 关于DPDK的一些常见问题
关于DPDK的一些常见问题
交换机、路由器、防火墙等网络设备通常需要实时处理大量数据包。在现代网络中,数据包处理是一个非常重要的环节。传统上,高效的数据包处理需要使用专门且昂贵的硬件,而数据平面开发套件 ( DPDK )能在低成本商用硬件上做到这一点。通过使用商用硬件,还可以将网络功能转移到云端,并在虚拟化环境中运行它们。
DPDK最初是由 Intel 于2010年发起的,Intel 的 Venky Venkatesan 被称为“ DPDK之父”。2017年4月,DPDK成为Linux基金会下的一个项目。目前,许多开源项目已经采用了DPDK,包括 MoonGen、mTCP、Ostinato、Lagopus、Fast Data (FD.io)、Open vSwitch、OPNFV 和 OpenStack。
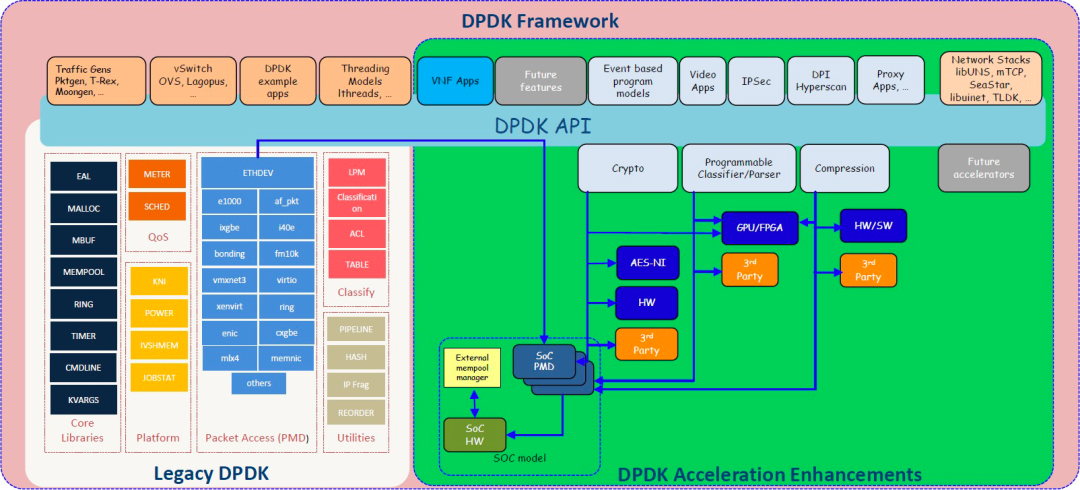
| DPDK框架 当然,DPDK也面临着一些挑战,包括无法支持某些网卡;对 Windows 的支持有限;调试比较困难;版本兼容性问题等。 01 DPDK如何改进数据包处理? 传统的数据包处理方式是数据包先到内核最后再到用户层进行处理。这种方式会增加额外的延迟和CPU开销,严重影响数据包处理的性能。 DPDK 绕过内核,在用户空间中实现快速数据包处理。它本质上是一组网络驱动程序和库。环境抽象层 ( EAL ) 从应用程序中抽象出特定于硬件的操作。下图显示了在数据包到达应用程序之前,POSIX调用的传统处理是如何通过内核空间的。DPDK缩短了这条路径,并直接在NIC和用户空间应用程序之间移动数据包。
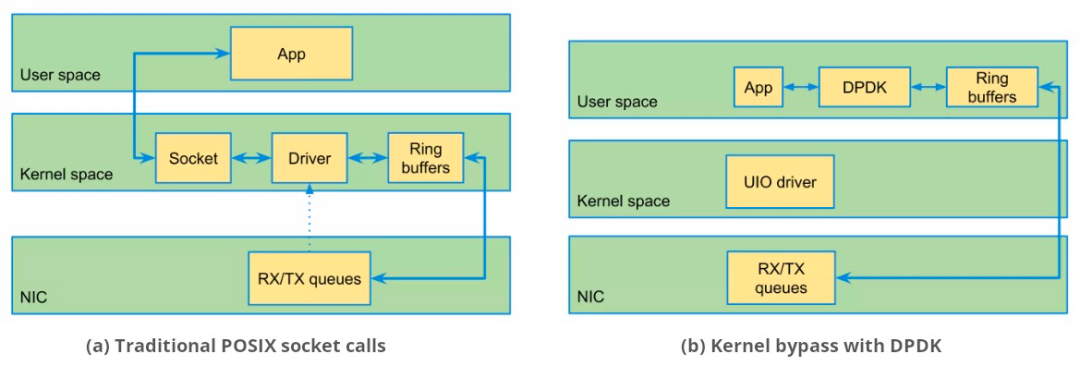
传统的处理是中断驱动的,当数据包到达时,NIC会中断内核。DPDK转而使用轮询,避免了与中断相关的开销。这是由轮询模式驱动程序 ( PMD ) 执行的。另一个重要的优化是零拷贝。在传统网络中,数据包从内核空间的套接字缓冲区复制到用户空间。DPDK避免了这种情况。 DPDK的用户空间对开发人员很有吸引力,因为不需要修改内核。任何基于DPDK 的网络堆栈都可以针对特定应用进行优化。
02 DPDK采用的数据包处理模型是什么?
大致有两种处理模型:
# Run-to-Completion
CPU内核处理数据包的接收、处理和传输。可以使用多个内核,每个内核与专用端口关联。通过接收端扩展 ( RSS ),到达单个端口的流量可以分配到多个内核。
# Pipeline
每个内核专用于特定的工作负载。例如,一个内核可能处理数据包的接收/传输,而其他内核则负责应用程序处理。数据包通过memory rings在内核之间传递。
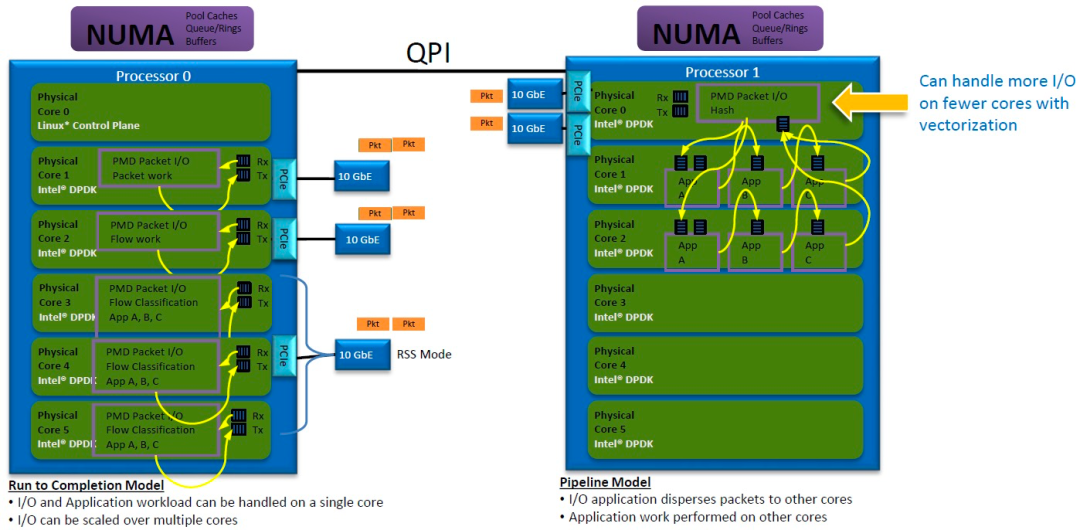
对于单核多CPU部署,一个CPU分配给操作系统,另一个分配给基于DPDK的应用程序。对于多核部署,无论是否使用超线程,都可以为每个端口分配多个内核。 决定使用哪种模型取决于处理每个数据包所需的周期、跨软件模块的数据交换范围、某些内核的特定优化、代码可维护性等。
03 DPDK是否需要TCP / IP堆栈才能工作?
DPDK不包括TCP / IP堆栈。如果应用程序需要用户空间网络堆栈,可以使用 F-Stack、mTCP、TLDK、Seastar 和 ANS 。它们通常提供阻塞和非阻塞套接字API,其中一些是基于 FreeBSD 实现的。 由于省略了网络堆栈,DPDK不会出现通用实现的低效率问题。应用程序可以包括针对其用例进行优化的网络模块,也可能存在一些不需要更高层(L2 以上)处理的用例。
04 在DPDK之前,厂商如何实现高效的数据包处理?
在DPDK之前,有专门的硬件可以进行高效的数据包处理。此类硬件可能使用定制的 ASIC、可编程 FPGA 或网络处理单元 ( NPU ),这些专用硬件以优化的方式完成数据包分类、流量控制、TCP / IP处理、加/解密、VLAN标记等任务。 然而,此类硬件的购买和维护成本昂贵。升级和安全补丁的应用非常耗时,并且需要全职的网络管理员。一种解决方案是从专用硬件转向商用现成 ( COTS ) 硬件。虽然这更具成本效益且更易于维护,但性能却受到了影响。数据包从网卡 ( NIC ) 移动到操作系统 ( OS ),并通过操作系统内核堆栈进行处理。即使使用快速NIC,内核堆栈也是一个瓶颈。系统调用、中断、上下文切换、包复制和逐包处理都会降低性能。 DPDK解决了COTS硬件上的性能问题,无需昂贵的定制硬件即可获得高效的数据包处理。
05 业界谁在使用DPDK? 负载均衡、流分类、路由、访问控制(防火墙)和流量监管是DPDK的典型用途。DPDK不仅适用于电信行业,也已在云环境和企业中使用。流量生成器 (TRex) 和存储应用(SPDK) 使用DPDK。下图列出了DPDK支持的开源项目。

Open vSwitch ( OVS ) 移植到DPDK后表现出了 7 倍的性能提升。在物联网应用中,数据包很小,DPDK减少了延迟并允许每秒处理更多此类数据包。 在 5G 中,用户平面功能 ( UPF ) 处理用户数据包。延迟、抖动和带宽是需要满足的关键性能指标。一些研究人员已经提出将DPDK用于5G UPF的实现。在边缘网络部署UPF时, 可以使用DPDK API连接UPF应用 ( UPF -C) 和 SmartNIC ( UPF -U)。
06 DPDK面临哪些挑战? DPDK需要一定的专业知识,开发人员需要学习DPDK的编程模型。他们需要知道如何管理内存、如何在不复制的情况下传递数据包,以及如何使用多核架构。 例如,PID 命名空间可能会导致管理fbarray出现问题;使用mmap而不指定地址的进程可能会导致问题;线程必须正确分配给CPU内核,才能获得一致的性能;此外,DPDK库还给开发人员提供了多种实现选择,选择错误会影响性能。 由于绕过了内核,失去了Linux 内核提供的所有保护、实用程序( ifconfig、tcpdump)和协议(ARP 、IPSec)。调试和确定网络问题的根本原因也是一项挑战。最后,由于使用轮询而不是中断,因此即使只处理几个数据包,DPDK也会导致 100% 的CPU使用率。
07 还有哪些替代选择?
使用 Snabbswitch、Netmap 或 StackMap 可以通过内核旁路实现更快的数据包处理。与DPDK一样,它们在用户空间中处理数据包。数据包完全绕过内核堆栈。Snabbswitch 是用 Lua 编写的,而DPDK是用 C 编写的。PacketShader 对基于GPU的硬件进行内核旁路。 另一种方法是修改 Linux 内核。例如 eXpress Data Path ( XDP ) 和基于远程直接内存访问 ( RDMA ) 的网络堆栈。其他有效的工具还包括 packet_mmap (但不会绕过内核)和 PF_RING (带有 ZC 驱动程序)。 推荐阅读点击标题可跳转
审核编辑:黄飞
-
防火墙
+关注
关注
0文章
417浏览量
35608 -
交换机
+关注
关注
21文章
2637浏览量
99528 -
路由器
+关注
关注
22文章
3728浏览量
113701 -
TCP
+关注
关注
8文章
1353浏览量
79055 -
DPDK
+关注
关注
0文章
13浏览量
1724
原文标题:全面了解DPDK
文章出处:【微信号:LinuxHub,微信公众号:Linux爱好者】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
设计师在使用高速放大器时遇到的一些常见问题
MM32F103产品中的一些常见问题
关于HPLC的常见问题及解答
关于等离子电视机九大常见问题的解答
NIOS II 常见问题总结
关于一些手机信号放大器安装的常见问题
STM32中遇到的问题--关于串口的一些常见问题






 工商网监
工商网监
评论