 B200一经面市,就只能做弟弟?Cerebras '巨无霸'能否逆袭成功?
B200一经面市,就只能做弟弟?Cerebras '巨无霸'能否逆袭成功?
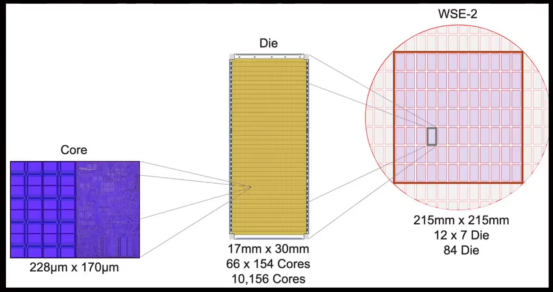
Cerebras Systems 发布全球最大芯片 WSE3 搭载4万亿个晶体管。与英伟达 B200 GPU 的2080亿晶体管相比较,WSE3 的规模宛如巨人面对侏儒。其打破常规,不再将一个晶圆切割为多个单独芯片,而是巧妙地将一整个12英寸的晶圆转化为一块庞大芯片,总面积达到 46225 平方毫米,相当于84个常规芯片组合在一起。

Cerebras 自2015年成立以来,坚持不懈地推出一系列 WSE 芯片,到如今第三代 WSE3,每一步都标志着其对制程工艺的深化掌握,这次更是采用了5纳米工艺,承台积电的技术优势。WSE系列以“世界最大芯片”而驰名,专注于满足AI大模型训练的高性能需求,同时具备出色的推理能力。在这一领域,Cerebras 不仅自立门户,更与高通展开合作,以其推理芯片进一步增强WSE3功能范畴。
WSE3发布还伴随一系列承载其强劲计算力的服务器产品——CS1、CS2和CS3,这些服务器产品由AMDCPU赋能,共同构成高效的计算生态,旨在加速现代AI研究及实用性能向前迈进。
凭借其独特的设计理念和规模优势,WSE3预示着 AI 硬件技术的一次飞跃。异常强大的算力背后,是Cerebras对芯片工艺的极致追求与不被常规限制的创新胆识,WSE3正将这份精神通过每一次AI模型的训练和推理,传递至整个科技行业。
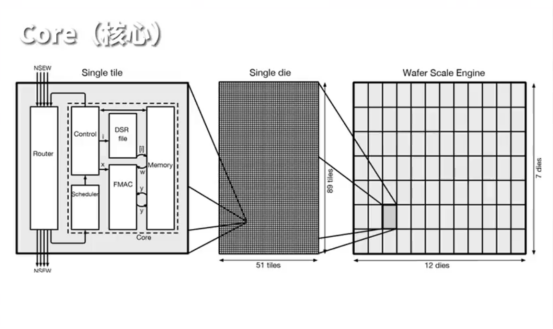
尽管有些人可能怀疑 WSE3 不过是一张巨型晶圆,但其真正的价值并不在于其体积,而在于其背后独特的设计理念和架构。WSE3 构造包括84个区域,其中包含高达90万个计算核心,每个区域内含有超过1万个核心。从架构层面来看,由核心(Cores)、芯片单元(Die)以及晶圆(Wafer)共同构成。
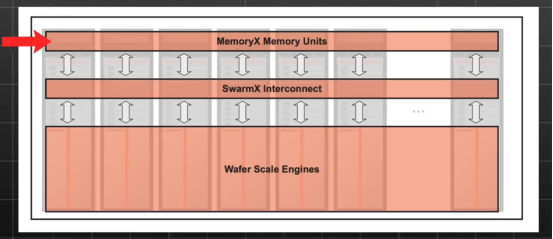
Cerebras的计算架构大致可以划分为WSE、SwarmX 和 MemoryX三个部分。在处理大模型训练时,MemoryX存储设备储存权重数据,这些数据由DDR和Flash技术共同构成,最大提供高达1200TB存储空间。该设计意味着巨大数量级的模型参数可以一次性加载到设备中进行处理。在训练过程中,MemoryX上的权重数据将通过SwarmX传输至每个CS系统中的WSE,由WSE处理数据并完成向前传播计算过程,生产出预测值。然后,通过损失函数计算出预测值与真实值间的梯度,用这些梯度进行反向传播计算所有权重的梯度。计算得出的梯度数据随后回到SwarmX,经过汇总处理为全局梯度后送回MemoryX,MemoryX内的计算单元会直接更新权重,为下一轮的训练做准备。
Cerebras Systems把一个晶圆的全部晶体管都用上,并未按常规将其切割,而是构建一个具有90万个计算核心的密集网络进行集中处理。松散耦合的计算和存储设计让 Cerebras 的 CS 系列服务器能够轻松实现数据并行,不使用其他复杂的并行训练方法。Cerebras 这一独特设计理念使其成为AI 训练领域的强劲竞争者。
深入探究Cerebras革命性 WSE 芯片会发现,每一颗计算核心都拥有一块48KB的SRAM存储单元。令人惊讶的是48KB被巧妙划分为八个6KB小区域,每个小区以32位宽数据通道进行操作,合起来就是一条256位宽数据高速公路。计算核心在每一个时钟周期都能够处理高达两个64位的读取通道以及一个64位的写入通道,合计可达192位。
Cerebras的真正威力还在于它的分布式存储与计算架构,使之擅长高效解决非结构化的稀疏计算问题,尤其是那些需要处理海量零值或接近零值数据的场景。为此,WSE3 提供令人震撼的 21PB每秒的片上存储带宽,以及超乎想象的214PB每秒的网络交互带宽。
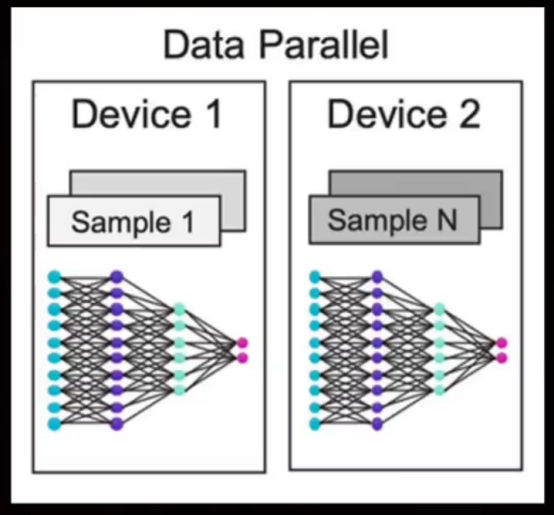
Cerebras的设计理念深入人心,无需切割晶圆,就将所有晶体管整合成一个紧密相连的网络,该网络由高达90万个计算核心组成,实现集中加工处理。与此同时,Cerebras系列的CS服务器得益于计算与存储分离的创新设计,轻松实现数据并行处理,省去其他复杂并行训练方案的需要。这一设计不光为Cerebras赢得了与英伟达抗衡的实力,也为面对越来越庞大的模型规模——我们说的是达到万亿级参数——提供解决方案。在AI训练领域,Cerebras的 Wafer Scale Engine 设计无疑是它的巅峰时刻。
审核编辑 黄宇
-
芯片
+关注
关注
455文章
50851浏览量
423871 -
晶体管
+关注
关注
77文章
9698浏览量
138243 -
AI
+关注
关注
87文章
30946浏览量
269186
发布评论请先 登录
相关推荐
北美运营商AT&T认证中的VoLTE测试项

北美运营商AT&amp;amp;T认证的费用受哪些因素影响

NVIDIA DGX B200首次面向零售市场:配备8块B200 GPU
onsemi LV/MV MOSFET 产品介绍 &amp;amp; 行业应用

无人驾驶遇上&apos;超级WiFi&apos;,低速无人驾驶已成为了主要趋势?

FS201资料(pcb &amp; DEMO &amp; 原理图)
解读北美运营商,AT&amp;amp;T的认证分类与认证内容分享
特斯拉加码AI布局:xAI将采购30万块英伟达B200芯片
英特尔任命Kevin O&apos;Buckley为代工部门负责人
智向未来,2024高通&amp;广和通边缘智能技术进化日成功举办

英伟达发布新一代AI芯片B200
英伟达发布性能大幅提升的新款B200 AI GPU
C程序中可用的存储类有哪些?
深维科技-北京大学合作团队在FPGA&apos;24布线加速竞赛中夺得佳绩!






 工商网监
工商网监
评论