 Stability AI推出Stable Video 3D模型,可制作多视角3D视频
Stability AI推出Stable Video 3D模型,可制作多视角3D视频
3月21日,Stability AI推出了全新的Stable Video 3D模型,此模型能够实现由单幅照片构建多视角3D视频。
SV3D_u是Stable Video 3D的一个版本,仅需单幅图片即可生成运动轨迹视频,无须进行相机调整。扩充版本的SV3D_p加入了轨道视图的特性,使其可以根据预设的相机路径创建3D视频。
与初始的Stable Zero123模型或者开源的Zero123-XL相比,Stable Video 3D具有更高的品质,实现更具丰富视图以及更强泛化能力的效果,能更加真实地展示出输入图片的完整三维形态。
Stability AI解释说,这种显著的提升得益于它的基础模型——Stable Video Diffusion。此外,Stable Video 3D还增加了相机路径调整功能,可以制作包围物体的各种轨道。
Stable Video 3D运用了多视角一致性的原则优化了3D NeRF和网格显示方式,这有助于提升直接从新视角生成的3D网格质量。
为了达到这个目的,Stability AI发明了一种名为“掩码分数蒸馏采样损失”的特殊技术,用以增强3D预测精度。同时,他们还改良了解混光源,降低了因光线造成的干扰,进一步优化了阴影表现。
Stability AI宣布,Stable Video 3D已经可以商业使用,只需支付相关费用成为其Stability AI会员(每月只需20美元)。如果是非商业需求,还可以在Hugging Face平台上免费下载模型权重。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
网格
+关注
关注
0文章
139浏览量
16069 -
3D模型
+关注
关注
1文章
72浏览量
15891 -
3D视频
+关注
关注
0文章
13浏览量
10031
发布评论请先 登录
相关推荐
英伦科技裸眼3D便携屏有哪些特点?
英伦科技裸眼3D便携屏采用了领先的光场裸眼3D技术,无需佩戴3D眼镜即可观看,给用户带来裸眼看3D视频的体验,为用户带来更加便捷和自由的视觉

腾讯混元3D AI创作引擎正式发布
的AI技术,能够根据用户提供的提示词或图片,直接生成高质量的3D模型。这一功能极大地降低了3D内容创作的门槛,使得即使是缺乏专业3D建模技能
腾讯混元3D AI创作引擎正式上线
或上传一张图片,该引擎便能迅速生成与之对应的3D模型。这一功能极大地降低了3D内容创作的门槛,使得更多用户能够轻松涉足这一领域。 除了基础的3D模型
中兴通讯全场景AI终端应用与裸眼3D新品亮相
”的产品战略与理念,终端业务六大AI主题展示吸引了众多关注,内容覆盖全球领先的AI裸眼3D、AI同声传译和方言互译、AI安全反诈、
发掘3D文件格式的无限潜力:打造沉浸式虚拟世界
在当今数字化时代,3D技术的应用范围日益广泛,涵盖电影后期制作、产品原型设计、虚拟现实(VR)、增强现实(AR)、游戏等众多领域。而3D文件格式作为3D技术的核心组成部分,对于实现
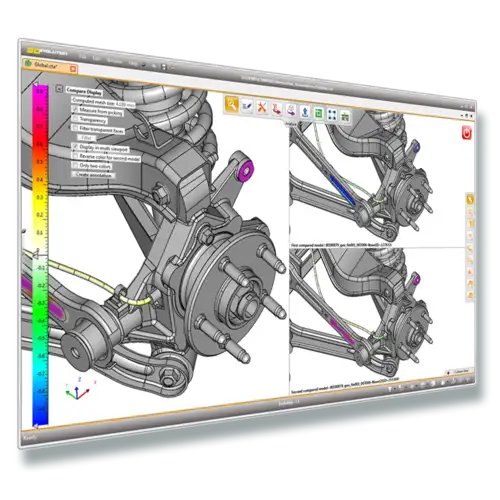
安宝特产品 安宝特3D Analyzer:智能的3D CAD高级分析工具
安宝特3D Analyzer包含多种实用的3D CAD高级分析工具,包括自动比对模型、碰撞检测、间隙检查、壁厚检查,以及拔模和底切分析,能够有效提升3D CAD
裸眼3D笔记本电脑——先进的光场裸眼3D技术
随着科技的不断进步,裸眼3D技术已经不再是科幻电影中的幻想。如今,英伦科技裸眼3D笔记本电脑将这一前沿科技带到了我们的日常生活中。无论你是专业的3D模型设计师,还是希望在
Meta推出革命性3D Gen AI模型:1分钟内生成高质量3D内容
在科技日新月异的今天,Meta再次引领创新潮流,宣布了一项令人瞩目的技术突破——3D Gen AI模型的诞生。这款先进的模型以其前所未有的高效性与卓越品质,重新定义了
包含具有多种类型信息的3D模型
、安全和高效的建筑系统,让居住者能够拥有可持续、弹性舒适且符合人体工程学的建筑。建筑信息模型
(BIM) 是建筑工程师在建筑物和其他结构设计中使用的一种3D建模过程。BIM软件提供了一个基于模
发表于 03-28 17:18
NVIDIA生成式AI研究实现在1秒内生成3D形状
NVIDIA 研究人员使 LATTE3D (一款最新文本转 3D 生成式 AI 模型)实现双倍加速。

Stability AI发布Stable Code Instruct 3B大语言模型,可编译多种编程语言
据报道,Stability AI公司近期推出了适配程序员使用的Stable Code Instruct 3B大语言
Adobe Substance 3D整合AI功能:基于文本生成纹理、背景
Substance 3D Stager是以Adobe Dimension为基础改造而成,使用者可直观地进行3D场景构建,包括模型、材质和灯光等要素。借助其强大功能,能够生成极具观赏性的
裸眼3D频频“出圈” 电信积极布局并发力裸眼3D领域
随着科技的发展,现在3D视角已经不是新鲜事。而现在,裸眼3D应用则也在频频“出圈”。特别是在5G的助力下,裸眼3D技术应用更是成为科技圈一个热点。





 工商网监
工商网监
评论