实验发现,当在自注意力中添加额外的键(key)和值(value)嵌入作为显式偏差时,模型不再需要学习massive activations。
视觉变换器(ViTs)的扩展研究:作者还将研究扩展到ViTs,观察这些模型是否也存在类似的massive activations现象,并分析它们在ViTs中的作用。他们发现ViTs中的某些模型也表现出massive activations,并且这些激活在功能上类似于LLMs中的massive activations。
替代方法的探索:作者还探索了其他可能的方法来引入自注意力中的偏差,例如通过修改softmax操作符或添加额外的特征维度。
通过这些步骤,论文不仅揭示了massive activations在LLMs中的作用,还提出了可能的解决方案来调整或消除这些激活,从而可能改善模型的训练和性能。
Q4: 论文做了哪些实验?
A: 论文中进行了一系列实验来研究大型语言模型(LLMs)中的massive activations现象,以及它们在模型中的作用和影响。以下是主要的实验内容:
存在性验证:作者在多个LLMs中观察massive activations,包括LLaMA2-7B、LLaMA2-13B和Mixtral-8x7B等,通过可视化技术展示了这些激活在特定特征维度上的异常高值。
位置和特性分析:对于LLaMA2-7B模型,作者分析了massive activations在不同层和特征维度上的位置,以及它们与序列中特定token(如起始token和句点token)的关系。
干预实验:作者通过将massive activations设置为零或其均值,来评估这些激活对模型性能的影响。实验结果表明,massive activations对模型性能至关重要。
自注意力分析:作者研究了massive activations如何影响自注意力机制,特别是它们如何导致注意力集中在与这些激活相关的token上。他们通过分析注意力logits和注意力概率来展示这一点。
显式偏差引入实验:为了消除massive activations,作者尝试在自注意力中引入显式偏差项。他们训练了GPT-2模型,并在自注意力中添加了额外的键(key)和值(value)嵌入作为显式偏差。实验结果显示,这种方法可以消除massive activations。
Vision Transformers(ViTs)的实验:作者在ViTs中也观察到了massive activations现象,并分析了它们在ViTs中的作用。他们研究了CLIP、MAE和DINOv2等模型,并探讨了register tokens在ViTs中的功能。
替代方法的探索:作者探索了其他可能的方法来引入自注意力中的偏差,例如通过修改softmax操作符或添加额外的特征维度,并评估了这些方法对massive activations的影响。
这些实验不仅帮助作者深入理解了massive activations在LLMs中的作用,还为如何调整或消除这些激活提供了实验依据。通过这些实验,作者能够提出新的见解和可能的改进方向。
Q5: 有什么可以进一步探索的点?
A: 论文中提出了一些可以进一步探索的点,包括但不限于:
massive activations的深入理解:
研究massive activations在不同类型和大小的LLMs中的普遍性和差异性。
探索massive activations在模型训练过程中的动态变化,以及它们如何影响模型的学习过程。
massive activations与模型性能的关系:
分析massive activations对模型泛化能力、鲁棒性和可解释性的具体影响。
研究在不同的下游任务中,massive activations的作用和重要性。
自注意力机制的改进:
设计新的自注意力机制,以减少或消除对massive activations的依赖。
探索其他类型的显式偏差项,以替代或增强massive activations的功能。
ViTs中的massive activations:
在更广泛的ViTs模型和任务中研究massive activations现象。
分析register tokens在ViTs中的作用,以及它们与massive activations的关系。
模型压缩和优化:
研究如何利用对massive activations的理解来优化模型的压缩和加速。
探索在模型部署时,如何有效地处理massive activations以提高效率。
理论分析:
从理论角度分析massive activations的存在对模型表示能力的影响。
研究massive activations在模型的优化过程中所扮演的角色。
跨领域应用:
将对massive activations的研究扩展到其他类型的深度学习模型,如强化学习模型、序列生成模型等。
探索massive activations在多模态学习(如图像和文本联合处理)中的应用。
伦理和社会影响:
研究massive activations可能对模型的公平性、透明度和可解释性带来的影响。
探讨如何在设计和部署LLMs时考虑到这些因素,以促进负责任的AI发展。
这些探索点不仅有助于提升我们对LLMs和ViTs内部机制的理解,还可能对模型设计、训练策略和实际应用产生重要影响。
Q6: 总结一下论文的主要内容
A: 这篇论文主要研究了大型语言模型(LLMs)中的一个现象,即在模型的隐藏状态中存在极少数激活值(activations)远大于其他激活值的情况,这些被称为“massive activations”。以下是论文的主要内容总结:
现象观察:作者在多个LLMs中观察到massive activations的存在,这些激活值在特定的特征维度上显著高于其他激活值,且数量极少。
位置和特性分析:通过分析,作者发现massive activations通常出现在模型的起始token和分隔符token(如句点或换行符)上,且在模型的不同层中表现出不同的分布特征。
功能角色:实验表明,massive activations在LLMs中扮演着类似固定偏差的角色,对模型性能至关重要。将它们设置为零会导致模型性能显著下降,而将它们设置为均值则对性能影响不大。
与自注意力的关联:作者发现massive activations与自注意力机制密切相关,它们导致注意力集中在相关token上,并在自注意力输出中形成隐含的偏差项。
显式偏差的引入:通过在自注意力中引入显式偏差项,作者展示了可以消除massive activations的需要,这表明massive activations可能是在预训练阶段学习隐含偏差的一种方式。
Vision Transformers(ViTs)中的研究:作者还将研究扩展到ViTs,发现在ViTs中也存在类似的massive activations现象,这些激活在功能上类似于LLMs中的massive activations。
未来工作:论文提出了一些未来研究方向,包括更深入地理解massive activations在模型中的作用,探索如何在模型设计中利用或消除这些激活,以及它们在不同类型模型中的应用。
总的来说,这篇论文揭示了LLMs中massive activations的普遍性和重要性,以及它们如何影响模型的内部机制和性能。这些发现对于理解和改进大型模型的设计具有重要意义。
审核编辑:黄飞
-
大模型
+关注
关注
2文章
3857浏览量
5289
原文标题:每日论文速递 | LLM中的大规模激活
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Veloce平台在大规模SOC仿真验证中的应用
大规模集成电路在信息系统中的广泛应用
大规模天线技术商用测试
大规模MIMO的利弊
大规模MIMO的性能
大规模FPGA设计中的多点综合技术
什么是LLM?LLM在自然语言处理中的应用
大规模专家并行模型在TensorRT-LLM的设计

TensorRT-LLM的大规模专家并行架构设计




评论