 英特尔集成显卡+ChatGLM3大语言模型的企业本地AI知识库部署
英特尔集成显卡+ChatGLM3大语言模型的企业本地AI知识库部署

前言
在当今的企业环境中,信息的快速获取和处理对于企业的成功至关重要。为了满足这一需求,我们可以将RAG技术与企业本地知识库相结合,以提供实时的、自动生成的信息处理和决策支持。这将有助于企业更好地应对快速变化的市场环境,提高企业的竞争力和创新能力。
企业本地知识库是一个集中存储和管理企业内部知识的系统。它包含了企业的历史数据、经验教训、最佳实践、流程文档、产品信息等。企业本地知识库是企业智慧的结晶,对于企业的运营和发展具有重要意义。
将RAG技术与企业本地知识库相结合,可以为企业带来以下几个方面的优势:
1
实时性
RAG技术可以实时地从企业本地知识库中提取相关信息,并生成用户所需的内容。这意味着用户可以快速地获取到最新的知识和信息,而不需要花费大量时间去查找和整理。
2
自动化
RAG技术可以自动地处理和生成内容,减少了人工干预的需求。这不仅可以提高企业的效率,还可以减少人为错误的发生。
3
个性化和定制化
RAG技术可以根据用户的需求和偏好,生成个性化的内容。通过与企业本地知识库的结合,可以提供更加精准和有针对性的信息,满足不同用户的需求。
4
知识共享和传承
企业本地知识库是一个集中存储和共享知识的平台。通过与RAG技术的结合,可以将这些知识快速地传递给需要的用户,促进知识的共享和传承。
1
RAG简介
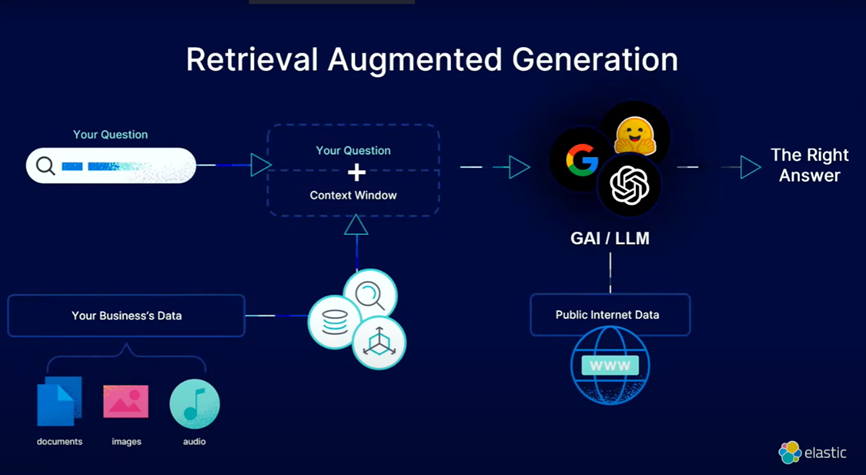
RAG - Retrieval-Augmented Generation(检索增强生成)是一种先进的自然语言处理(NLP)技术,它结合了信息检索(Retrieval)和神经网络生成(Generation)两种方法,以提升模型在生成文本时的准确性和相关性。在传统的生成模型中,模型依据自身学习到的知识库生成文本。然而,这种方法受限于模型训练时所接触到的数据范围,特别是在处理未见的、需要实时查找新信息的场景时,可能无法生成最新或最准确的内容。
RAG模型通过引入一个检索组件,在接收到输入问题或任务后,首先从大规模预定义的知识库(如网页、文档集合或其他结构化/非结构化数据源)中检索与任务相关的信息片段。然后,检索到的信息作为额外的上下文输入,与原始输入一起传递给生成模型。生成模型在此基础上,利用检索到的信息以及自身的语言模型能力,生成更为精确、详尽且与现实世界信息保持同步的回答或文本内容。
简单来说,RAG模型就是在传统生成模型的基础上增加了一个动态获取外部知识的能力,这样既保留了大模型生成连贯文本的优点,又解决了由于模型记忆限制导致的知识更新和准确性不足的问题,尤其适用于问答系统、对话系统及需要实时更新信息的自然语言处理任务。
2
OpenVINO Notebook简介
OpenVINO Notebooks是一套以Jupyter Notebook为载体的开源交互式编程教程和示例代码合集,由英特尔公司开发和维护。这套资源专为使用 OpenVINO 工具套件的开发者设计,旨在帮助他们更快地理解和掌握如何利用 OpenVINO 进行深度学习模型的优化与推理及实际部署AI在各式业务应用场景里面。
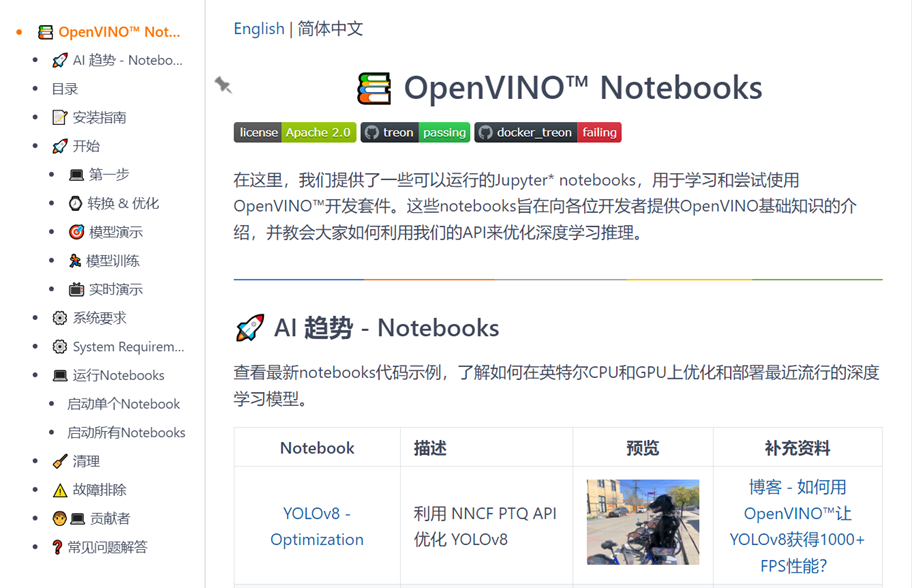
3
部署平台简介
算力魔方是一款可以DIY的迷你主机,采用了抽屉式设计,后续组装、升级、维护只需要拔插模块。通过选择计算模块的版本,再搭配不同额 IO 模块可以组成丰富的配置,适应不同场景。性能不够时,可以升级计算模块提升算力, 如需要显卡可加上显卡, IO 接口不匹配时,可以更换 IO 模块调整功能,而无需重构整个系统。本文在带有英特尔12代酷睿i7-1265U芯片组里的锐炬 Xe集成显卡+RAM 32GB的算力魔方上完成验证。
4
在集成显卡上部署RAG
4.1
搭建OpenVINO Notebooks开发环境
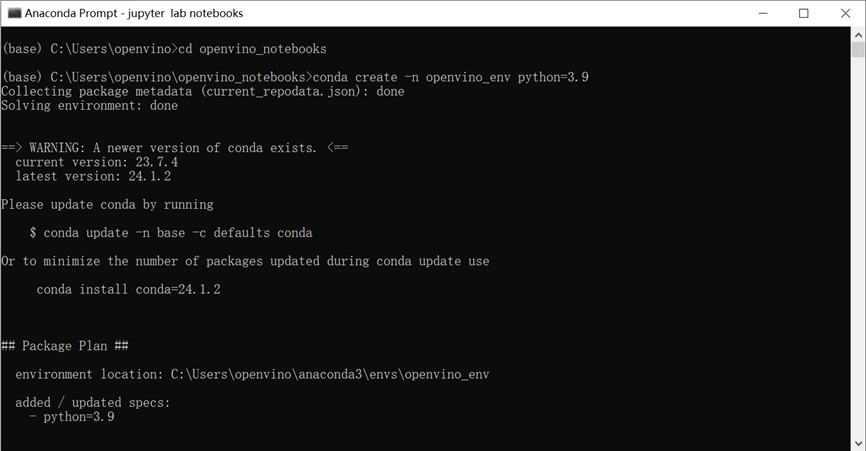
第一步:请使用下面的命令克隆存储库创建并激活名为“openvino_env”的虚拟环境
git clone https://github.com/openvinotoolkit/openvino_notebooks.git cd openvino_notebooks conda create -n openvino_env python=3.9
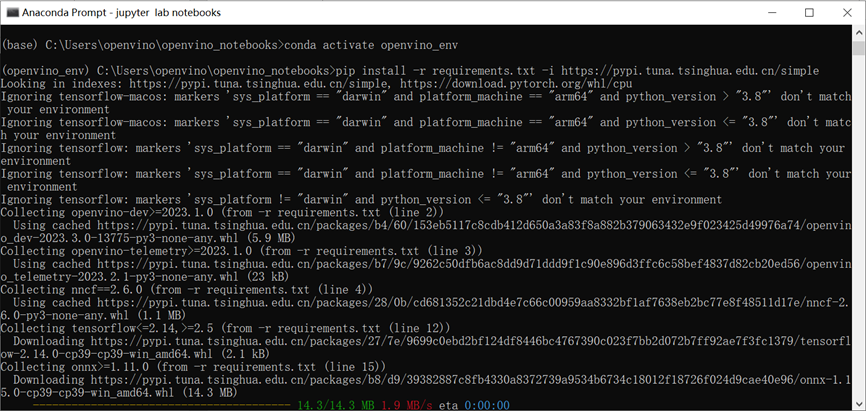
第二步:请使用下面的命令激活虚拟环境并安装依赖包,并启动Jupyter Notebooks
conda activate openvino_env pip install -r requirements.txt
jupyter lab notebooks
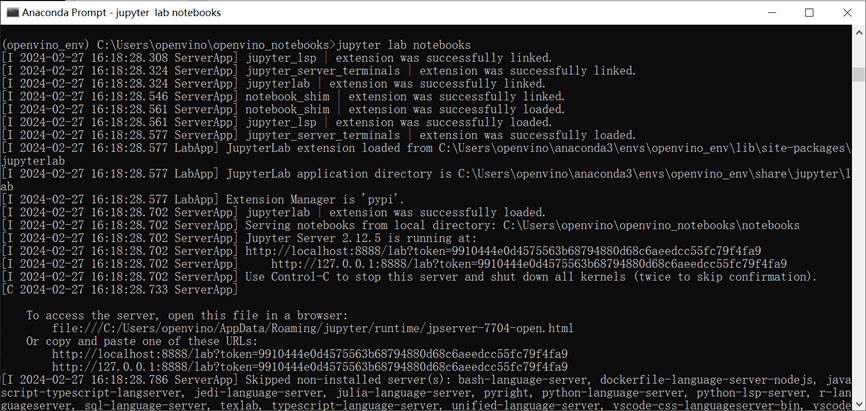
4.2
下载模型到本地
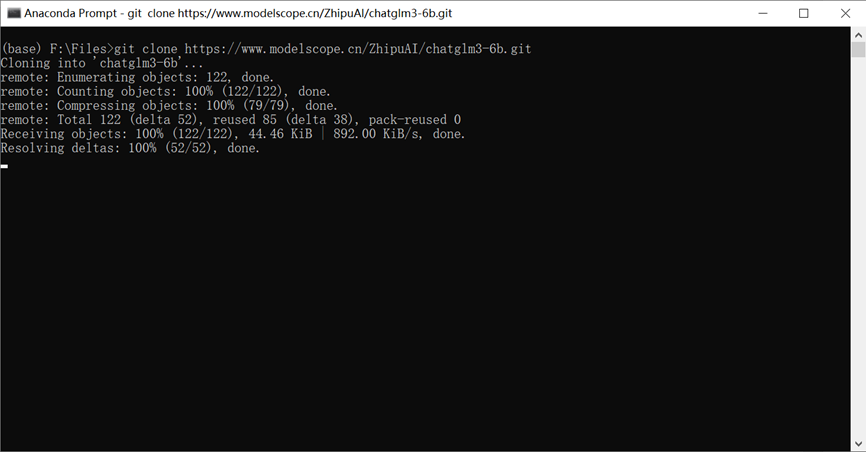
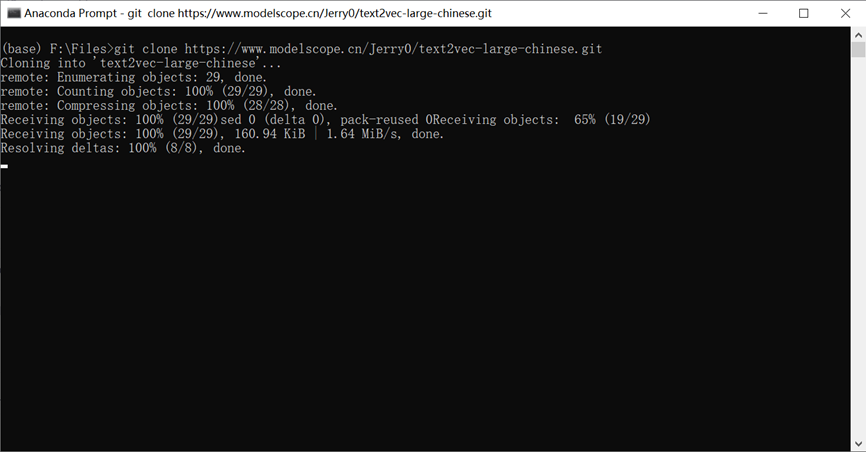
请使用命令将ChatGLM3 6B和text2vec模型下载到本地
git clone https://www.modelscope.cn/ZhipuAI/chatglm3-6b.git
git clone https://www.modelscope.cn/Jerry0/text2vec-large-chinese.git
4.3
运行254-rag-chatbot程序
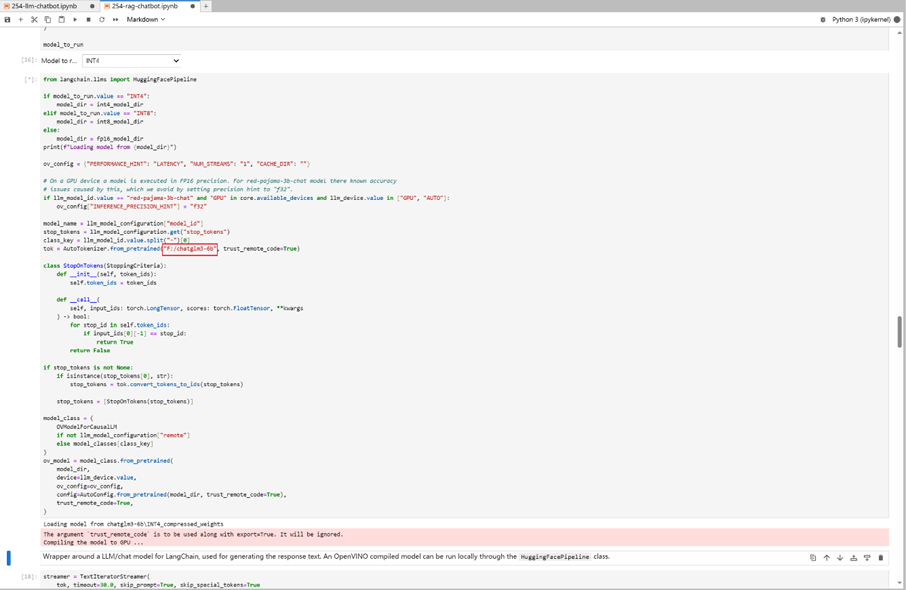
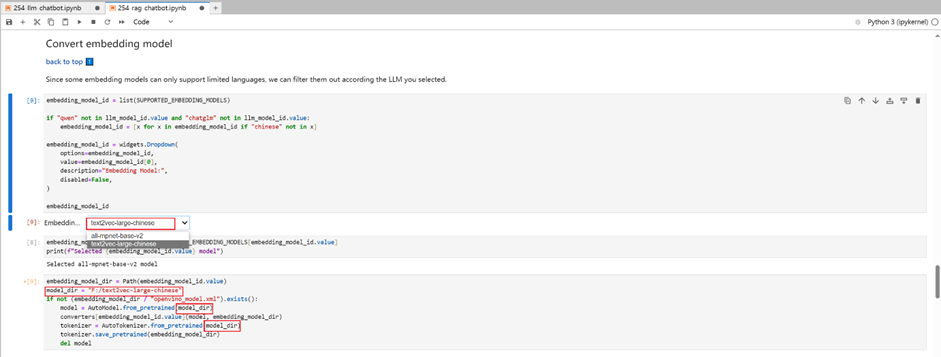
请运行Notebooks里面的代码模块, 注意!! 国内用户请勿运行模块1,从模块2开始一步步运行代码到NNCF模块,模型压缩选择int4并按照下图一及二图修改notebooks 254里的代码引导程序指定对应的模型路径完成ChatGLM3-6b模型int 4量化及部署
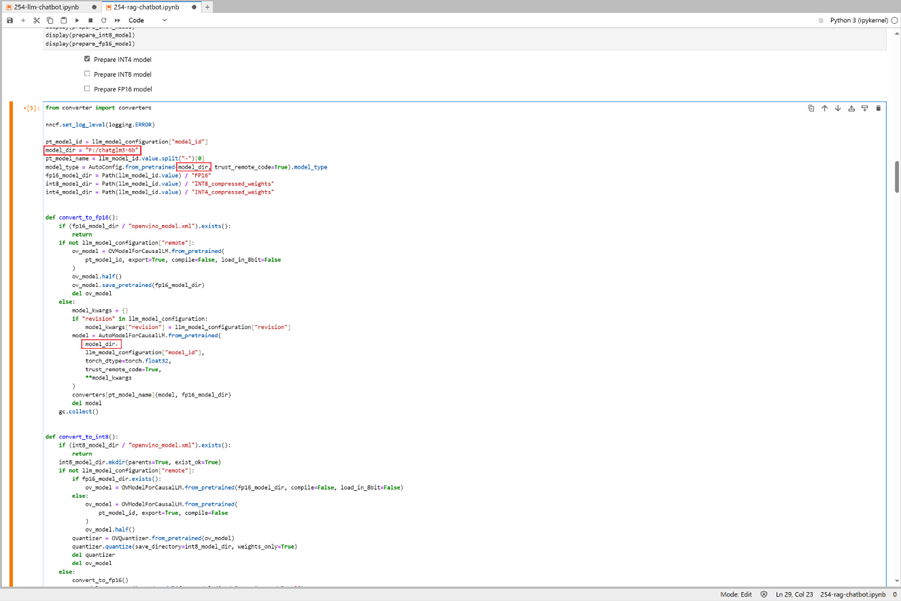
图一
图二
text2vec-large-chinese 模型部署
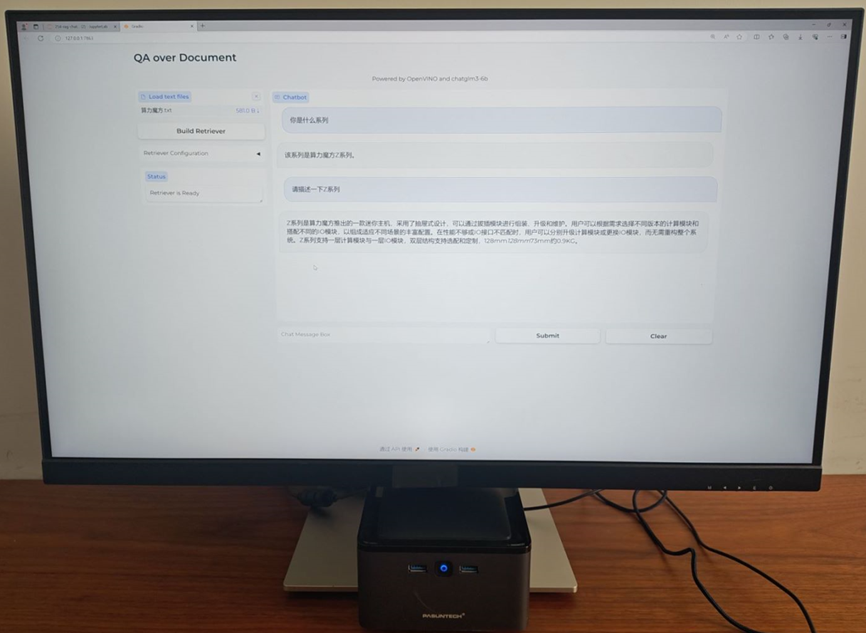
运行结果,如下所示:本地知识库已成功加入ChatGLM 6B模型里并精确回答问题
运行视频.avi
5
总结
将RAG技术与企业本地知识库相结合,可以为企业提供实时、自动化、个性化和定制化的信息处理和决策支持。这将有助于企业更好地应对快速变化的市场环境,提高企业的竞争力和创新能力。
利用OpenVINO 工具套件简单易用,仅需三步即可在算力魔方完成开发环境搭建及模型的INT4量化且在英特尔集成显卡上的部署实现RAG企业本地知识库部署。
审核编辑:刘清
-
英特尔
+关注
关注
61文章
10340浏览量
181323 -
深度学习
+关注
关注
73文章
5614浏览量
124748 -
大模型
+关注
关注
2文章
3862浏览量
5295 -
OpenVINO
+关注
关注
0文章
118浏览量
829
原文标题:英特尔集成显卡+ChatGLM3大语言模型的企业本地AI知识库部署 | 开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
瑞芯微(EASY EAI)RV1126B AI模型转换

AI工作站本地养龙虾!英特尔双芯混合算力,告别云端Token焦虑

AI大模型微调企业项目实战课
鸿蒙智能体开发知识库---创建知识库
在AI基础设施中部署大语言模型的三大举措

英特尔开发者年度盛会智潮涌动,推动AI创新走向产业纵深
英特尔创新引领AI NAS:软硬结合引领本地数据智慧管理与多场景创新应用

发力图形工作站和AI推理市场,英特尔大显存GPU亮相湾芯展

本地部署openWebUI + ollama+DeepSeek 打造智能知识库并实现远程访问

英特尔可变显存技术让32GB内存笔记本流畅运行Qwen 30B大模型
硬件与应用同频共振,英特尔Day 0适配腾讯开源混元大模型
主控CPU全能选手,英特尔至强6助力AI系统高效运转

英特尔发布边缘AI控制器与边缘智算一体机,创造“AI新视界”

英特尔锐炫Pro B系列,边缘AI的“智能引擎”




评论