 OpenVINO™协同Semantic Kernel:优化大模型应用性能新路径
OpenVINO™协同Semantic Kernel:优化大模型应用性能新路径

作为主要面向 RAG 任务方向的框架,Semantic Kernel 可以简化大模型应用开发过程,而在 RAG 任务中最常用的深度学习模型就是 Embedding 和 Text completion,分别实现文本的语义向量化和文本生成,因此本文主要会分享如何在 Semantic Kernel 中调用 OpenVINO runtime 部署 Embedding 和 Text completion 模型。
Semantic Kernel简介
Semantic Kernel 是微软推出的大模型应用框架,支持 C#, Python 和 Java 等开发环境,通过 Semantic Kernel 集成的API接口,开发者可以直接调用 OpenAI 或是 Hugging Face 中的大语言模型,进一步构建上层应用任务,例如 Chat Copilot 或是 Code completion ,等。顾名思义,Semantic Kernel 的核心就在于由 Kernel 所连接的 pipeline/chain,它通过上下文,实现在各个函数组件间共享数据,下面这张展示的就是用户的输入 Prompt 如何在这些组件中进行流转,最终返回响应结果。
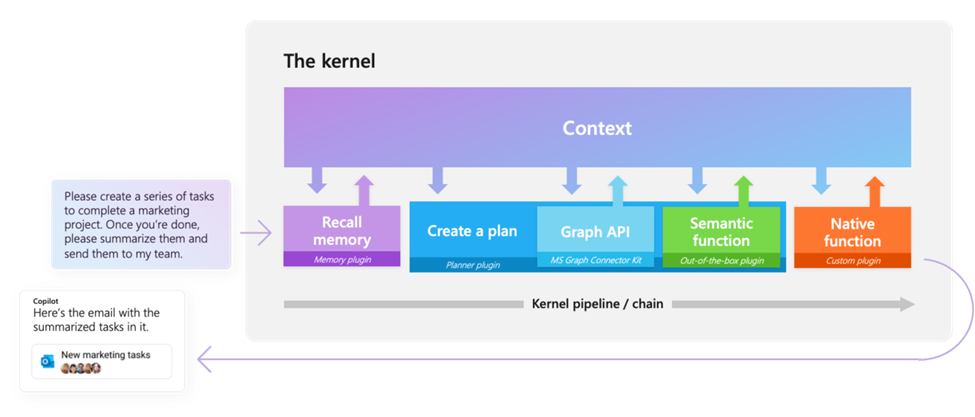
图:Semantic Kernel组件示意图
OpenVINO 简介
OpenVINO 作为英特尔官方推出的深度学习模型部署工具,可以极大地提升本地模型任务的推理性能。同时 OpenVINO 支持了多种推理后端,使模型可以在多种不同的硬件架构上进行部署和切换,进一步提升任务的灵活性与系统资源利用率,例如我们可以利用 NPU 来部署一些轻负载的 AI 模型以降低功耗,利用 GPU 来部署大模型以优化反馈延迟。总之,在大模型本地化趋势越来越热的今天,OpenVINO 势必成为在 PC 端部署大模型任务的好帮手。
OpenVINO 与 Semantic Kernel
集成实现
Semantic Kernel 的 Connector 是一种用于连接外部数据源和服务的设计模式,包括获取数据和保存输出结果,而 Semantic Kernel 已经原生集成了许多开箱即用的大模型服务 Plugin,其中就包括了基于 Hugging Face Transformers 构建的的 Embedding 和 Text completion Service,因此我们可以参考这两个 Service 的代码,来实现一组 OpenVINO 的 Service,完成和 Connectors 组件的集成,分别命名为 OpenVINOTextEmbedding 以及 OpenVINOTextCompletion。
1
Text completion service
首先是 Text completion 任务,由于 OpenVINO 可以通过 Optimum-intel 直接部署 Hugging Face中的 "summarization", "text-generation", "text2text-generation" 等模型,相较原生 Transformers API 的使用方式,也仅仅需要做少量修改(如以下代码所示)。
- from transformers import AutoModelForCausalLM
+ from optimum.intel.openvino import OVModelForCausalLM
- model = AutoModelForCausalLM.from_pretrained(model_id)
+ ov_model = OVModelForCausalLM.from_pretrained(model_id)
generate_ids = ov_model.generate(input_ids)
因此,我们也可以直接在 Hugging Face Text completion service 的基础上直接将 Transformers 的模型加载对象切换为 Optimum-intel 的对象,以实现基于 OpenVINO runtime 的模型推理。这里可通过 OVModelForCausalLM 类来部署 "text-generation" 类型的大模型,通过 OVModelForSeq2SeqLM 类调用 "text2text-generation", "summarization" 类型模型。
if task == "text-generation":
ov_model = OVModelForCausalLM.from_pretrained(
ai_model_id, **_model_kwargs)
elif task in ("text2text-generation", "summarization"):
ov_model = OVModelForSeq2SeqLM.from_pretrained(
ai_model_id, **_model_kwargs)
2
Embedding service
不同于 Text completion service, Semantic Kernel 中集成的 Hugging Face Embedding service 是基于 sentence_transformers 库来实现的,并调用 encode 函数来进行 Embedding 文本向量化。
generator=sentence_transformers.SentenceTransformer(model_name_or_path=ai_model_id, device=resolved_device), embeddings = self.generator.encode(texts)
而 OpenVINO 目前暂未直接对接 sentence_transformers 的模型部署接口,因此这里我们需要手动将 sentence_transformers 的 PyTorch 模型对象转化为 OpenVINO IR 格式后,再重新构建它的 encode 函数 pipeline。
可以看到 Hugging Face 的 embedding 模型除了支持 Sentence-Transformers 对象部署方式外,还可以基于 Transformers 库的方式,通过 AutoModel.from_pretrained 获取 nn.module 格式的模型对象,而 OpenVINO 的 PyTorch 前端则已经支持对该格式对象的直接转换,所以我们首先需要手写一个转换脚本,来实现 Embedding 模型从 PyTorch 对象到 OpenVINO IR 格式的转化过程。
tokenizer = AutoTokenizer.from_pretrained(args.model_id)
model = AutoModel.from_pretrained(args.model_id)
dummy_inputs = {"input_ids": torch.ones((1, 10), dtype=torch.long), "attention_mask": torch.ones(
(1, 10), dtype=torch.long), "token_type_ids": torch.zeros((1, 10), dtype=torch.long)}
ov_model = ov.convert_model(model, example_input=dummy_inputs)
ov.save_model(ov_model, model_path / "openvino_model.xml")
在定义新的 encode 函数时,鉴于在 RAG 系统中的各个句子的向量化任务往往没有依赖关系,因此我们可以通过 OpenVINO 的 AsyncInferQueue 接口,将这部分任务并行化,以提升整个 Embedding 任务的吞吐量。
infer_queue = ov.AsyncInferQueue(self.model, nireq)
for i, sentence in enumerate(sentences_sorted):
inputs = {}
features = self.tokenizer(
sentence, padding=True, truncation=True, return_tensors='np')
for key in features:
inputs[key] = features[key]
infer_queue.start_async(inputs, i)
infer_queue.wait_all()
此外,从 HuggingFace Transfomers 库中导出的 Embedding 模型是不包含 mean_pooling 和归一化操作的,因此我们需要在获取模型推理结果后,再实现这部分后处理任务。并将其作为 callback function 与 AsyncInferQueue 进行绑定。
def postprocess(request, userdata):
embeddings = request.get_output_tensor(0).data
embeddings = np.mean(embeddings, axis=1)
if self.do_norm:
embeddings = normalize(embeddings, 'l2')
all_embeddings.extend(embeddings)
infer_queue.set_callback(postprocess)
测试验证
当完成这两个关键对象的创建后,我们可以来验证一下重新构建的 OpenVINO 任务效果。
第一步:我们需要将 Embedding 和 Text completion 这两个模型分转换并导出到本地。这里以 all-MiniLM-L6-v2 和 gpt2 为例。
Embedding 模型可以通过刚刚定义的转换脚本导出模型:
python3 export_embedding.py -m sentence-transformers/all-MiniLM-L6-v2
Text completion 模型可以通过 Optimum-intel 中自带命令行工具导出:
optimum-cli export openvino --model gpt2 llm_model
第二步:通过修改 Semantic Kernel 官方提供的 Hugging Face Plugins 示例
来测试 OpenVINO Plugin 的效果,该示例基于 Embedding 和 Text completion 模型构建了一个最小化的 RAG 任务 pipeline。此处只需要把原始的 Hugging Face service 对象替换为我们刚刚构建的 OpenVINOTextEmbedding 和 OpenVINOTextCompletion 对象,其中 ai_model_id 需要修改为模型文件夹的本地路径。
kernel.add_text_completion_service( service_id="gpt2", service=OpenVINOTextCompletion(ai_model_id="./llm_model", task="text-generation", model_kwargs={ "device": "CPU", "ov_config": ov_config}, pipeline_kwargs={"max_new_tokens": 64}) ) kernel.add_text_embedding_generation_service( service_id="sentence-transformers/all-MiniLM-L6-v2", service=OpenVINOTextEmbedding(ai_model_id="./embedding_model"), )
在这个示例中 Kernel 是通过 kernel.memory.save_information 函数来实现知识的注入,过程中会调用 Embedding service 来完成对于文本的语义向量化操作。我们可以通过执行以下命令来执行完整的 notebook 测试脚本。
$ jupyter lab sample.ipynb
示例中为了简化模型下载和转化步骤,采用了相较主流 LLM 更轻量化的gpt2来实现文本内容生成,因此在输出内容上会相对单一,如果需要实现更复杂的内容生成能力,可以将其替换为一些参数规模更大的文本生成模型,最终输出结果如下:
gpt2 completed prompt with: 'I know these animal facts: ["Dolphins are mammals."] ["Flies are insects."] ["Penguins are birds."] and "Horses are mammals."
对比官方原始 Hugging Face Plugins 示例的输出结果,与注入的知识库信息,两者对于 animal facts 的判断使一致的,这也证明我们的重新构建的 OpenVINO Plugin 在模型输出的准确性上是没有问题的。
总结
在医疗、工业等领域,行业知识库的构建已经成为了一个普遍需求,通过 Semantic-Kernel 与 OpenVINO 的加持,我们可以让用户对于知识库的查询以及反馈变得更加精准高效,降低 RAG 任务的开发门槛,带来更加友好的交互体验。
审核编辑:刘清
-
JAVA
+关注
关注
20文章
3006浏览量
116833 -
OpenAI
+关注
关注
9文章
1250浏览量
10281 -
大模型
+关注
关注
2文章
3773浏览量
5273 -
LLM
+关注
关注
1文章
350浏览量
1394
原文标题:OpenVINO™ 协同 Semantic Kernel:优化大模型应用性能新路径 | 开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
灵途科技深化跨界协同:共探灵巧手空间感知与纳米微针应用新路径

突破传统桎梏,PPEC Workbench 开启电源智能化设计新路径
硬件与应用同频共振,英特尔Day 0适配腾讯开源混元大模型
切割液性能智能调控系统与晶圆 TTV 预测模型的协同构建
切割液多性能协同优化对晶圆 TTV 厚度均匀性的影响机制与参数设计
无法在NPU上推理OpenVINO™优化的 TinyLlama 模型怎么解决?
晶圆切割振动监测系统与进给参数的协同优化模型
碳化硅衬底切割自动对刀系统与进给参数的协同优化模型
无法将Tensorflow Lite模型转换为OpenVINO™格式怎么处理?
使用Openvino™ GenAI运行Sdxl Turbo模型时遇到错误怎么解决?
无法将Openvino™ 2025.0与onnx运行时Openvino™ 执行提供程序 1.16.2 结合使用,怎么处理?
鸿蒙5开发宝藏案例分享---应用性能优化指南
汇川技术联合蒙牛集团共探人才培养新路径
OpenVINO C#如何运行YOLO11实例分割模型



评论