 大模型微调开源项目全流程
大模型微调开源项目全流程
作者:1050Ti全量微调.,东北大学软件工程
微调实战经历
本次微调经验分享依据于我们在2023年参加的“第2届·百度搜索创新大赛——搜索答案组织”整个比赛过程。
我们团队选择的基座模型是ChatGLM3-6B-Base模型,训练数据集为官方提供的数据集(9000条),训练方法为LORA sft 监督微调。
最终结果:score 36.12--ROUGE-L 41.03--BLEU-4 31.22,东三省排名第1名,全国最终排名为44/220.
开始微调(SFT)
准备微调框架
微调框架选择的是github上面的llama-factory开源项目
gitclonehttps://github.com/hiyouga/LLaMA-Factory.git
cdLLaMA-Factory
pipinstall-rrequirements.txt
推荐python=3.10,如果要在 Windows 平台上开启量化 LoRA(QLoRA),需要安装预编译的 bitsandbytes 库, 支持 CUDA 11.1 到 12.1
pipinstallhttps://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.39.1-py3-none-win_amd64.whl
加载数据集
在data文件夹下面创建xxx.json命名格式的数据集json文件,本人设置的是baidutrain.json
json文件格式如下
[
{
"query":"王者荣耀钻石夺宝幸运值满是多少",
"refs":[
"积分夺宝幸运值满值为360点,钻石夺宝幸运值满值为200点,但是夺宝幸运值满了之后还需要一抽才能获得水晶,所以积分夺宝361抽必定获得水晶,钻石夺宝201抽必定获得水晶。",
"王者钻石夺宝幸运值满是200。",
"1、最高的幸运值上限是200,每抽一次会获得1点幸运值。王者荣耀里面的钻石夺宝幸运值达到200就满了,也就是说当幸运值满200时,再夺宝一次是必出一个王者水晶的,拥有王者水晶可以到水晶商店里面去兑换物品了,兑换的物品都是永久的。",
"幸运值满值是360,玩家在抽361的时候是保底必出水晶,这个保底是人人都能抽出水晶的,也就是100%可以让玩家得到水晶,荣耀水晶的概率是0.8%,但是玩家们如果在不断增加抽奖的次数,那么抽出水晶的概率也会增加,想要抽出水晶的玩家可以将361次当做保底的次数。",
"玩家获取王者水晶之后,可以使用该道具兑换王者商店中的奖励,包含了回城特效、英雄、中级品质的皮肤等奖励。"
],
"answer":"《王者荣耀》钻石夺宝幸运值满值为200点。
钻石夺宝幸运值满200后再抽一次必出一个王者水晶,玩家获取王者水晶之后,可以使用该道具兑换王者商店中的奖励,其中包含了回城特效、英雄、中级品质的皮肤等,兑换的物品永久有效。"
},
{
"query":"王手是什么意思",
"refs":[
"一、原神王手。王手这个词出现在PV短片《雪姬逢椿》中。王手是小神里说的,小神里很可爱,说王手二字的声音也不错。所以玩家说王手二字让我氪了648。二、王手原意。王手是日本将棋的说法,与中国象棋将军的用法相似。意思是将军(棋步),将军。",
"一、原神王手在PV短片——「雪霁逢椿」中出现了王手这个词。王手是由小神里说出的,小神里十分可爱,说王手二字时声音也好听。所以玩家就表示王手二字让我氪了648。二、王手原本意思王手是日本将棋的说法,和中国象棋将军的用法差不多。是将军(的棋步),将一军的意思。",
"王手是日本将棋的说法,与中国象棋将军的用法相似。意思是将军(棋步),将军。",
"其中的王手是指,如能下了能擒拿对方王将的一手,类似于象棋里的将军。称之为王手。",
"王手,男,浙江温州市人。1981年开始发表小说。近年小说散见于《收获》《人民文学》《当代》《钟山》《花城》《作家》《山花》等刊,出版中短篇小说集《火药枪》《柯依娜一个人》《狮身人面》"
],
"answer":"王手是指下了这步棋能擒拿对方王将的一手,类似于象棋里的将军,是日本将棋中的一种说法。
此外,王手还是中国作家协会会员,一级作家,出版中短篇小说集《火药枪》《柯依娜一个人》等。"
}
]
一定要将数据集所在的json文件加载到dataset_info.json中!!!!!!!!
"baidu_train":{
"file_name":"baidutrain.json",
"columns":{
"prompt":"",#系统prompt
"query":"refs"+"query",#输入
"response":"answer",#输出
"history":""#历史对话
}
}
启动微调
使用sft进行微调
CUDA_VISIBLE_DEVICES=0pythonwork/jwx/ChatGLM-Efficient-Tuning-main/src/train_bash.py --stagesft#微调方式 --model_name_or_pathwork/jwx/ChatGLM3-main/model#模型路径 --do_train --dataset_dirwork/jwx/ChatGLM-Efficient-Tuning-main/data#数据集文件夹 --datasetbaidu_dev,baidu_train#数据集 --finetuning_typelora#微调方法 --max_source_length2048#最大长度 --max_target_length512 --learning_rate3e-05#学习率 --num_train_epochs3.0#学习轮数 --max_samples10000 --lora_rank8#lora训练的秩 --lora_dropout0.1 --lora_targetq_proj,v_proj#lora作用层 --resume_lora_trainingTrue --output_dirsaves/output#输出微调的文件夹 --fp16True#开启fp16微调 --per_device_train_batch_size4 --gradient_accumulation_steps4 --lr_scheduler_typecosine --max_grad_norm1.0 --logging_steps5 --save_steps1000
对于所有“基座”(Base)模型,–template 参数可以是 default, alpaca, vicuna 等任意值。但“对话”(Chat)模型请务必使用对应的模板。
更多参数信息:
https://github.com/hiyouga/ChatGLM-Efficient-Tuning/wiki/%E4%BD%BF%E7%94%A8%E6%96%B9%E6%B3%95
合并模型并导出
pythonsrc/export_model.py --model_name_or_pathwork/jwx/ChatGLM3-main/model --adapter_name_or_pathsaves/output --templatedefault --finetuning_typelora --export_dirpath_to_export --export_size7 --export_legacy_formatFalse
RW
奖励模型训练
数据准备
奖励模型,作为RL中的critic,应该让模型知道什么是正确的答案和什么是错误的答案,因此需要在数据集上进行对于不同答案的一个打分情况,来让机器进行学习。格式如下:
[
0:{
input:"",
instruction:"Whatarethethreeprimarycolors?",
output:[
0:"Thethreeprimarycolorsarered,blue,andyellow.Thesecolorsarecalledprimarybecausetheycannotbecreatedbymixingothercolorsandallothercolorscanbemadebycombiningtheminvariousproportions.Intheadditivecolorsystem,usedforlight,theprimarycolorsarered,green,andblue(RGB).",
1:"Red,Yellow,andGreen."
]
},
1:{
input:"4/16",
instruction:"Explainwhythefollowingfractionisequivalentto1/4",
output:[
0:"Thefraction4/16isequivalentto1/4becausebothnumeratorsanddenominatorsaredivisibleby4.Dividingboththetopandbottomnumbersby4yieldsthefraction1/4.",
1:"1/4isthesameas1/4."
]
}
]
运行微调
微调之后的奖励模型不可以直接进行使用,因为rw模型的输出是一个打分,相当于RL中的critic。
CUDA_VISIBLE_DEVICES=0pythonsrc/train_bash.py --stagerm --do_train --model_name_or_pathpath_to_llama_model --adapter_name_or_pathpath_to_sft_checkpoint#sft模型微调的权重文件,可加可不加 --create_new_adapter --datasetcomparison_gpt4_zh --templatedefault --finetuning_typelora --lora_targetq_proj,v_proj --output_dirpath_to_rm_checkpoint --per_device_train_batch_size2 --gradient_accumulation_steps4 --lr_scheduler_typecosine --logging_steps10 --save_steps1000 --learning_rate1e-6 --num_train_epochs1.0 --plot_loss --fp16
RLHF
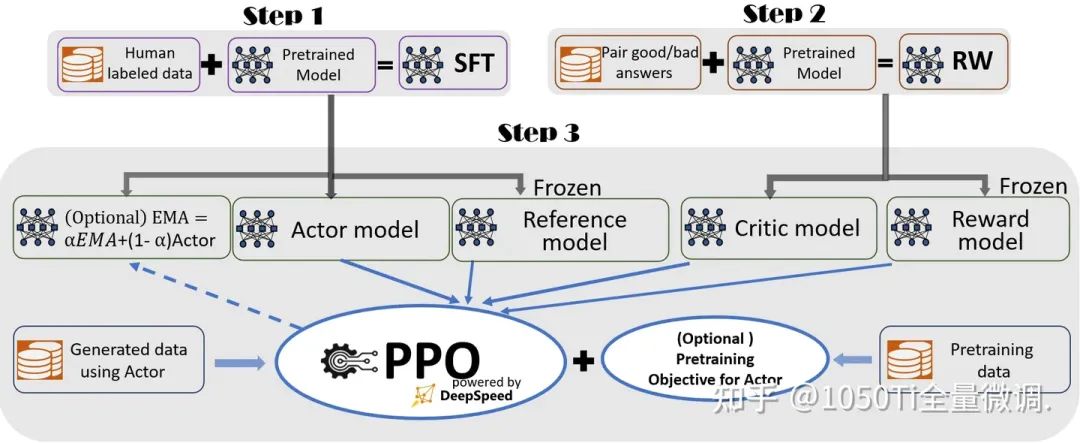
准备actor和critic
actor:对应的是sft输出的权重文件
critic:对应的是RW输出的权重文件
运行RLHF
CUDA_VISIBLE_DEVICES=0pythonsrc/train_bash.py --stageppo --do_trainTrue --model_name_or_pathbaichuan-inc/baichuan-7B --adapter_name_or_pathsaves/Baichuan-7B-Base/lora/sft#sft输出的权重文件 --finetuning_typelora --templatedefault --dataset_dirdata --datasetalpaca_gpt4_en --cutoff_len1024 --learning_rate5e-05 --num_train_epochs3.0 --max_samples100000 --per_device_train_batch_size4 --gradient_accumulation_steps4 --lr_scheduler_typecosine --max_grad_norm1.0 --logging_steps5 --save_steps100 --warmup_steps0 --lora_rank8 --lora_dropout0.1 --lora_targetW_pack --create_new_adapterTrue --output_dirsaves/Baichuan-7B-Base/lora/train_2024-03-01-09-49-43 --fp16True --reward_modelsaves/Baichuan-7B-Base/lora/rw#rw输出的权重文件 --reward_model_typelora --plot_lossTrue
多卡训练
使用accelerate进行训练
accelerateconfig#首先配置分布式环境 acceleratelaunchsrc/train_bash.py --stagesft#微调方式 --model_name_or_pathwork/jwx/ChatGLM3-main/model#模型路径 --do_train --dataset_dirwork/jwx/ChatGLM-Efficient-Tuning-main/data#数据集文件夹 --datasetbaidu_dev,baidu_train#数据集 --finetuning_typelora#微调方法 --max_source_length2048#最大长度 --max_target_length512 --learning_rate3e-05#学习率 --num_train_epochs3.0#学习轮数 --max_samples10000 --lora_rank8#lora训练的秩 --lora_dropout0.1 --lora_targetq_proj,v_proj#lora作用层 --resume_lora_trainingTrue --output_dirsaves/output#输出微调的文件夹 --fp16True#开启fp16微调 --per_device_train_batch_size4 --gradient_accumulation_steps4 --lr_scheduler_typecosine --max_grad_norm1.0 --logging_steps5 --save_steps1000#参数同上
使用deepspeed进行训练
deepspeed--num_gpus8--master_port=9901src/train_bash.py --deepspeedds_config.json --stagesft#微调方式 --model_name_or_pathwork/jwx/ChatGLM3-main/model#模型路径 --do_train --dataset_dirwork/jwx/ChatGLM-Efficient-Tuning-main/data#数据集文件夹 --datasetbaidu_dev,baidu_train#数据集 --finetuning_typelora#微调方法 --max_source_length2048#最大长度 --max_target_length512 --learning_rate3e-05#学习率 --num_train_epochs3.0#学习轮数 --max_samples10000 --lora_rank8#lora训练的秩 --lora_dropout0.1 --lora_targetq_proj,v_proj#lora作用层 --resume_lora_trainingTrue --output_dirsaves/output#输出微调的文件夹 --fp16True#开启fp16微调 --per_device_train_batch_size4 --gradient_accumulation_steps4 --lr_scheduler_typecosine --max_grad_norm1.0 --logging_steps5 --save_steps1000
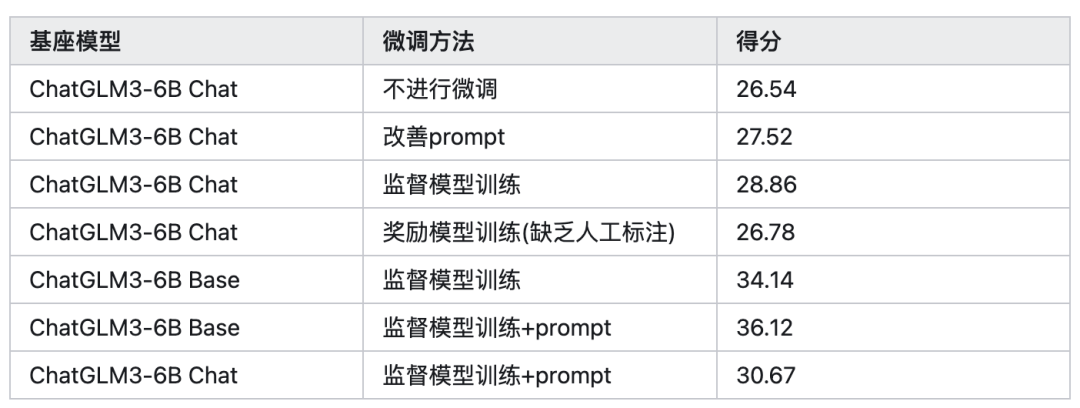
心得分享
下面我将本次比赛微调训练的得分的过程分享给大家
审核编辑:黄飞
-
机器学习
+关注
关注
66文章
8408浏览量
132576 -
大模型
+关注
关注
2文章
2427浏览量
2650
原文标题:详解大模型微调全流程
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
2月全志芯片开源项目分享合集
手绘图的方式带你了解机器学习模型构建的全流程

可调开关电源的原理 可调开关电源的工作流程
iPhone都能微调大模型了嘛
清华等开源「工具学习基准」ToolBench,微调模型ToolLLaMA性能超越ChatGPT
【AI简报20230818期】人形机器人问世:大模型加持;用AI微调AI,微软全华班出品!

OpenAI开放大模型微调功能 GPT-3.5可以打造专属ChatGPT
最佳开源模型刷新多项SOTA,首次超越Mixtral Instruct!「开源版GPT-4」家族迎来大爆发






 工商网监
工商网监
评论