 如何通过优化RTL减少功耗
如何通过优化RTL减少功耗
随着各种消费类设备智能化的巨大增长,这些应用正变得更加以数据为中心data-centric和计算密集型computation intensive。从IC设计的角度来看,这增强了早已经存在的power vs area trade-off的挑战。
对于功耗估算来说,架构阶段为时过早,物理设计阶段为时已晚。有一种趋势是在项目的RTL阶段分析power hot spots。与后期分析相比,基于 RTL 的功耗分析更快、更容易执行,迭代时间更短。
本文介绍了在 RTL 级别应用的一些功耗优化技术。
消费类电器(电池驱动型)的大幅增加使功耗优化成为大多数片上系统 (SoC) 的基本需求。
在VLSI行业的早期阶段,功耗分析被认为是一种后端活动。但随着芯片复杂性的增加,必须将功耗分析转移到前端阶段,以确保正确的估计和优化,仅在后端阶段进行优化就无法满足要求。
此外,动态功耗计算很大程度上取决于驱动到 SoC 的输入激励;因此,使用功能验证向量输入进行分析似乎是必须的。因此,业界开始在 RTL 阶段进行功耗分析。
在ASIC设计的不同阶段,都有功耗优化的余地。
系统划分为电压域是在架构阶段完成的,即使在单个电压域下也能进行优化。当处理器处于休眠模式时,对电路进行Power gating(唤醒逻辑除外)可减少功耗浪费。这些是用于降低功耗的一些传统方法。在多核处理器设计中,多个电压域允许根据工作负载控制每个内核的电源电压。在较高电压下工作的核以较高的频率工作,而施加较低电压的核可以使用较低的频率。
内存组织和模块级时钟门控则是架构级优化的另一个领域。
综合阶段的功耗降低归因于晶体管尺寸调整和cell合并,以降低开关活动。另一种方法是将高开关活动的net分配给电容较低的引脚,将低开关活动的net分配给具有较高电容的逻辑引脚。综合工具还通过将数据使能转换为时钟使能来实现时钟门控。通过具有不同阈值电压的cell映射设计中的非关键路径和关键路径来优化漏电功耗。
RTL level的功耗优化主要集中在降低register level的信号活动上。本文主要介绍 RTL 优化,它从更精细的级别实现功耗的优化控制。
II. 低功耗RTL
通常,实现 RTL 功耗优化包括对设计的以下方面进行优化。
寄存器级时钟门控减少开关活动
基于有限状态机(FSM)的上游和下游逻辑路径门控
数据路径未启用时对数据路径进行门控
减少组合电路中的冗余活动
本节介绍一些优化技术,方案和编码示例。
A. 时钟门控
在模块级别插入Clock gate是一种普遍的降低功耗的方法。但是,只有在功耗需求非常严格的情况下,才采用寄存器级的Clock gate,这是由于寄存器级的Clock gate也会增加面积成本。
为了在寄存器级别启用Clockgate,对于RTL的编写方式是有一定的要求的。另一种选择是手动配置综合工具,为选定的寄存器插入Clockgate。在复杂的设计中,第二种选择是不可行的。在这种情况下,应该利用RTL 的编写方式自动综合出Clockgate。
考虑场景,当 FIFO 满并写入时,生成 fifo wr 错误信号。示例代码1不会综合出Clock gate,而示例代码2会综合出Clock gate。
Listing 1. Code without CG Inference
always @(posedge clk or negedge reset) if (reset = 0) fifo_wr_err <= 0 else fifo_wr_err <= fifo_full & fifo_wr_en ;
Listing 2. Code with CG Insertion
always @(posedge clk or negedge reset) if (reset = 0) fifo_wr_err <= 0 else if (fifo_wr_en) fifo_wr_err <= fifo_full;
1) 时钟门控效率:在不研究时钟门控效率的情况下插入Clockgate也可能会反方向增加功耗。需要根据以下因素估计时钟门控效率
总线中被时钟门控的比特数
门控占总时钟周期的百分比
数据在使能的Clockgate内toggle
仅当寄存器上的输入发生变化时才启用该门控。
Listing 3. Improved Clock Gating Efficiency
always @(posedge clk or negedge reset) if (reset = 0) fifo_wr_err <= 0 else if (value_en) fifo_wr_err <= nxt_fifo_wr_err; assign nxt_fifo_wr_err = fifo_full & fifo_wr_en; assign value_en = fifo_wr_err ˆ nxt_fifo_wr_err;
2) Clock Gating TradeOff:当我们努力实现 100% 的时钟门控效率时,系统的面积将会增加。为了避免这种情况,我们可以TradeOff。在这里,我们组合了多个寄存器的使能,允许触发器输入处会有些冗余切换。这种TradeOff的默认值的建议是 3-4,这意味着在 3-4 个寄存器之间共享一个公共enable,但代价是Clock Gating效率降低。
写入错误和读取错误生成enable可以组合使用,以降低面积成本。
Listing 5. Combined Clock Gating Example 2
always @(posedge clk or negedge reset) if (reset = 0) fifo_wr_err <= 0 else if (fifo_en) fifo_wr_err <= nxt_fifo_wr_err; always @(posedge clk or negedge reset) if (reset = 0) fifo_rd_err <= 0 else if (fifo_en) fifo_rd_err <= nxt_fifo_rd_err; assign nxt_fifo_wr_err = fifo_full & fifo_wr_en; assign nxt_fifo_rd_err = fifo_empty & fifo_rd_en; assign fifo_en = fifo_wr_en | fifo_rd_en;
B. 基于FSM的控制
基于FSM状态生成的信号可用于对发送和接收的所有逻辑进行门控。
Listing 6. Enable Generation based on FSM
assign transmit_cg_en = ˜state_tx[IDLE]; assign receive_cg_en = ˜state_rx[IDLE];
C. 数据路径运算
数据路径运算模块(如乘法器)可能会在输入端进行不必要的toggle,即使未启用相应的计算。因此,以下技术可降低功耗。
时钟门控为数据路径操作提供输入的时序逻辑
在输入端使用锁存器或者使用使能门控输入
Listing 7. Gating Data Operator Input Toggling Method1
always @(posedge clk or negedge reset) if (reset = 0) begin mul_in1 <= 0 mul_in2 <= 0 end else if (mul_en) begin mul_in1 <= nxt_mul_in1; mul_in2 <= nxt_mul_in2; end
Listing 8. Gating Data Operator Input Method 2
assign mul_in1 = data_in1 &
{DATA_WIDTH{mul_en}};
assign mul_in2 = data_in2 &
{DATA_WIDTH{mul_en}};
D. 减少组合逻辑的toggle
组合逻辑的功耗可以通过避免不必要的输入toggle来控制。这里可以考虑一个多路复用器作为示例,它是组合逻辑的常见模块。
在下图给出的示例电路中,我们有一个由两个packetizers访问的共享数据存储器。在这里,我们确实有明显的功耗浪费,因为当packetizer1 访问数据时,packetizer2 的输入将切换toggle,反之亦然。
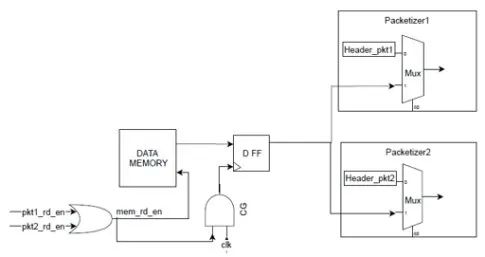
功耗更优化的设计将把输入门控到packetizer中的 MUX。
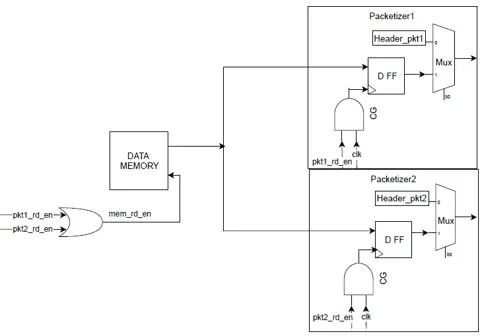
如果我们能把内存拆分成几个部分,我们就可以进行更细粒度的gate,从而产生更有效的门控效率。但缺点是routing congestion和面积成本。
三、RTL功耗分析工具
ASIC 设计流程正在使用 RTL 分析工具在早期阶段考虑分析功耗。
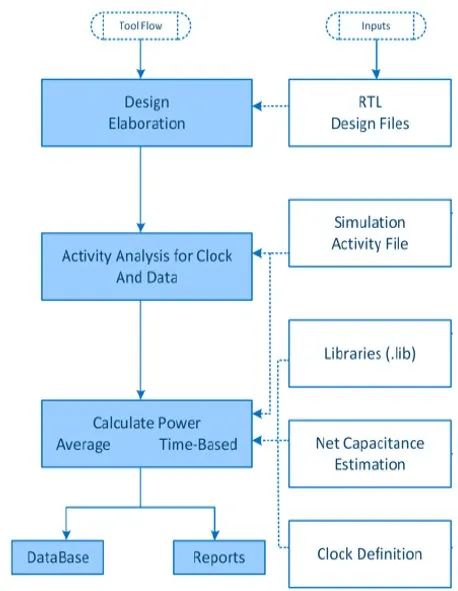
RTL设计文件使用VCD、SAIF或FSDB格式的仿真激励文件,针对时钟和数据toggle产生的功耗进行精心设计和分析。
审核编辑:黄飞
-
寄存器
+关注
关注
31文章
5342浏览量
120272 -
IC设计
+关注
关注
38文章
1296浏览量
103928 -
soc
+关注
关注
38文章
4164浏览量
218191 -
片上系统
+关注
关注
0文章
186浏览量
26809
原文标题:通过优化RTL减少功耗
文章出处:【微信号:数字芯片实验室,微信公众号:数字芯片实验室】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
射频识别芯片设计中时钟树功耗的优化与实现
优化 FPGA HLS 设计
为什么要优化FPGA功耗?
怎样通过软件控制的方式来优化并降低单片机的功耗?
RTL功耗优化
用Elaborated Design优化RTL的代码
如何降低面积和功耗?如何优化电路时序?






 工商网监
工商网监
评论