 Helium技术讲堂—循环缓冲区的使用
Helium技术讲堂—循环缓冲区的使用
RA8系列是瑞萨电子推出的全新超高性能产品业界首款基于Arm Cortex-M85处理器的MCU,能够提供卓越的6.39 CoreMark/MHz,可满足工业自动化、家电、智能家居、消费电子、楼宇/家庭自动化、医疗等广泛应用的各类图形显示和语音/视觉多模态AI要求。
所有RA8系列MCU均利用Arm Cortex-M85处理器和Arm的Helium技术所带来的高性能,结合矢量/SIMD指令集扩展,能够在数字信号处理器(DSP)和机器学习(ML)的实施方面获得相比Cortex-M7内核高4倍的性能提升。

当人工智能 (AI) 下沉到各式各样的应用当中,作为市场上最大量的物联网设备也将被赋予智能性。ArmHelium 技术正是为基于Arm Cortex-M 处理器的设备带来关键机器学习与数字信号处理的性能提升。
在上周的 Helium 技术讲堂中,我们与大家共同探讨了复杂而又有趣的交错加载/存储指令。今天,我们将一起聊聊与内存访问相关的内容。若您想要了解如何高效利用 Helium,千万别错过文末视频,通过 Arm 技术专家的实例演示,详解 Helium 如何为端点设备引入更多智能。
Arm Helium 技术诞生的由来
循环缓冲区的使用
作者:Arm 架构与技术部高级首席工程师 François Botman
我们在为 Arm Cortex-M 处理器系列设计矢量扩展 (MVE) —— Arm Helium 技术时,希望它能广泛地适用于各种数字信号处理 (DSP) 的应用。具备高效的数据计算能力只成功了一半,同样重要的是具备在内存中访问和存储这些数据的能力。
正如之前的文章内容所述,Helium 是一种四节拍矢量架构。将数据加载到矢量中的最直接的方法是连续加载操作(见图一)。在每个节拍中,都从标量寄存器中指定的基址开始依次访问内存。无论目标数据类型如何(8、16 或 32 位),都可以通过充分利用总线宽度的访问来高效地执行这一操作,因为数据元素在内存和矢量中都是相邻的,存储操作也是如此。
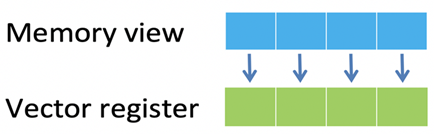
图一:连续加载操作
内存是一种稀缺资源,通常情况下,要尽可能紧凑地打包数据,使用可容纳数据的最小数据类型。不过,在处理数据时,可能需要更多的空间,以避免在计算的中间阶段出现溢出。这可以作为一个独立的拓宽指令来执行,但正如本系列第一篇文章所述,它存在时间跨越问题(对于 8 到 32 位的扩展,将数据扩展到最后一节拍需要第一节拍的数据,而第一节拍的数据已不可用)。
因此,扩展指令不能与其他指令重叠,否则会对性能产生不利影响。相反,Helium 引入了改变大小的内存操作。数据可以作为单个 8、16 或 32 位访问,针对每个节拍高效加载,并用零或符号扩展,以匹配所需的数据类型。在图二的示例中,我们希望执行将每个矢量通道的 8 位加载扩展到 16 位。两个 8 位数据样本作为一个 16 位加载操作加载,每个样本在写入矢量通道之前扩展到 16 位。同样,对于存储来说,数据可以截断到所需的大小,实现高效存储。
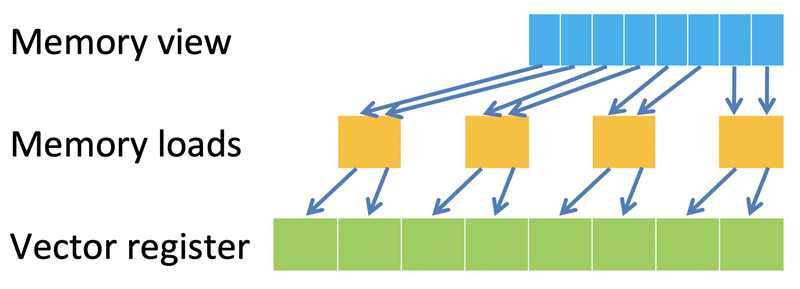
图二:加载扩展
Helium 加载和存储指令具有与 M 系列架构的其他部分相同的丰富的寻址模式集,支持预递增或后递增以及指针回写等功能。这样,在大多数情况下就不需要单独进行指针操作了。
DSP 应用通常在数据结构而非单个元素上运行。例如,立体声音频数据通常以左右数值交织流的形式存储。同样,图像数据通常以红、绿、蓝、Alpha 交错值的形式存储。这是上一篇文章的主题内容,其中介绍了可以有效实现这一目标的结构化加载/存储指令。
有时,存储在内存中的数据无法以便捷的方式构建以实现连续访问。在某些架构中,这实际上会阻碍代码的矢量化。Helium 通过“离散‑聚合”操作解决了这一问题。这些操作将偏移矢量指向内存,这样就可以用一条指令访问多个非连续地址(见图三)。它们还能扩展或截断所访问的数据。
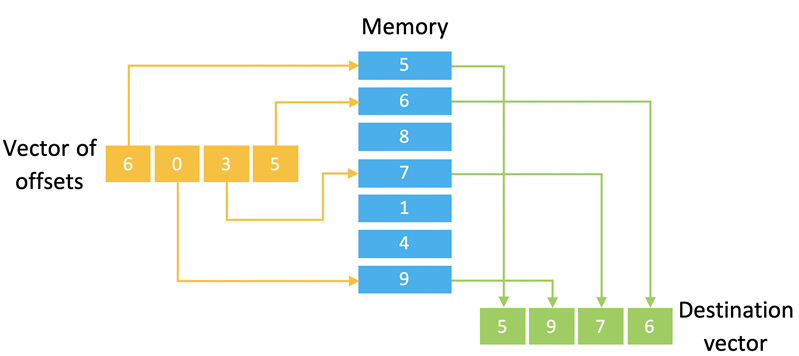
图三:汇总负载
“离散-聚合”操作是一种功能强大的指令,可为应用提供很大的灵活性。例如,它们几乎是实现 FFT(快速傅里叶变换)不可或缺的工具;在这种算法中,第一个或最后一个蝴蝶阶段的内存访问需要使用反位寻址执行。专用反位指令 (VBRSR) 生成反位寻址模式,供这些离散-聚合指令使用。
为了提高性能,这些指令重叠执行,加载数据的效率远远超过同等序列的标量指令。而且,它们也更容易使用。虽然连续矢量访问能为规律模式提供更好的性能,但由于离散-聚合指令无法对数据布局做出假设,因此有多少个不同的元素,汇总加载指令就必须执行多少次单独的访问。对于 8 位数据,访问次数可能多达 16 次,这就成了不断加载的负载。
DSP 应用通常使用一种称为循环寻址的内存布局。可以按顺序访问元素,但最多只能访问配置的缓冲区大小,之后的访问会绕回到第一个元素(见图四)。例如,从元素 N‑1 开始的四元素读取操作将会访问元素 N‑1, 0, 1, 2。
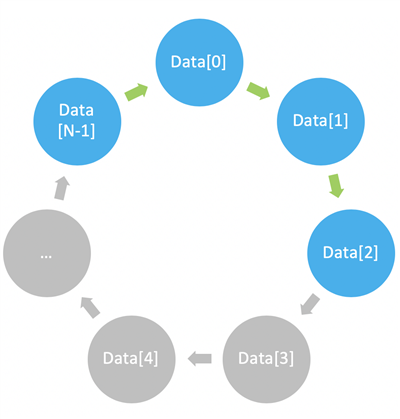
图四:循环缓冲区示例
这在 DSP 应用中用途广泛,包括在处理数据流后只需要前 N 个数据样本时避免指针操作。在 FIR 滤波器中,最后 N 个数据样本需要与一组系数相乘,才能产生所需的滤波器响应。当一个新的数据样本到来时,需要处理的是之前的 N‑1 个样本和新样本,最旧的样本不再使用。数据可以重新排列,使要处理的缓冲区总是按正确的顺序包含元素,但这需要在开始处理前将每个样本复制到不同的位置,耗费大量资源。如果使用循环缓冲区,就可以就地访问数据,必要时还可以绕回到开头,而且只需要写入一次就可以用最新的样本替换最旧的样本。
一些 DSP 通过专用访问指令和专用寄存器来实现循环缓冲区的起始地址和结束地址。指针每次递增时,硬件都会将其与结束地址进行比较,并相应地回绕。这意味着同时支持的循环缓冲区数量受到可用硬件的限制。这也意味着每次中断都需要保留大量额外状态,而这会影响延迟。
为此,所需的硬件支持不容忽视;在典型的实施中,需要更复杂的地址生成单元。为了避免这种情况,一些 DSP 要求循环缓冲区的大小等于 2 的幂次方,缓冲区的地址调整为该大小的倍数。可以通过将指针与位掩码进行 AND 运算实现,从而简化硬件要求。但是,这样会限制这些缓冲区的放置和使用,特别是几乎无法直接从高级语言使用缓冲区。由于 M 系列的宗旨是让一切都能通过 C 语言轻松使用,因此我们需要想出一种更好的方法。
我们的解决方案是将循环缓冲区分成两个不同的操作,其方式与上文讨论的反位寻址类似。我们将用于生成回绕偏移的指令与离散‑聚合指令相结合来访问这些偏移地址的数据。这就为缓冲区大小和位置提供了灵活性,而且关键路径上也不需要有专用硬件。循环缓冲区生成指令 (VIWDUP) 可创建一个矢量,其中包含一连串递增的偏移量,当到达终点位置时会回绕到开头(见图五)。该指令用从 R0 值开始的序列填充矢量寄存器 Q0,并在达到 R1 值时回绕。然后,它将更新后的起始偏移量 2 写回 R0。这条指令的一个巧妙设计是,每次写入 Q0 的偏移量矢量都是由标量值重新生成的。
通常下一条指令就是使用偏移量的离散‑聚合指令,因此 Q0 可以直接重复用于其他目的。立即值指定偏移量的增量,这对于处理不同的元素大小非常有用。例如,如果加载的是 32 位数值,将使用四个字节的增量。可以指定任意增量或减量,因此该指令可用于其他需要通用数字模式的情况。通过这种方式,Helium 可以提供任意数量的循环缓冲区,在内存中具有灵活的大小、方向和对齐方式,而且这个过程只需要使用现有的硬件就可以提供序列生成指令。
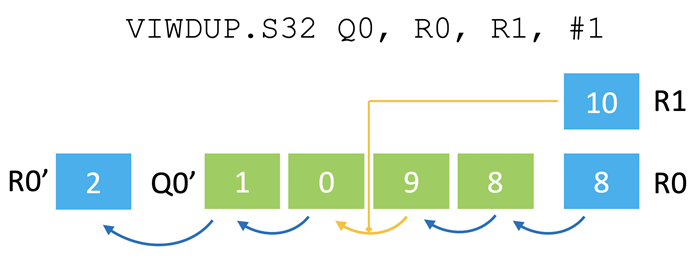
图五:序列生成指令的操作示例
那么性能表现如何呢?虽然需要额外的偏移生成指令 (VIWDUP),但我们发现在许多情况下,可能会因为与内存访问本身重叠而隐藏了开销。在所有情况下,这一开销都小于在没有硬件支持的情况下管理回绕的计算工作量。我们之前也说过,出于性能考虑,最好使用连续访问。循环缓冲区的特别之处在于,大部分访问都是连续的,只有偶尔发生回绕时才会出现不连续。一种方法是离散-聚合指令比较偏移值,然后合并连续的访问。遗憾的是,这样做将需要大量额外的硬件,并给设计的关键部分增加许多额外的复杂性。在负载连续的情况下,离散‑聚合操作会降低性能,这违背了我们追求将每个 gate 的性能发挥到极致的原则。
当我们试图找到解决这个问题的方法时,我们注意到偏移生成指令 (VIWDUP) 已经掌握回绕点的位置。如果能将这一信息传递给离散-聚合指令,它就能将访问提升为连续访问,而无需使用昂贵又耗时的偏移比较器。那么我们能不能指定一个额外的标量寄存器来传输这些信息呢?遗憾的是,这将增加所需的读取端口数量,而且标量依赖关系从 VIWDUP 改为离散‑聚合指令将会导致指令无法重叠。
Helium 实现是否可以将这些信息存储在隐藏的微架构元数据中,并在矢量发生修改时清除元数据?一般不建议这样做,因为元数据需要在中断时保留,而这会影响延迟。但我们发现,在这种情况下,我们不需要保留元数据。在出现异常的极少数情况时,备选措施是正常执行离散-聚合,而不是优化连续访问。通过使用易失性隐藏元数据来指示连续访问,可以优化普通非回绕情况下的性能,同时避免出现额外的架构状态和中断延迟。
在受限的环境中工作极具挑战性,Helium 要求我们不断寻找创新的解决方案,充分发挥硬件性能。我们努力联合设计架构和微架构,寻找一系列内存访问指令,既能满足 DSP 应用的需要,又能最大限度地减少实现这些指令所需的硬件数量。特别是在循环缓冲区方面,我们延续了 M 系列的传统,确保每个 gate 都物尽其用,从而以较低的面积实现性能表现,同时为终端用户提供良好的体验感。
您是否想要更深入了解 Helium 技术?由 Arm 物联网事业部技术管理总监 Mark Quartermain 与 Arm 物联网事业部嵌入式工具集成高级经理 Matthias Hertel 共同为大家录制了 Helium 技术视频,通过实例演示详解如何高效利用 Helium。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19349浏览量
230307 -
寄存器
+关注
关注
31文章
5357浏览量
120701 -
人工智能
+关注
关注
1792文章
47443浏览量
239020 -
机器学习
+关注
关注
66文章
8425浏览量
132776 -
快速傅里叶变换
+关注
关注
0文章
13浏览量
1703
原文标题:Helium技术讲堂 | 循环缓冲区的使用
文章出处:【微信号:瑞萨MCU小百科,微信公众号:瑞萨MCU小百科】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐

基于宏高效实现环形缓冲区教程
请问串口的DMA接收缓冲区是不是环形缓冲区
DMA循环缓冲区如何重置起点?
基于状态图的缓冲区溢出攻击分析
缓冲区溢出攻击的防护技术分析
缓冲区溢出攻击的原理和防范技术分析
环形缓冲区的实现原理
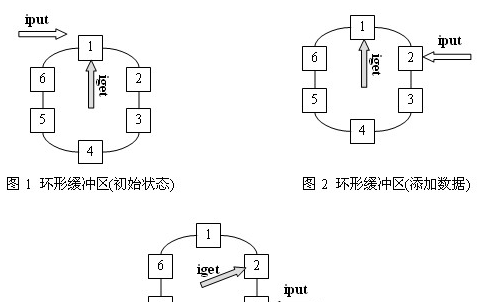
缓冲区是啥意思 STM32串口数据接收之环形缓冲区
STM32串口数据接收 --环形缓冲区

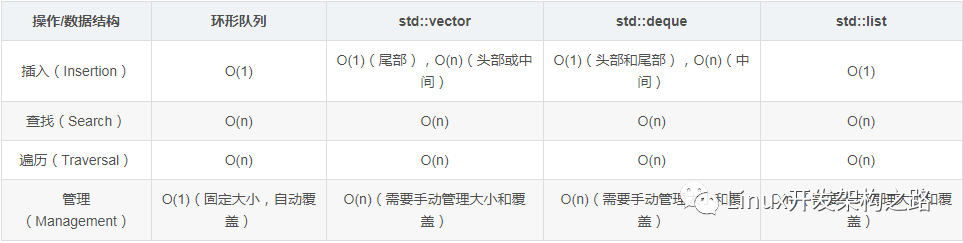
基于C语言的循环队列缓冲区原理、设计与实现
C++环形缓冲区设计与实现





 工商网监
工商网监
评论