 Achronix新推出一款用于AI/ML计算或者大模型的B200芯片
Achronix新推出一款用于AI/ML计算或者大模型的B200芯片
近日举办的GTC大会把人工智能/机器学习(AI/ML)领域中的算力比拼又带到了一个新的高度,这不只是说明了通用图形处理器(GPGPU)时代的来临,而是包括GPU、FPGA和NPU等一众数据处理加速器时代的来临,就像GPU以更高的计算密度和能效胜出CPU一样,各种加速器件在不同的AI/ML应用或者细分市场中将各具优势,未来并不是只要贵的而是更需要对的。
此次GTC上新推出的用于AI/ML计算或者大模型的B200芯片有一个显著的特点,它与传统的图形渲染GPU大相径庭并与上一代用于AI/ML计算的GPU很不一样。在其他算力器件品种中也是如此,AI/ML计算尤其是推理应用需要一种专为高带宽工作负载优化的新型FPGA,下面我们以Achronix的Speedster7t FPGA芯片为例来看看技术的演进方向,以及在实际推理应用中展现出来的在性价比和能效比等方面优于先进GPU的特性。
先来快速看看Speedster7t的产品亮点:该器件集成了800K到1500K等效逻辑单元以及326K到692K 6输入查找表(LUT),高达120T算力的机器学习处理单元(MLP),同时还配备了高性能存储和I/O接口,以及最高可达190Mb的嵌入式存储容量。在外部连接接口部署上,Speedster7t包含16个GDDR6通道,可提供高达4 Tbps的高速存储带宽;32对SerDes通道,支持1-112Gbps的数据速率;4个400G以太网端口(4× 400G或16× 100G)和2个PCIe Gen5端口,支持16通道(×16)和8通道(×8)配置。
Achronix的Speedster7t FPGA芯片被用户认为非常适合AI/ML推理原因是:足够的算力,灵活可配的计算精度;高带宽大容量低成本的GDDR6(4Tbps带宽, 32GB容量);革命性的全新二维片上网络(2D NoC)路由架构;灵活通用的芯片间互联;支持用户基于该芯片开发自定义的推理系统,比如单板多片FPGA甚至多板互联以组成更高性能(如1TBbps/64GB,2TBbps/128GB, 4TBbps/256GB…等更高带宽和更大容量的计算存储)以支持更大或超大模型推理部署。
简而言之,相比传统的推理算力平台,Speedster7t FPGA可以提供更高性价比和能耗比的大模型推理能力;另外,在传统的FPGA处理功能中,越来越多的用户在该系统中加入机器学习的能力, Speedster7t FPGA能很好胜任传统FPGA功能和高性能机器学习融合在一起。
一类创新性的高性能FPGA系列产品
Achronix Speedster7t系列FPGA基于革命性的FPGA架构,该架构经过了高度优化提供了高速、高带宽内外连接,可以满足日益增长的人工智能/机器学习、网络密集型和数据加速应用的需求。Speedster7t系列FPGA芯片具有一个革命性的全新二维片上网络,以及一个针对人工智能/机器学习进行优化的高密度的机器学习处理单元阵列。通过将FPGA的可编程性与类似ASIC路由架构和计算引擎相结合,Speedster7t系列提高了高性能FPGA的标准。
全新的二维片上网络(2D NoC)提供ASIC级别的性能
Speedster7t系列FPGA芯片具有革命性的2D NoC,可在整个FPGA逻辑阵列中传输数据,并将数据传输到高性能I/O和内存子系统,同时可提供高达20 Tbps的总带宽。凭借2D NoC,在Speedster7t FPGA芯片不需要消耗任何可编程逻辑资源的情况下来进行数据传输。在该芯片上的2D NoC提供了20 Tbps的二维片上网络总带宽;该2D NoC不仅覆盖了芯片全域,而且还连接到各类高速接口和总带宽高达4 Tbps的高速存储接口。
高速接口
无论是支持输入和输出的数据流,还是存储缓冲这些数据,对于高性能计算、机器学习和硬件加速解决方案而言,都需要在片内和片外传输数据。Speedster7t系列FPGA芯片的架构可支持前所未有的带宽。包括:
400G以太网:Speedster7t系列FPGA芯片支持多达4个400GbE端口或16个100GbE端口,通过2D NoC连接到FPGA逻辑。
PCI Express Gen5:Speedster7t系列FPGA芯片配备了多个PCle Gen5接口,支持速率达32GT/s。
存储接口:GDDR6 + DDR4/5
Speedster7t器件是唯一在片上支持GDDR6存储器的FPGA,以最低的DRAM成本(每存储位)提供最快的SDRAM访问速度。Speedster7t系列FPGA芯片具有高达4 Tbps的GDDR6带宽,以很低的成本就可提供相当于基于HBM的FPGA存储器带宽。Speedster7t系列FPGA芯片包括了DDR4/5存储器接口,以支持更深入的缓冲需求。PHY和控制器支持由JEDEC规范定义的所有标准功能。
机器学习处理单元
每个Speedster7t FPGA器件都具有可编程的数学计算单元,这些单元被集成至全新的机器学习处理单元(MLP)模块中。每个MLP都是一个高度可配置的计算密集型模块,具有多达32个乘法器/累加器(MAC),支持4到24位整数格式和各种浮点模式,包括Tensorflow的bfloat16格式以及高效的块浮点格式,大大提高了性能。
MLP模块包括紧密集成的嵌入式存储器模块,以确保机器学习算法将以750 MHz的最高性能运行。这种高密度计算和高性能数据传输的结合造就了高性能机器学习处理结构,该结构可提供市场上基于FPGA的极高TOPS级别运算能力(TOPS即Tera-Operations Per Second,每秒万亿次运算)。
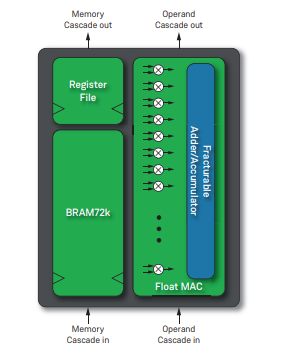
图中文字说明:Register File - 寄存器文件,Fracturable Adder/Accumulator - 可拆分的加法器/累加器,Float MAC - 浮点乘累加单元(MAC),Memory Cascade in - 存储器级联,Operand Cascade in - 操作数级联。 设计工具支持
Achronix Tool Suite工具套件是一个支持所有Achronix硬件产品的工具链。它可与行业标准的逻辑综合和仿真工具结合使用,从而使FPGA设计人员能够轻松地将其设计映射到Speedster7t FPGA器件中。Achronix Tool Suite工具套件包括Synopsys的Synplify Pro的优化版本和Achronix Snapshot调试器。Achronix仿真库由Siemens EDA的ModelSim、Synopsys的VCS和Aldec的Riviera-PRO提供支持。
展望:在推理等领域帮助开发者打造综合性能优于先进GPU的应用
随着AI/ML技术在各个领域开始广泛走进应用,Achronix根据Speedster7t FPGA器件的高性能和高带宽特性,选择了推理这一个应用面非常广的技术市场方向,与合作伙伴加大了在Speedster7t FPGA器件上的推理算法和IP的研发,以期帮助更多的创新者实现突破。
该芯片提供了足够的算力,并利用其片上搭载的二维片上网络(2D NoC)和机器学习处理单元(MLP),各种高速接口和GDDR6高带宽存储接口,提供了用于大规模推理应用需要的计算器件内外连接、硬件加速和存储调用等新技术,从而可以支持开发者快速去实现创新。
这个策略取得了显著的成果,其中一个领域是加速自动语言识别(ASR)解决方案,它由搭载Speedster7t FPGA器件的VectorPath加速卡提供支持,运行Myrtle.ai提供的基于Achronix FPGA的ASR IP,从而提供业界领先的、实时的、超低延迟的语音转文本功能。运行在服务器中的单张VectorPath加速卡可替代多达20台仅基于CPU的服务器或10张GPU加速卡。
Speedster7t FPGA的技术创新为人工智能推理带来了更高性价比和更高能效比以及可以让用户开发自定义的推理硬件平台和系统。 在ASR实际性能方面,其出色的超低单词错误率和仅有最先进GPU解决方案八分之一以下的端到端延迟(包括了预处理和后处理以及与CPU做数据交互的时间)颠覆了ASR领域。该解决方案可以在标准的机器学习框架中使用垂直应用特定的或自定义的数据集进行定制或重新训练。
对于越来越多的其他的推理应用,Speedster7t FPGA的独创高带宽架构也可以为这些应用提供有力的支撑。Achronix正在通过不断研发,以完善其工具链和应用生态,将在2024年推出更好的工具来帮助各种推理应用的开发,使众多的用户更加便捷地使用Speedster7t FPGA器件或者VectorPath加速卡来实现性价比和能效提升,而不用去争抢紧俏的高性能GPU加速卡。
审核编辑:刘清
-
人工智能
+关注
关注
1792文章
47445浏览量
239053 -
图形处理器
+关注
关注
0文章
198浏览量
25600 -
机器学习
+关注
关注
66文章
8428浏览量
132807 -
FPGA器件
+关注
关注
1文章
22浏览量
11629 -
GDDR6
+关注
关注
0文章
52浏览量
11325
原文标题:新型的FPGA器件将支持多样化AI/ML创新进程
文章出处:【微信号:Achronix,微信公众号:Achronix】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
亚马逊转向Trainium芯片,全力投入AI模型训练
NVIDIA DGX B200首次面向零售市场:配备8块B200 GPU
基于Achronix Speedster7t FPGA器件的AI基准测试
Mistral AI与NVIDIA推出全新语言模型Mistral NeMo 12B
特斯拉加码AI布局:xAI将采购30万块英伟达B200芯片
进一步解读英伟达 Blackwell 架构、NVlink及GB200 超级芯片
人工智能模型公司Anthropic近日推出了一款Claude移动端App
日本Sakura互联网投资英伟达B200芯片 助力AI计算及数据中心发展
新型的FPGA器件将支持多样化AI/ML创新进程
英伟达H200性能显著提升,年内将推出B200新一代AI半导体
英伟达发布新一代AI芯片B200
英伟达发布性能大幅提升的新款B200 AI GPU
戴尔发布英伟达B200 AI GPU:高功耗达1000W,创新性冷却工程设计必要
字节跳动推出一款颠覆性视频模型—Boximator
Stability AI推出迄今为止更小、更高效的1.6B语言模型






 工商网监
工商网监
评论