 一文详解GPU硬件与CUDA开发工具
一文详解GPU硬件与CUDA开发工具

GPU 硬件简介
从十多年前起,GPU 的浮点数运算峰值就比同时期的 CPU 高一个量级;GPU 的内存带宽峰值也比同时期的 CPU 高一个量级。
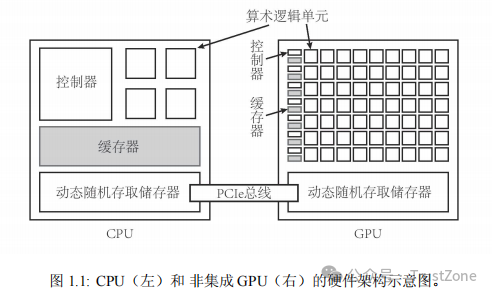
CPU 和 GPU 的显著区别是:一个典型的 CPU 拥有少数几个快速的计算核心,而一个典型的 GPU 拥有几百到几千个不那么快速的计算核心。CPU 中有更多的晶体管用于数据缓存和流程控制,但 GPU 中有更多的晶体管用于算术逻辑单元。
所以,GPU 是靠众多的计算核心来获得相对较高的计算性能的。图 1.1 形象地说明了(非集成) GPU 和 CPU 在硬件架构上的显著区别。
GPU 计算不是指单独的 GPU 计算,而是指 CPU + GPU 的异构(heterogeneous)计算。
一块单独的 GPU 是无法独立地完成所有计算任务的,它必须在 CPU 的调度下才能完成特定任务。在由 CPU 和 GPU 构成的异构计算平台中,通常将起控制作用的 CPU 称为主机(host),将起加速作用的 GPU 称为设备(device)。主机和(非集成)设备都有自己的 DRAM(dynamic random-access memory,动态随机存取内存),它们之间一般由 PCIe 总线(peripheral component interconnect express bus)连接,如图 1.1 所示。
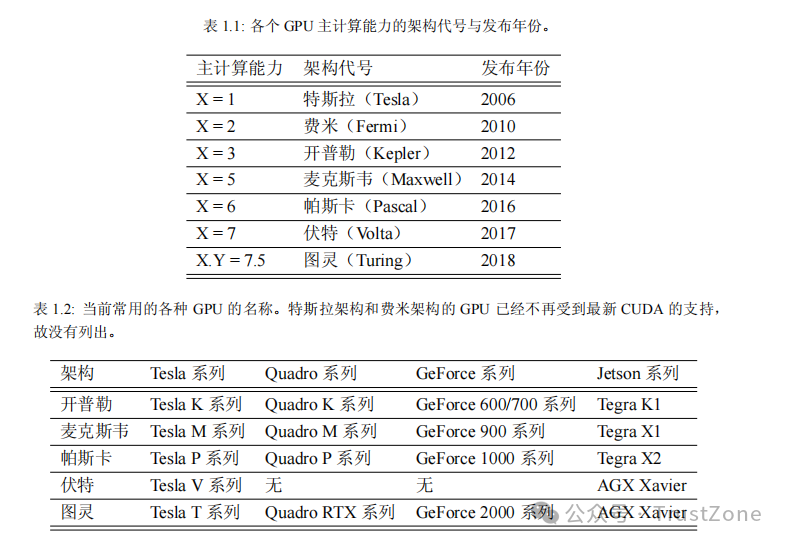
本书中说的 GPU 都是指英伟达(Nvidia)公司推出的 GPU,因为 CUDA 编程目前只支持该公司的 GPU。以下几个系列的 GPU 都支持 CUDA 编程:
• Tesla 系列:其中的内存为纠错内存(error-correcting code memory,ECC 内存),稳定性好,主要用于高性能、高强度的科学计算。
• Quadro 系列:支持高速 OpenGL 渲染,主要用于专业绘图设计。
• GeForce 系列:主要用于游戏与娱乐,但也常用于科学计算。GeForce 系列的 GPU 没有纠错内存,用于科学计算时具有一定的风险。然而,GeForce 系列的 GPU 价格相对低廉、性价比高,用于学习 CUDA 编程是没有任何问题的。即使是便携式计算机中 GeForce 系列的 GPU 也可以用来学习 CUDA 编程。
• Jetson 系列:嵌入式设备中的 GPU。作者对此无使用经验,本书也不专门讨论。
每一款 GPU 都有一个用以表示其“计算能力”(compute capability)的版本号。该版本号可以写为形如 X.Y 的形式。其中,X 表示主版本号,Y 表示次版本号。版本号决定了 GPU 硬件所支持的功能,可为应用程序在运行时判断硬件特征提供依据。
初学者往往误以为 GPU 的计算能力越高,性能就越高,但后面我们会看到,计算能力和性能没有简单的正比关系。
CUDA 程序开发工具
CUDA 编程语言最初主要是基于 C 语言的,但目前越来越多地支持 C++ 语言。还有基于 Fortran 的 CUDA Fortran 版本及由其他编程语言包装的 CUDA 版本,但本书只涉及基于 C++ 的 CUDA 编程。我们称基于 C++ 的 CUDA 编程语言为 CUDA C++。
对 Fortran 版本感兴趣的读者可以参考网站 https://www.pgroup.com/。用户可以免费下载支持 CUDAFortran 编程的 PGI 开发工具套装的社区版本(Community Edition)。对应的还有收费的专业版本(Professional Edition)。PGI 是高性能计算编译器公司 Portland Group, Inc. 的简称,已被英伟达公司收购。
CUDA 提供了两层 API(Application Programming Interface,应用程序编程接口)给程序员使用,即 CUDA 驱动(driver)API 和 CUDA 运行时(runtime)API。
其中,CUDA 驱动 API 是更加底层的 API,它为程序员提供了更为灵活的编程接口;
CUDA 运行时 API 是在 CUDA 驱动 API 的基础上构建的一个更为高级的 API,更容易使用。
这两种 API 在性能上几乎没有差别。从程序的可读性来看,使用 CUDA 运行时 API 是更好的选择。在其他编程语言中使用 CUDA 的时候,驱动 API 很多时候是必需的。因为作者没有使用驱动 API 的经验,故本书只涉及 CUDA 运行时 API
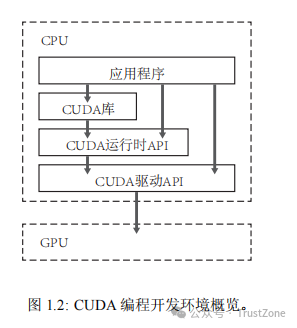
图 1.2 展示了 CUDA 开发环境的主要组件。开发的应用程序是以主机(CPU)为出发点的。
应用程序可以调用 CUDA 运行时 API、CUDA 驱动 API 及一些已有的 CUDA 库。所有这些调用都将利用设备(GPU)的硬件资源。
对 CUDA 运行时 API 的介绍是本书大部分章节的重点内容;第 14 章将介绍若干常用的 CUDA 库。
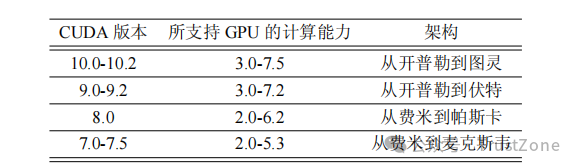
CUDA 版本也由形如 X.Y 的两个数字表示,但它并不等同于 GPU 的计算能力。
可以这样理解:CUDA 版本是 GPU 软件开发平台的版本,而计算能力对应着 GPU 硬件架构的版本。
CUDA 开发环境搭建示例
我们说过,GPU 计算实际上是 CPU+GPU(主机 + 设备)的异构计算。在 CUDA C++ 程序中,既有运行于主机的代码,也有运行于设备的代码。
其中,运行于主机的代码需要由主机的 C++ 编译器编译和链接。
所以,除了安装 CUDA 工具箱,还需要安装一个主机的 C++ 编译器。在 Windows 中,最常用的 C++ 编译器是 Microsoft Visual C++ (MSVC),它目前集成在 Visual Studio 中,所以我们首先安装 Visual Studio。
作者安装了最高版本的 Visual Studio 2019 16.x。因为这是个人使用的,故选择了免费的 Community 版本。下载地址为https://visualstudio.microsoft.com/free-developer-offers/。对于 CUDA C++ 程序开发来说,只需要选择安装 Desktop development with C++ 即可。当然,读者也可以选择安装更多的组件。
关于 CUDA,作者选择安装 2019 年 8 月发布的 CUDA Toolkit 10.1 update2。首先,进入网址 https://developer.nvidia.com/cuda-10.1-download-archive-update2。
然后根据提示,做如下选择:Operating System 项选择 Windows;Architecture 项选择 x86_64;Version 项选择操作系统版本,我们这里是 10;Installer Type 项可以选择 exe (network) 或者 exe (local),分别代表一边下载一边安装和下载完毕后安装。
接着,运行安装程序,根据提示一步一步安装即可。该版本的 CUDA 工具箱包含一个对应版本的 Nvidia driver,故不需要再单独安装 Nvidia driver。
安装好 Visual Studio 和 CUDA 后,进入到如下目录(读者如果找不到 C 盘下的 ProgramData 目录,可能是因为没有选择显示一些隐藏的文件):
C:ProgramDataNVIDIA CorporationCUDA Samplesv10.11_UtilitiesdeviceQuery
然后,用 Visual Studio 2019 打开文件 deviceQuery_vs2019.sln。接下来,编译(构建)、运行。若输出内容的最后部分为 Result = PASS,则说明已经搭建好 Windows 中的 CUDA 开发环境。若有疑问,请参阅 Nvidia 的官方文档:https://docs.nvidia.com/cuda/cuda-installation-guide-microsoft-windows。
在上面的测试中,我们是直接用 Visual Studio 打开一个已有的解决方案(solution),然后直接构建并运行。本书不介绍 Visual Studio 的使用,而是选择用命令行解释器编译与运行程序。
这里的命令行解释器指的是 Linux 中的 terminal 或者 Windows 中的 command prompt 程序。
在 Windows 中使用 MSVC 作为 C++ 程序的编译器时,需要单独设置相应的环境变量,或者从 Windows 的开始(start)菜单中找到 Visual Studio 2019 文件夹,然后单击其中的“x64 Native Tools Command Prompt for VS 2019”,而从打开一个加载了 MSVC 环境变量的命令行解释器。
在本书的某些章节,需要有管理员的权限来使用 nvprof 性能分析器。此时,可以右击“x64 Native Tools Command Prompt for VS 2019”,然后选择“更多”,接着选择“以管理员身份运行”。
用命令行解释器编译与运行 CUDA 程序的方式在 Windows 和 Linux 系统几乎没有区别,但为了简洁起见,本书后面主要以 Linux 开发环境为例进行讲解。虽然如此,Windows 和 Linux 中的 CUDA 编程功能还是稍有差别。我们将在后续章节中适当的地方指出这些差别。
用 nvidia-smi 检查与设置设备
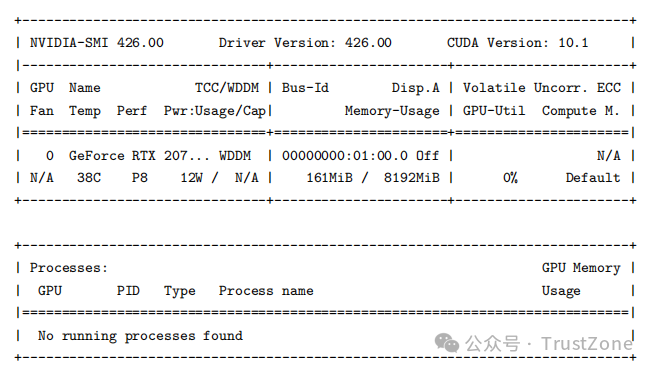
可以通过 nvidia-smi(Nvidia’s system management interface)程序检查与设置设备。
它包含在 CUDA 开发工具套装内。该程序最基本的用法就是在命令行解释器中使用不带任何参数的命令 nvidia-smi。
在作者的计算机中使用该命令,得到如下文本形式的输出:
从中可以看出一些比较有用的信息:
• 第一行可以看到 Nvidia driver 的版本及 CUDA 工具箱的版本。
• 作者所用计算机中有一型号为 GeForce RTX 2070 的 GPU。该 GPU 的设备号是 0。该计算机仅有一个 GPU。如果有多个 GPU,会将各个 GPU 从 0 开始编号。如果读者的系统中有多个 GPU,而且只需要使用某个特定的 GPU(比如两个之中更强大的那个),则可以通过设置环境变量 CUDA_VISIBLE_DEVICES 的值在运行 CUDA 程序之前选定一个 GPU。假如读者的系统中有编号为 0 和 1 的两个 GPU,而读者想在 1 号 GPU 运行 CUDA 程序,则可以用如下命令设置环境变量:
$ export CUDA_VISIBLE_DEVICES=1
这样设置的环境变量在当前 shell session 及其子进程中有效
• 该 GPU 处于 WDDM(windows display driver model )模式。另一个可能的模式是 TCC(tesla compute cluster),但它仅在 Tesla、Quadro 和 Titan 系列的 GPU 中可选。可用如下方式选择(在 Windows 中需要用管理员身份打开 Command Prompt 并去掉命令中的 sudo):
sudo nvidia-smi -g GPU_ID -dm 1 # 设置为 TCC 模式
这里,GPU_ID 是 GPU 的编号。
• 该 GPU 当前的温度为 38 摄氏度。GPU 在满负荷运行时,温度会高一些。
• 这是 GeForce 系列的 GPU,没有 ECC 内存,故 Uncorr. ECC 为 N/A,代表不适用(not applicable)或者不存在(not available)。
• Compute M. 指计算模式(compute mode)。该 GPU 的计算模式是 Default。在默认模式中,同一个 GPU 中允许存在多个计算进程,但每个计算进程对应程序的运行速度一般来说会降低。还有一种模式为 E. Process,指的是独占进程模式(exclusive processmode),但不适用于处于 WDDM 模式的 GPU。在独占进程模式下,只能运行一个计算进程独占该 GPU。可以用如下命令设置计算模式(在 Windows 中需要用管理员身份打开 Command Prompt 并去掉命令中的 sudo):
sudo nvidia-smi -i GPU_ID -c 1 # 独占进程模式
这里,-i GPU_ID 的意思是希望该设置仅仅作用于编号为 GPU_ID 的 GPU;如果去掉该选项,该设置将会作用于系统中所有的 GPU。
关于 nvidia-smi 程序更多的介绍,请参考如下官方文档:https://developer.nvidia.com/nvidia-system-management-interface。
CUDA 的官方手册
任何关于 CUDA 编程的书籍都不可能替代官方提供的手册等资料。以下是几个重要的官方文档,请读者在有一定的基础之后务必查阅。限于作者水平,本书难免存在谬误。当读者觉得本书中的个别论断与官方资料有冲突时,当以官方资料为标准(官方手册的网址为 https://docs.nvidia.com/cuda)。在这个网站,包括但不限于以下几个方面的文档:
• 安装指南(installation guides)。读者遇到与 CUDA 安装有关的问题时,应该仔细阅读此处的文档。
• 编程指南(programming guides)。该部分有很多重要的文档:– 最重要的文档是《CUDA C++ Programming Guide》,见以下网址:https://docs.nvidia.com/cuda/cuda-c-programming-guide。– 另一个值得一看的文档是《CUDA C++ Best Practices Guide》,见以下网址:https://docs.nvidia.com/cuda/cuda-c-best-practices-guide。– 针对最近的几个 GPU 架构进行优化的指南,包括以下网址:
https://docs.nvidia.com/cuda/kepler-tuning-guide。
https://docs.nvidia.com/cuda/maxwell-tuning-guide。
https://docs.nvidia.com/cuda/pascal-tuning-guide。
https://docs.nvidia.com/cuda/volta-tuning-guide。
https://docs.nvidia.com/cuda/turing-tuning-guide。
这几个简短的文档可以帮助有经验的用户迅速了解一个新的架构。
• CUDA API 手册(CUDA API references)。这里有:– CUDA 运 行 时 API 的 手 册:https://docs.nvidia.com/cuda/cuda-runtime-api。– CUDA 驱动 API 的手册:https://docs.nvidia.com/cuda/cuda-driver-api。– CUDA 数 学 函 数 库 API 的 手 册:https://docs.nvidia.com/cuda/cuda-math-api– 其他若干 CUDA 库的手册。
为明确起见,在撰写本书时,作者参考的是与 CUDA 10.2 对应的官方手册。
审核编辑:黄飞
-
gpu
+关注
关注
28文章
5271浏览量
136059 -
C语言
+关注
关注
183文章
7646浏览量
146126 -
编程语言
+关注
关注
10文章
1965浏览量
39859 -
C++
+关注
关注
22文章
2129浏览量
77360 -
CUDA
+关注
关注
0文章
128浏览量
14545
原文标题:一文讲清楚GPU 硬件与 CUDA 程序开发工具
文章出处:【微信号:处芯积律,微信公众号:处芯积律】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
使用开发工具和套件设计RF通信设备的开发系统
英飞凌MCU开发工具软件安装详解
嵌入式软件开发工具
GPU高性能运算之CUDA
SoPC应用设计的PLD开发工具要求详解
ARM开发工具解读
6个高效的前端开发工具
JavaScript开发工具有哪些?
硬件开发工具介绍




评论