 英伟达2024年GTC人工智能大会看点,黄仁勋发布最炸裂的B200 GPU,讲述人工智能奇迹
英伟达2024年GTC人工智能大会看点,黄仁勋发布最炸裂的B200 GPU,讲述人工智能奇迹
2024年GTC人工智能大会,和过去一样,黄仁勋,这位穿黑色皮夹克的男人用两个小时讲述了人工智能的奇迹,发布最炸裂的B200 GPU,以及让人工智能唱歌跳舞的下一代硬件和软件技术。
JAEALOT
2024年3月19日
2024年GTC人工智能大会,黄仁勋向一群崇拜的技术人员和投资者发表了现场主题演讲。和过去一样,这位穿黑色皮夹克的男人用两个小时讲述了人工智能的奇迹,以及让人工智能唱歌跳舞的下一代硬件和软件技术。
老黄的主题演讲从公司过去二十年左右的历程开始。不得不说,英伟达二十年左右发展成今天人工智能的领头羊,是非常了不起的。
接着便是本次大会的重磅产品,Blackwell B200 GPU,号称是如今世界上最强大的AI芯片。
在这里,我们可以看到一个 Arm CPU,两侧是 DRAM 封装,以及两个相连的下一代 GPU。在此图中,每个 Blackwell GPU 似乎都有八个 HBM 包和两个计算芯片。
这是Blackwell GPU芯片和Hopper H100芯片的尺寸比较。
这是两款芯片的特写照,浓缩就是精华~不断超越摩尔定律,开始自己的老黄定律。
NVIDIA 为现有 DGX/HGX 系统提供 Blackwell GPU 设计,DGX B100 和 HGX B100 适用于 x86 服务器。它的设计功率约为 700W,因此可以在现有系统中工作。
NVIDIA Blackwell HGX B100
这是 NVIDIA Grace Blackwell,配有两Blackwell GPU 和一个 Grace CPU,每个 CPU 都有内存。板卡顶部有 NVLink,板卡底部有 PCIe。

NVIDIA Grace Blackwell GB200 生产板
这就是未来的 Arm 和 NVIDIA。下面是开发板,上面是生产板。

NVIDIA Grace Blackwell 开发板
以下是配备 192GB HBM3e 的 Blackwell GPU 的规格,听起来像是 8x 8-hi HBM 堆栈。

还有一些新功能,例如可以处理 FP4 和 FP6 的新变压器引擎。第五代 NVLink、RAS、安全 AI 和解压缩引擎。

FP4 和 FP6 比 Hopper 增加了大量性能。

NVIDIA 还发布了 ConnectX-8 / ConnectX-800G Infiniband。800GBps 网络已经到来,所以这必须是 PCIe Gen6。

NVIDIA ConnectX 8
有趣的是,NVIDIA 仍在使用 BlueField-3 DPU,而不是新一代。考虑到其他所有内容都进行了修订,这感觉很奇怪。
这是 800Gbps NVIDIA Quantum Infiniband 交换机。

800Gbps NVIDIA 量子交换机
这是新的 NVLink 开关芯片。这是一件大事,因为业内其他公司没有这样的扩展解决方案。

NVLink开关芯片
这是新的 NVIDIA DGX GB200 NVL72。通过 NVLink 连接 72 个 Blackwell GPU。

NVIDIA GB200 72 Blackwell GPU 通过 NVLink 完全连接
这是一款液冷且支持 NVLink 的 DGX。这比当前的 DGX 系统大得多。这大约是120kW。

NVIDIA DGX GB200 NVL72
这是使用铜的 NVLink 主干,可节省约 20kW 的功率。

NVIDIA DGX GB200 NVL72 NVLink Spine 不带光学器件
NVIDIA GB200 机箱中还有带有两个 GB200 复合体的交换机。

NVIDIA GB200 内部 NVLink 开关
以下是 NVIDIA Blackwell 计算节点的概述。

NVIDIA Blackwell 计算节点
以下是 GPU 对 Pascal 性能的影响。为了实现这一目标,NVIDIA 做了很多事情,例如添加张量核心、改变精度等,此外还缩小了工艺并在芯片上塞进了更多晶体管。
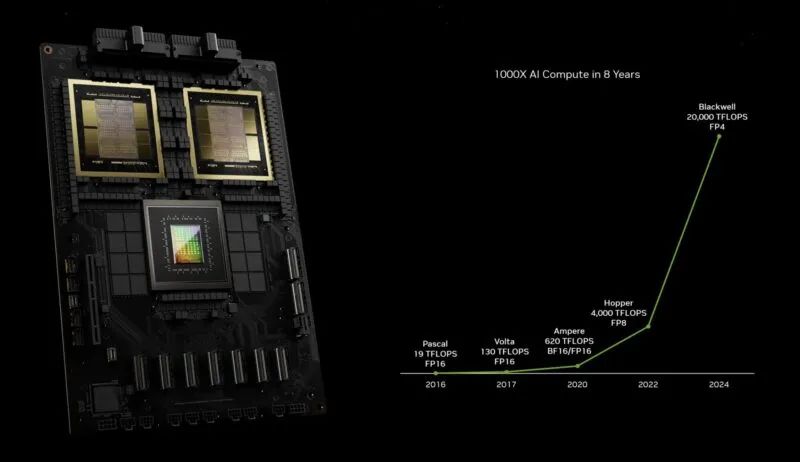
NVIDIA Pascal 到 Blackwell 的 AI 计算扩展
NVIDIA 表示,由于采用了新的 NVSwitch 和新的 FP4 变压器引擎,Blackwell 的性能大约是 Hopper 的 30 倍。紫色线是如果 NVIDIA 建造一个更大的带有更多晶体管的 Hopper 时会发生的情况。
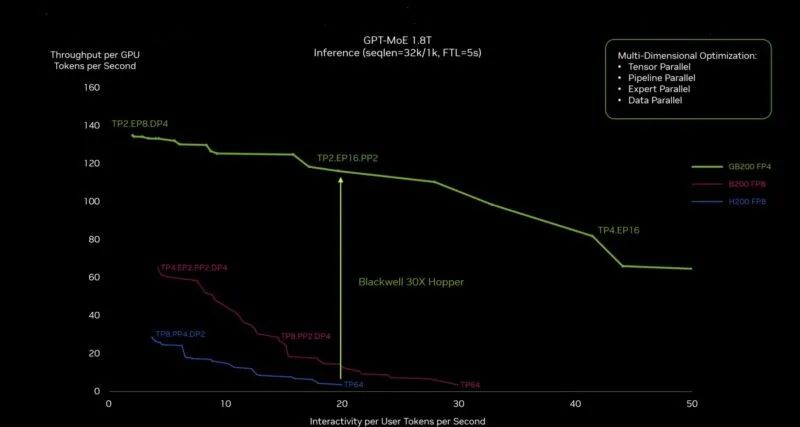
NVIDIA Blackwell To Hopper 推理性能
如果您是另一家生产与 NVIDIA 规模相当的人工智能加速器的公司,这应该会让您感到紧张。AWS、Google、Microsoft 和 OEM/ODM 都是 Blackwell 的客户。
NVIDIA 刚刚展示了 Apple Vision Pro 在 Omniverse 中的工作情况。这将为苹果打开一个巨大的市场。
Apple Vision Pro 和 NVIDIA Omniverse
NVIDIA 正在将预先训练的模型与依赖项打包在一起,并使其能够轻松部署被称为 NVIDIA 推理微服务或 NIMS 的微服务。这不仅仅是 CUDA。这使得模型易于实施。
NVIDIA 推理微服务 NIMS
NVIDIA 将帮助公司和应用程序微调模型或定制模型。
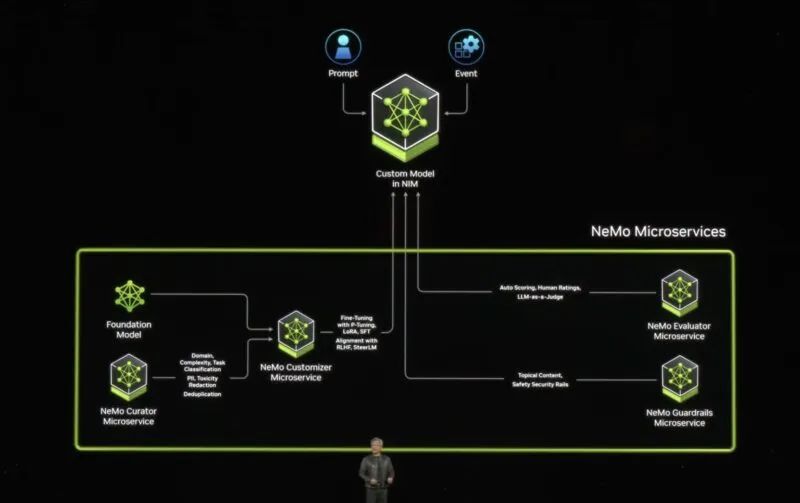
NVIDIA NeMo 微服务
借助 NVIDIA DGX Cloud,NVIDIA 希望成为 AI 代工厂,或者像台积电一样成为 AI 代工厂。
NVIDIA Drive Thor 将被比亚迪等公司采用。
NVIDIA 驱动雷神
NVIDIA Jetson Thor 用于更新 NVIDIA Jetson Orin 的机器人。NVIDIA 的一大赌注是下一代能够控制人形机器人。NVIDIA 也正在为此构建一个软件堆栈。
适用于人形机器人的 NVIDIA Jeton Thor
世界是为人类而生,因此英伟达试用 NVIDIA Thor 和 NVIDIA Project GR00T 软件来训练和管理新型人形机器人。
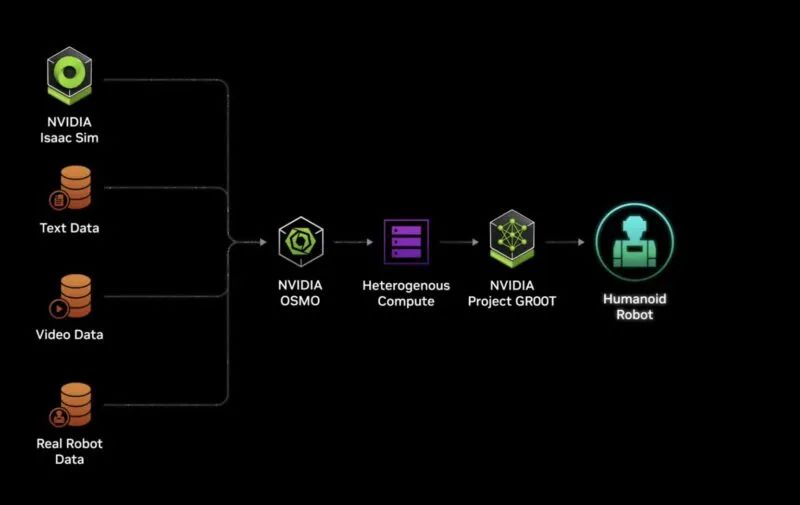
英伟达GR00T
老黄带着由该公司提供支持的人形机器人登上舞台,其中包括来自迪士尼的小型机器人,它们在 NVIDIA Isaac SIM 中学习行走。

NVIDIA GR00T 和机器人
NVIDIA 正试图通过机器人技术架起数字世界与物理世界的桥梁。从公司的数据中心产品一路走到边缘。这就是本次 GTC 2024的愿景。
-
gpu
+关注
关注
28文章
4700浏览量
128672 -
人工智能
+关注
关注
1791文章
46820浏览量
237457 -
英伟达
+关注
关注
22文章
3739浏览量
90786
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论