 基于视觉的动态手势识别的ResNeXt网络详解
基于视觉的动态手势识别的ResNeXt网络详解

01
ResNeXt网络详解
一、ResNeXt—VGG、ResNeXt、Inception的结合体
ResNeXt网络可以看作基于VGG、ResNeXt和Inception的一个经典神经网络结构,目前已经被广泛应用于各种视觉任务。它结合了以上三种网络的特点:
堆叠多个重复的block(基于VGG)
每个block中包含了多种变换(基于Inception)
使用残差进行跨层连接(基于ResNet)
1、VGG
VGG是基于AlexNet进行改进得到的网络模型结构。AlexNet使用如11*11、7*7、5*5等较大卷积核,而VGG则采用连续的3*3卷积核进行堆叠。在VGG中,使用3个3*3的卷积核代替7*7的卷积核,使用2个3*3卷积核代替5*5的卷积核,在保证相同感知野的前提下,增加网络深度来处理较为复杂的问题。同时,较小卷积核的引入也降低了参数量。VGG16家族网络结构如图。
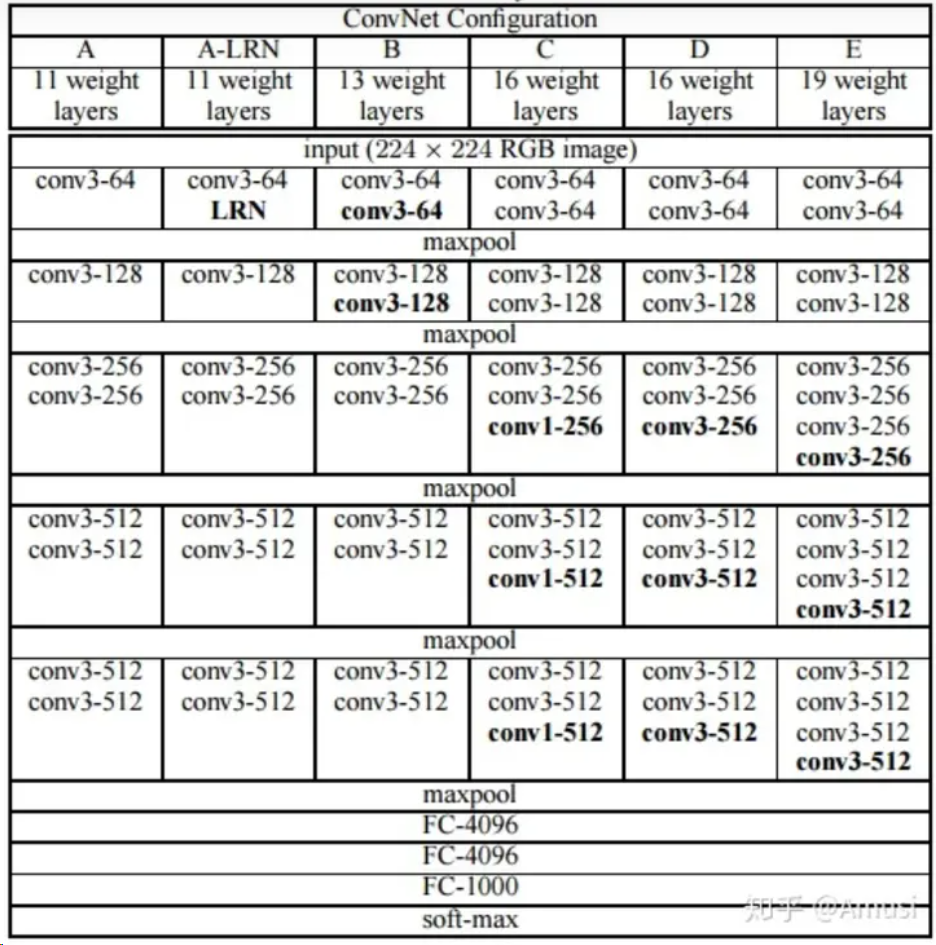
可以看到,VGG家族网络采用多个block堆叠的方式进行构建,每一个block中包含若干个3*3的卷积核,block之间使用maxpool进行下采样。
ResNeXt延续了VGG这种相同block堆叠的方式,使用ResNeXt block堆叠的方式构建ResNeXt网络。
2、Inception
对于神经网络来说,增加网络性能一般通过增加网络的深度和宽度来实现。增加深度及增加网络层数,增加宽度代表增加每一层特征图的通道数。但是一味地增加深度和宽度会导致网络的参数量过于庞大,很可能产生过拟合。有研究表明,增加网络的稀疏性可以解决以上问题,Inception正是基于此逻辑进行设计的。
Inception的核心思想是,在一层中同时使用不同尺寸的卷积核,提取不同尺寸的特征,然后再将结果通过concact进行连接。于是有了如下的Inception模块的第一版设计。
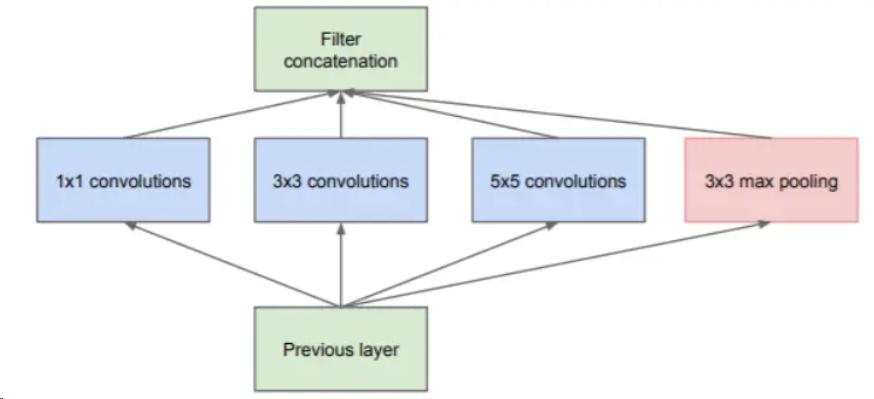
在该模块中,使用1*1、3*3、5*5三种不同尺寸大小的卷积核,和一个3*3的最大池化,增加了网络在不同尺度上的感知能力。为了减少计算资源消耗,后续对该模块进行改进,在卷积前使用1*1的卷积核对特征图进行降维,然后再对通道数减少的特征图进行卷积操作。Inception-v1最终的模块如下图。
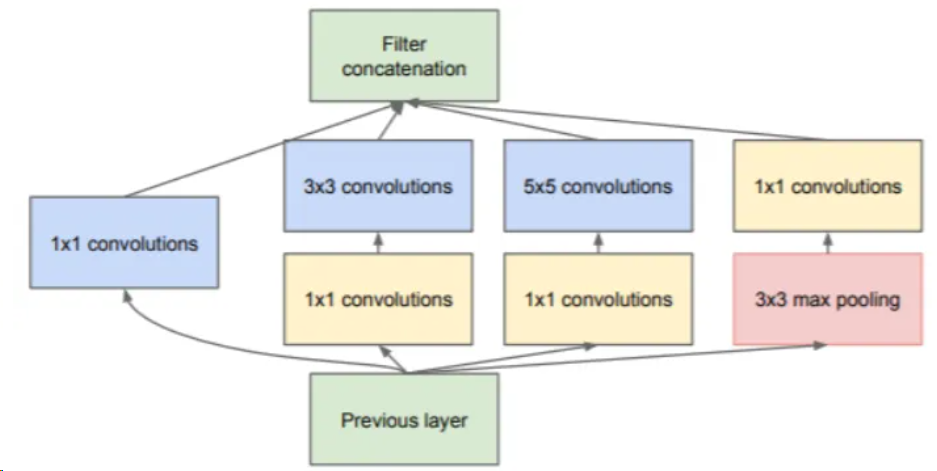
这种在一层中使用不同尺寸卷积核进行卷积的方式,被称为split-transform-merge策略。简单来说就是,针对输入先进行特征分离(split),然后分别进行不同的处理(transform),最后再将所有结果进行合并(merge)。使用这种策略构建起的网络,虽然能使用较小的参数实现较多的特征提取,但是该网络的每一个分支都需要经过精心的设计,导致模型结构复杂、泛化能力不强。
ResNeXt在设计上沿用了split-transform-merge策略,同时对该策略进行了一定程度的改进,规避了模型结构复杂这一弱点。
3、ResNet
回到顶部
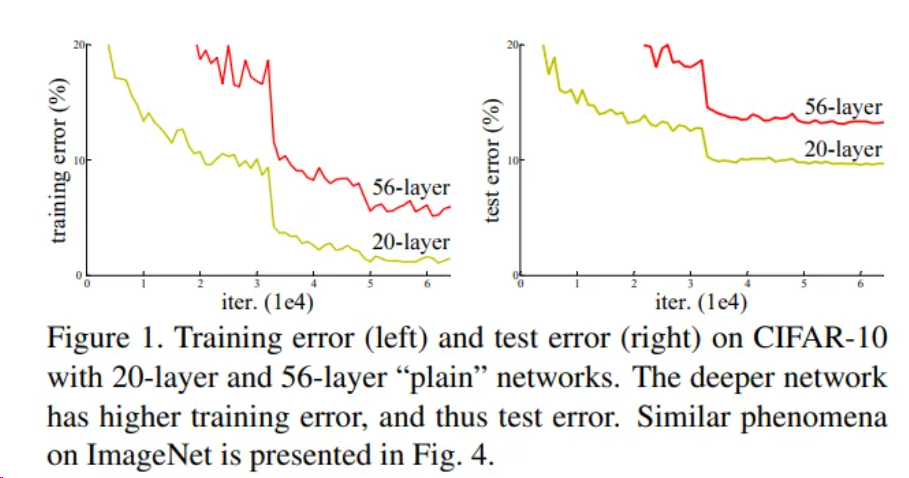
是否网络层数不断增加,模型准确率就能不断增加呢?ResNet的作者做了一个实验,实验结果表明,随着网络层数不断增加,模型准确率先是上升,之后却开始下降。也就是说,层数较多的网络效果有可能不如层数较少的网络。如图,作者在CIFAR-10数据集上进行了实验,实验结果表明,56层网络的准确率反而不如20层网络。作者将这一现象称之为模型退化,同时提出了ResNet网络以解决模型退化问题,使得神经网络的深度首次突破了100层。
ResNet的核心思想是,在每一个block中加入shortcut connection(快捷连接),如下图。在每一个ResNet块中,输入x经过一系列变换得到F(x),然后再将F(x)和x加在一起得到最终输出H(x)=F(x)+x。这种网络结构也叫做残差网络。
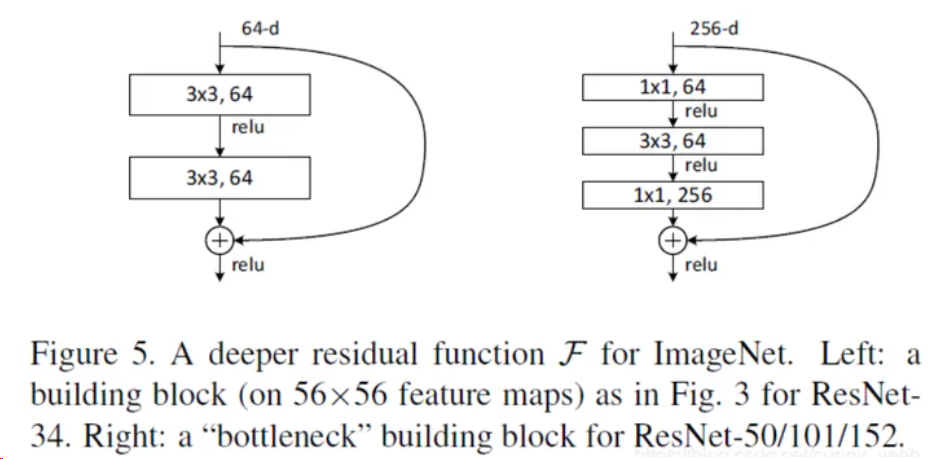
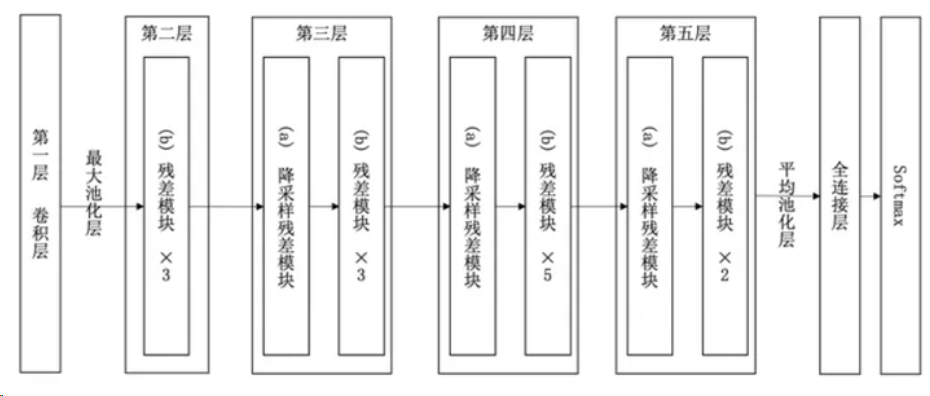
实验表明,ResNet在上百层的网络结构中也有着很好的表现。以34层ResNet为例,网络结构如下图。
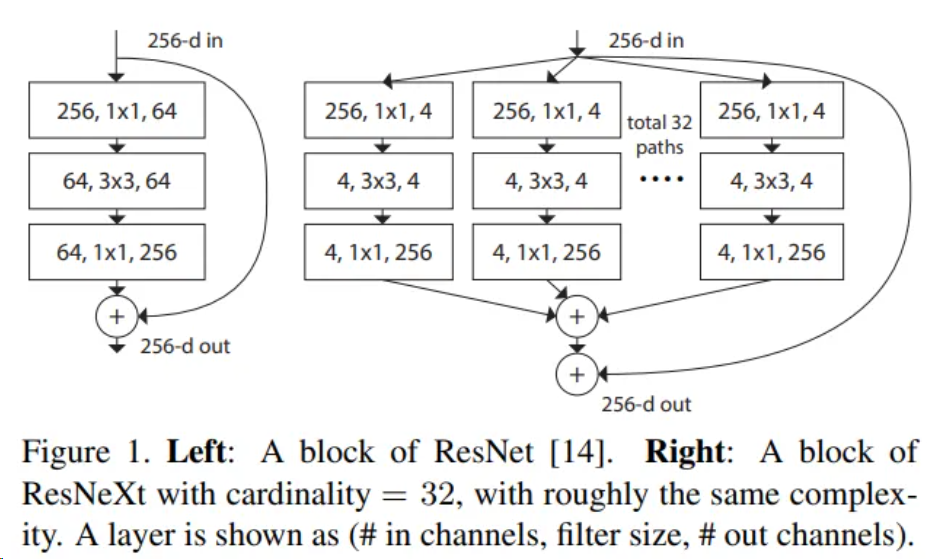
ResNeXt网络是对ResNet网络进行改造,借鉴了VGG中block堆叠的设计原则和Inception中split-transform-merge的策略并对其进行改进。ResNeXt基本结果如图所示,可以看到,该模块在ResNet模块的基础上,使用了Inception的策略,但是所有分支结构相同,简化网络结构设计。
二、ResNeXt系列网络结构
ResNeXt block一共有三种表现形式,这三种形式完全等价。
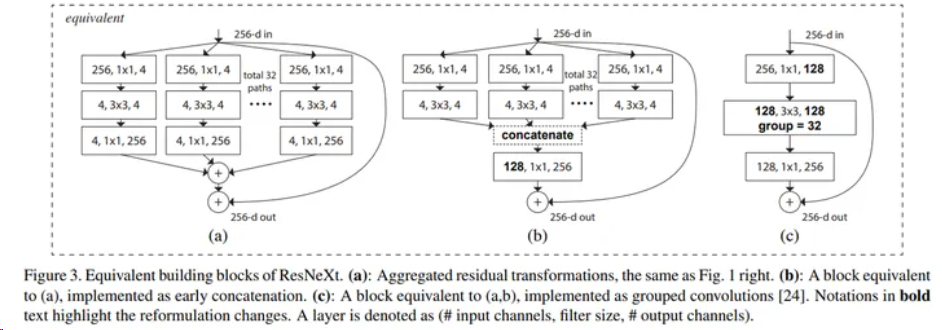
其中最基本的形式为图中的(a),一共设计了32个分支,先使用1*1的卷积核对输入特征图进行降维,然后使用3*3卷积核进行卷积操作,最后使用1*1卷积核进行升维,然后将所有分支结果相加,然后进行残差操作,再与输入相加,最终得到输出结果。
为了方便工程化实现,作者将(a)中的结构转化为(b),及先将32个分支卷积结果进行concact连接,然后使用1*1卷积进行升维,最后和输入相加得到输出。
经过研究,作者发现(b)中的结构可以使用分组卷积进行替代。及先使用1*1卷积核对输入特征图进行降维,得到128个通道的特征图,然后将128个通道分为32组,每组4个通道,使用3*3卷积核分别对每组的4个通道进行卷积操作,然后再将32组结果在通道维度进行聚合,获得最终的128通道的特征图。之后进行同样的1*1卷积升维以及残差操作,得到最终输出。
基于上述ResNeXt block构建整体网络,以ResNeXt-50为例,和ResNet-50对比如下。
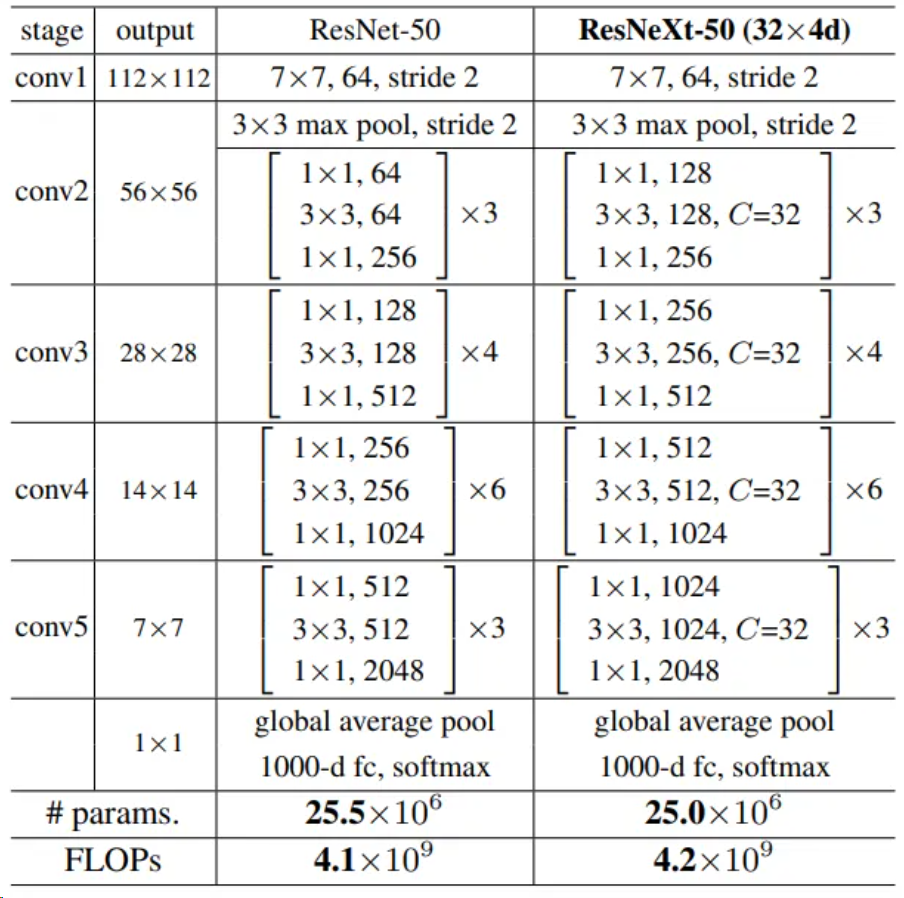
可以看到ResNeXt集合了VGG、Inception和ResNet的特点,整体结构和ResNet类似,参数量(params)和计算量(FLOPs)也与ResNet基本相等,其中网络细节如下:
conv3、conv4、conv5三个block的第一个3*3卷积核的stride=2,实现下采样功能
当feature map进行下采样操作后,通道数变为原来的2倍
每一个卷积后面附带一个Batch Normalization层和Relu激活层,BN层用于加快模型收敛速度,保证模型训练过程中的稳定性,一定程度上消除梯度消失或者梯度爆炸问题。
和ResNet一样,ResNeXt也可以进行拓展,比较常用的有ResNeXt-50、ResNeXt-101、ResNeXt-152。在下文中,将使用ResNeXt-101完成手势识别任务。
三、ResNeXt性能分析
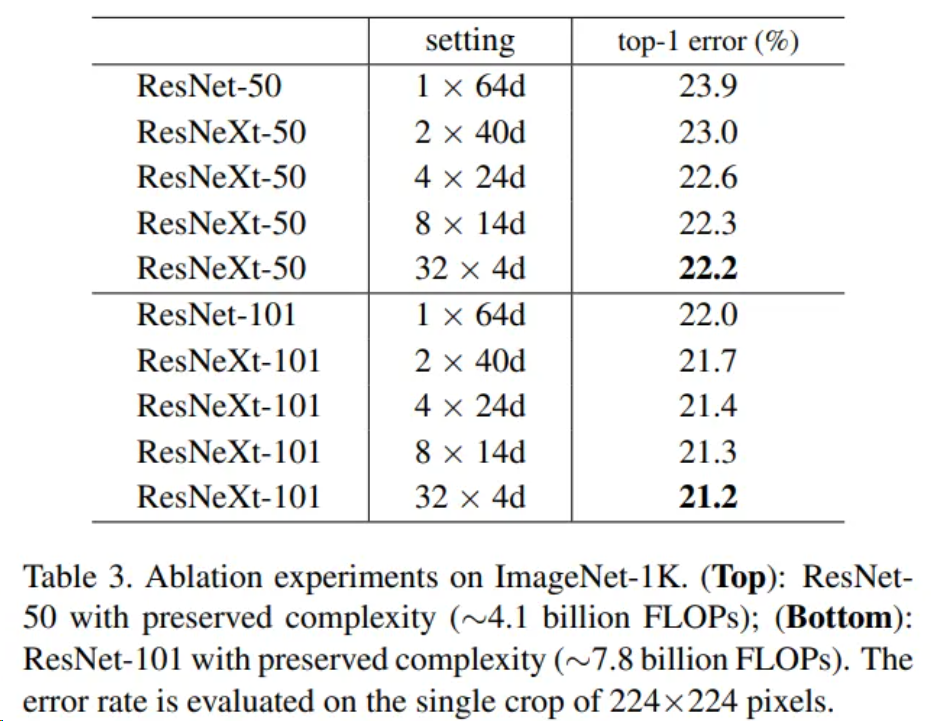
ResNeXt作者在ImageNet数据集上对不同配置的ResNeXt-50网络和ResNeXt-101的性能进行了评估,并且和同等层数的ResNet网络进行了对比,结果如下,其中setting表示conv2中3*3卷积核的配置情况,“*”前的数字表示分组数量,之后的数字表示每组通道数。如2*40d表示分2组、每组通道数为40。top-1 error为错误率。可以看到,随着分组数的增加,网络性能会逐步提高。
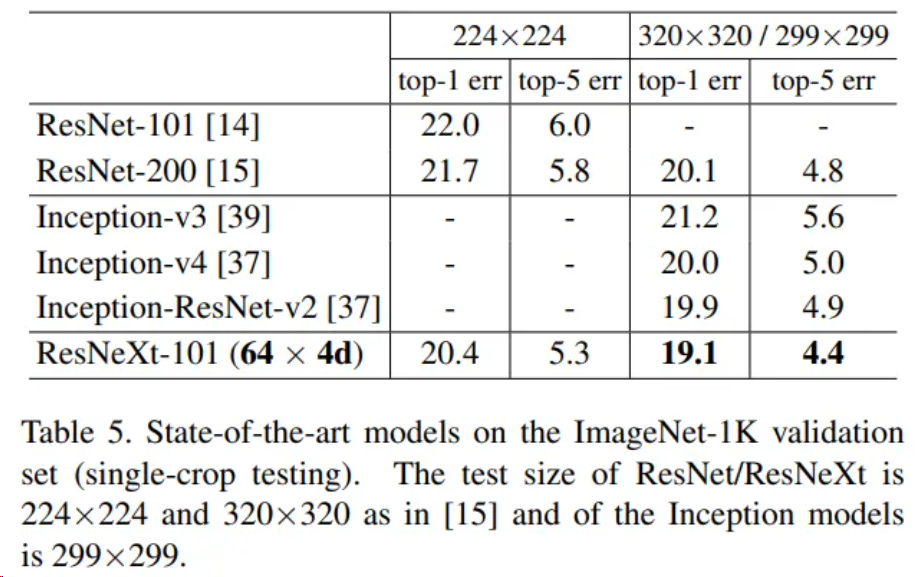
作者还将ResNeXt-101网络在ImageNet数据集上和其余网络进行了对比,包括ResNet和Inception家族中的部分网络结构,结果如图。可以看到,和这些网络相比,ResNeXt-101都表现出了更高的性能。
审核编辑:黄飞
-
神经网络
+关注
关注
42文章
4840浏览量
108142 -
网络结构
+关注
关注
0文章
48浏览量
12438 -
vgg
+关注
关注
1文章
11浏览量
5473
原文标题:基于ResNeXt网络实现基于视觉的动态手势识别 之 ResNeXt网络详解
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
基于BP神经网络的手势识别系统

基于毫米波雷达的手势识别神经网络
基于毫米波雷达的手势识别算法
ELMOS用于手势识别的光电传感器E527.16
基于BP神经网络的手势识别系统
基于肌电信号和加速度信号的动态手势识别方法

手势识别产品特性和主要应用领域





评论