 如何在Arm平台上进行SPDK NVMe over TCP优化呢?
如何在Arm平台上进行SPDK NVMe over TCP优化呢?

什么是 SPDK?
随着存储介质在 I/O 性能方面不断演进,存储软件占用的总事务时间百分比变得越来越大。提高存储软件栈的性能和效率至关重要。存储性能开发套件 (SPDK) 是一个开源软件框架,它提供了一组库和工具,用于根据特定需求编写高性能、可扩展的用户模式存储应用。SPDK 全面释放现代存储硬件的潜力,例如非易失性存储器 (NVM) 设备、固态硬盘 (SSD) 和网络存储设备。
SPDK 的工作原理是什么?
传统的内核 I/O 栈由于上下文切换、数据复制、中断和资源同步等原因带来了开销。SPDK 大幅减少了 I/O 处理期间的开销,其方法如下:
使用存储应用的用户模式,而非内核模式。设备绑定 UIO 或 VFIO 驱动程序后,SPDK 运行用户空间中的设备,从而消除了成本高昂的上下文切换。应用利用 SPDK 库,直接通过用户空间驱动程序与设备通信。
以轮询模式而不是中断模式运行。在初始化期间,SPDK 会在每个核心上创建一个线程,称为 Reactor(图 1)。用户在此 Reactor 上注册轮询器来轮询硬件是否完成,而不是等待中断。这样就降低了中断处理开销和延迟。
使用无共享线程模型。每个 SPDK 线程都独立运行自己的一组数据结构和资源,从而避免了同步开销。每个 Reactor 上会创建一个事件环,以进行必要的线程通信。
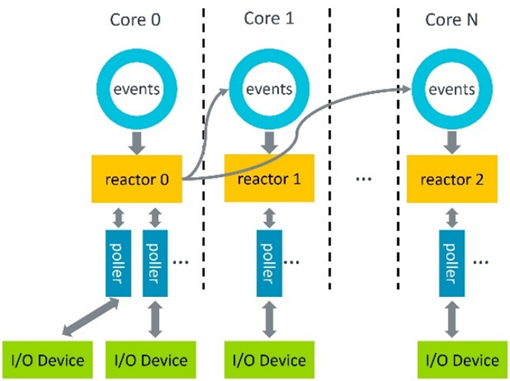
图 1:SPDK 线程模型
SPDK 框架
如图 2 所示,SPDK 包含多层。
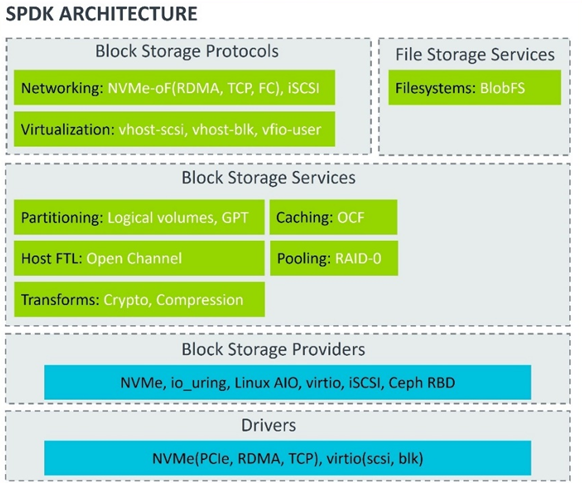
图 2:SPDK 架构
硬件驱动程序:快速非易失性存储器 (NVMe) 驱动程序是 SPDK 的基础组件。这是一个 C 库,用于与 NVMe 设备之间进行直接零拷贝数据传输。virtio 驱动程序允许与 virtio 设备进行通信。
块存储:SPDK 提供丰富的后端存储设备支持,包括以 NVMe SSD、Linux 异步 I/O (AIO) 作为支持的 NVMe 块设备,以便让 SPDK 能够与 HDD 和 ceph RBD 等内核设备交互,从而将 ceph 作为 SPDK 的后端设备。
块存储服务:SPDK 块存储服务层为附加客户功能提供灵活的 API,这些功能包括 RAID 和块层压缩。
块存储协议:块存储协议使得 SPDK 能够通过不同的传输协议将其后端存储提供给远程客户端、虚拟机或其他进程。iSCSI target 是在 TCP/IP 连接上实现了传输块级 SCSI 数据的既定规范。NVMe over Fabrics (NVMe-oF) target 是 NVMe-oF 规范在用户空间的一个实现,即在网络上呈现一个快设备。Vhost target 使得 SPDK 能够为基于 Qemu 的虚拟机或 Kata 容器提供后端存储。Vfio-user 允许 SPDK 将虚拟的 NVMe 设备提供给虚拟机,后者利用现有的 NVMe 驱动程序与设备进行通信。
文件存储服务:SPDK 在其块分配器 Blobstore 上还提供了一个名为 BlobFS 的文件系统。它可作为 MySQL 和 Rocksdb 的存储后端,从而使整个 I/O 路径都位于用户空间中。
什么是 NVMe over TCP?
NVMe 是一种专为 SSD 而设计的协议,旨在通过 PCIe 接口来显著提高性能。NVMe over PCIe 是 NVMe 协议的初期目标,用于本地 NVMe SSD 访问。它通过 PCIe 接口协议将命令和响应映射到主机的共享内存,以此来传输数据。
NVMe-oF 支持通过网络来远程共享和访问 NVMe 存储设备,例如以太网或光纤通道。NVMe-oF 是 NVMe over PCIe 的扩展。NVMe-oF 利用基于消息的模型或组合模型在主机与目标存储设备之间通信。所支持的传输协议包括光纤通道 (Fibre Channel)、RDMA (Infiniband、ROCE、iWARP) 和 TCP(图 3)。
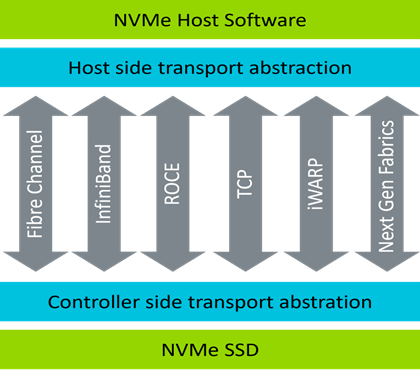
图 3:NVMe over Fabrics 模型
SPDK 支持 RDMA、TCP 和光纤通道传输。它由 initiator 程序框架和 target 组成(图 4)。如果 initiator 程序(主机)和 NVMe SSD 位于同一服务器内,则直接通过 PCIe 访问设备。否则,启动程序必须通过结构来访问远程目标设备。
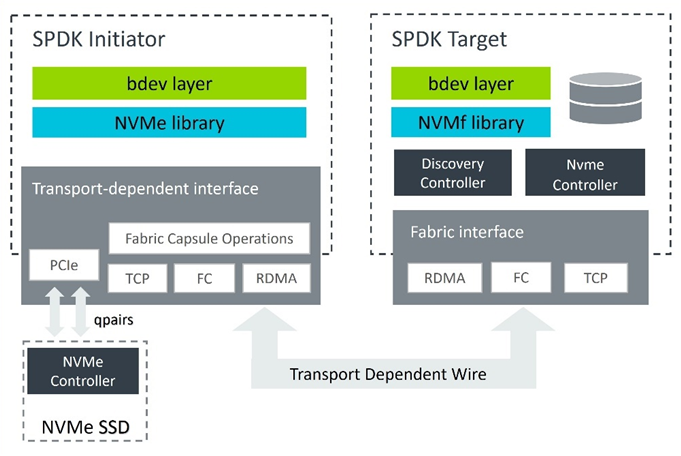
图 4:SPDK NVMe over Fabrics 框架
在多种结构选项中,NVMe over TCP 允许用户跨标准以太网使用 NVMe。得益于成熟 TCP/IP 栈的稳定性和可移植性,这可实现更低的部署成本,并降低设计复杂性。
我们将重点关注 SPDK NVMe over TCP,它集 NVMe over TCP 和 SPDK 工作机制的优点于一身。
使用 TCP 传输时(图 5),每个主机端 NVMe 队列对都有一个对应的控制器端队列对,后者被映射至自己的 TCP 连接。该 NVMe 队列对将会分配给单独的 CPU 核心。命令包 (Command Capsules) 被封装到 TCP 协议数据单元 (PDU) 中,并通过 Linux 系统调用(包括 sendmsg),经标准 TCP/IP 套接字发送出去。控制器端从套接字缓冲区读取接收到的数据并构建接收 CMD 包。这其中就包括用于进一步处理的请求信息。处理完请求后,会生成一个 RSP 包并通过套接字发送出去。响应数据到达主机端套接字缓冲区,该缓冲区已被封装到接收 CMD 包中。
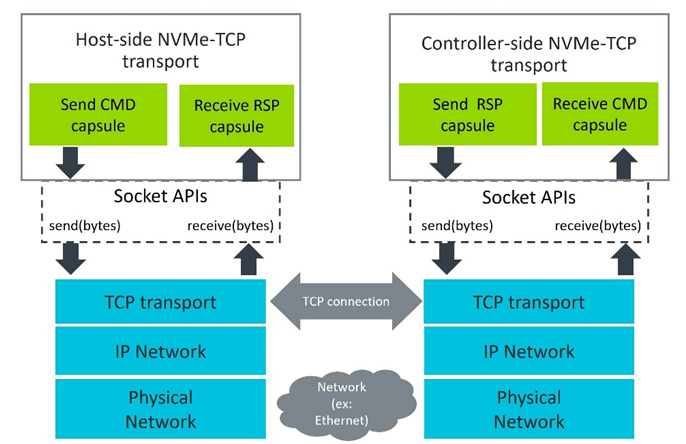
图 5:NVMe over TCP 数据路径
Arm 平台上的优化工作
SPDK NVMe over TCP 是一个高性能解决方案,它通过 TCP/IP 网络将 NVMe 存储提供给远程客户端。虽然 SPDK 是无锁的,并且 NVMe 驱动程序位于用户空间内,但基于内核的 TCP/IP 栈并不是无锁的。因此,内核与用户空间之间的系统调用和内存复制是不可避免的。为了有效利用 TCP/IP 栈,SPDK 引入了多项优化,包括:
批量写入
管道缓冲
零拷贝
我们的优化工作基于现有的实现,旨在进一步提高 SPDK NVMe over TCP 性能:
调整系统配置
改进数据局部性
平衡零拷贝和非零拷贝
减少功耗浪费
配置优化
正确的系统配置对于 SPDK 来说至关重要。平台会根据架构和功能进行配置,包括:
Linux 内核设置
PCIe 参数
NIC 参数
Linux 内核命令行设置
Hugepage:SPDK 依赖于数据平面开发套件 (DPDK) 库来管理组件,包括大内存页和缓冲池。DPDK 支持 2MB 和 1GB,以涵盖大内存区域,同时不会出现过多 TLB 未命中的情况,从而提供更好的性能。
核心隔离:将 CPU 与内核调度程序隔离开,以减少上下文切换。
Iommu.passthrough:如果 IOMMU 可用,SPDK 建议使用 vfio-pci 驱动程序。否则,请使用 uio_pci_generic 或 igb_uio。要使用 uio_pci_generic 或 igb_uio 驱动程序,应禁用 IOMMU 或将其设为直通模式。如果未设置 iommu.passthrough,vfio-pci 驱动程序将对 DMA 使用 I/O 虚拟地址 (IOVA)。这对于 IOMMU 的转换更为安全。如果在 GRUB 命令行中添加“iommu.passthrough=1”,则对 DMA 使用物理地址。这样可以提高性能。
例如,对于四个 1G 的大页,请将以下参数添加到 GRUB 命令行中。SPDK 运行在 CPU 核心 0-7 上,而 IOVA 为物理地址。
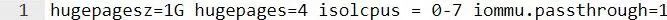
PCIe 参数调整
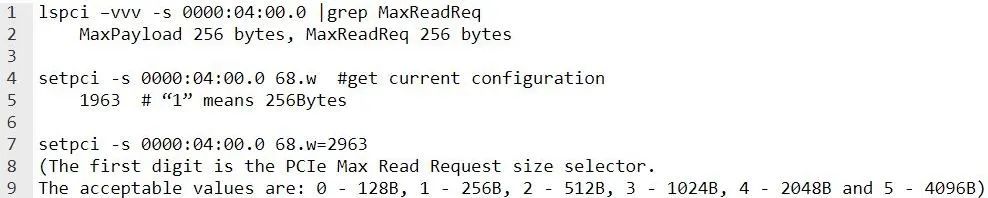
PCIe 最大有效负载大小 (PCIe Max Payload Size) 决定了 PCIe 数据包的最大大小。制造商会设置最大 TLP 有效负载大小,该值还取决于所连接的设备。将“pci=pcie_bus_perf”添加到内核命令行,以确保使用 PCIe 最大有效负载大小。
PCIe 最大读取请求 (PCIe Max Read Request) 决定了所允许的最大 PCIe 读取请求。PCIe 最大读取请求的大小可能会影响待处理请求的数量。请根据工作负载进行调整。
使用以下命令设置最大请求大小:
NIC 参数调整
NIC 队列数和队列深度
通常情况下,NIC Rx/Tx 队列数的设置与 CPU 数量相同。队列大小需要适当,因为较小的队列可能会导致数据包丢失。如果环的大小超过了缓存,则较大的队列可能会导致缓存利用率较差。请根据系统资源和工作负载进行调整。
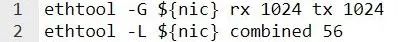
硬中断关联
IRQ 关联是一项 Linux 功能,它会将一些 IRQ 分配给专用处理器。正确的 IRQ 关联设置可提高服务器工作效率。对于大多数情况而言,NIC 的 IRQ 应绑定至 NIC 所在的同一 NUMA 节点。Irqbalance 是一个 Linux 守护进程,它有助于平衡所有 CPU 之间的中断所产生的 CPU 负载。要设置 IRQ 关联,应首先停止 irqbalance 服务。
例如,在 64 核系统的上层 32 核上,请将以下命令用于 IRQ 40:

硬中断合并
中断合并[1]是一种控制设备何时引发中断的方法。在产生中断之前,NIC 会收集入站数据包并等待达到特定阈值。这样便减少了 CPU 必须处理的总中断数,从而导致吞吐量提高、延迟增加以及 CPU 使用率降低。
请使用以下命令启用自适应 irq 合并:
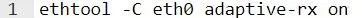
根据用例,使用 ethtool -C 设置 irq 合并:
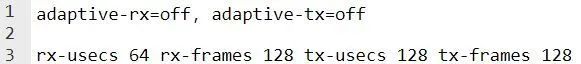
参数为:
rx-usecs:在数据包到达后会延迟 RX 中断的 usecs 数量
rx-frames:在 RX 中断之前所接收到的最大数据帧数
rx-frames-irq:在主机处理中断时,在生成 RX 中断之前所接收到的最大数据帧数
软中断合并
NAPI[2] 是一种减少网络设备在数据包到达时所生成的 IRQ 数量的机制。它会注册一个轮询函数,NAPI 子系统调用此函数可收集数据帧。
设置“net.core.netdev_budget”和“net.core.netdev_budget_usecs”可限制在一个 NAPI 轮询周期内轮询的数据包数量。Netdev_budget 是在一个轮询周期内从所有接口获取的最大数据包数。即使 netdev_budget 尚未耗尽,轮询周期也不得超过 netdev_budget_usecs 微秒。而 dev_weight 是内核在 NAPI 中断上可以处理的最大数据包数,它是一个 Per-CPU 变量。

请参阅 Linux 网络性能参数[3],获取更多信息。
TCP 套接字缓冲区
默认情况下,TCP 套接字缓冲区大小是根据系统内存自动计算的。较小的套接字缓冲区可能会导致接收数据时丢包,以及发送数据时频繁写操作阻塞。要调整缓冲区,请使用以下命令:

数据局部性优化
在 TCP 内核空间中,当数据到达 NIC 且 NIC DMA 数据包到达 RAM 时,会根据 RSS 中的哈希函数选择一个接收环。数据包的引用被排入环形缓冲区中。系统会发起硬 IRQ,由 CPU 负责处理。如果设置 IRQ 绑定,则是所分配的 CPU,否则 irqbalance 服务会选择一个。默认情况下,软 IRQ 会在与硬 IRQ 相同的 CPU 核心上触发;硬 IRQ 会触发 NAPI,以从接收环形缓冲区轮询数据。该数据包的处理是在 CPU 核心中进行的,直到被排入套接字接收缓冲区中。
在 SPDK NVMe over TCP 中,每个来自客户端的连接在启动期间都会分配给一个 Reactor(CPU 核心)。此连接的套接字读/写是在该 CPU 核心上完成的。所以,内核空间与用户空间之间存在语义差距,这与 CPU 核心亲和性有关。
为了保证 CPU 核心处理内核空间中的此套接字数据与用户空间中读取此套接字的核心 (SPDK) 完全相同,在 SPDK NVMe over TCP 中,我们引入了基于 CPU 亲和性的套接字处理[4] 。它将获取套接字的 CPU 亲和性,并确定在连接启动期间应将此套接字分配给哪个 CPU 核心。例如,当新连接(套接字 A)启动时(图 6),我们会获得套接字 A 的 CPU 亲和性。这里是 CPU 核心 1,它负责该套接字数据包的内核空间处理。然后在 SPDK 中,套接字 A 会被分配给核心 1 中的轮询组,以后套接字 A 的读/写将会在核心 1 上执行。
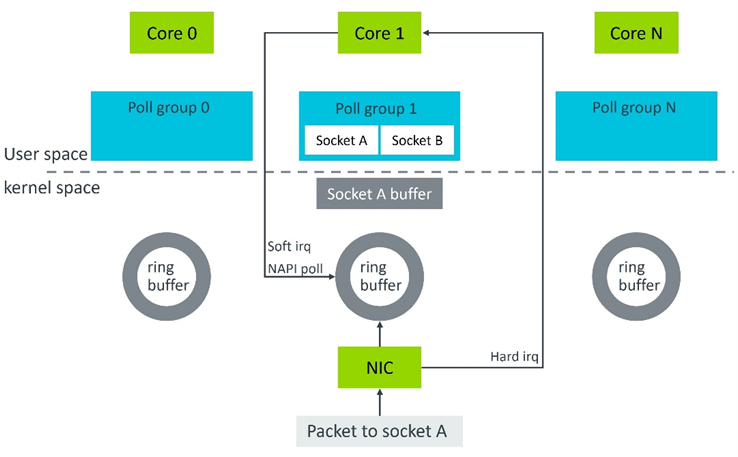
图 6:TCP 数据接收流程
例如:对于六个 P4600 NVMe 盘的服务器,它使用八个核心,NIC IRQ 被绑定至这八个核心,而客户端程序使用 24 个和 32 个核心。这个优化使随机写入性能提升 11% - 17%。
零拷贝优化
对于使用套接字发送数据时,MSG_ZEROCOPY[5] 标记可以使能零拷贝。该功能目前主要针对 TCP 套接字实现。然而,零拷贝并不是没有代价的,因为它会在页面固定期间导致额外的页面记录和完成后通知的开销。
在 SPDK NVMe over TCP 中,零拷贝可以在启动期间进行启用或禁用。启用后,不论大小,所有数据均通过零拷贝发送。这对于小数据(例如回复请求)的性能有负面影响。因此,平衡内存复制开销与页面固定开销至关重要。动态零拷贝[6]的引入是为了设置数据发送的阈值,以确定是否通过零拷贝发送数据。任何大于阈值的数据由零拷贝发送,其他数据则不然。
例如, 在 16 个 P4610 NVMe SSD、两个客户端,且客户端与服务器端程序的配置与 SPDK 报告[7]相同的测试环境中,对于 posix 套接字 rw_percent=0 (randwrite),经测试,128 队列深度、服务器端 1 至 40 个 CPU 核心下的性能提升可达 2.4% - 8.3%。当读取百分比大于 50% 时,其影响并不明显。对于 uring 套接字 rw_percent=0 (randwrite),经测试,128 队列深度、服务器端 1 至 40 个 CPU 核心下的性能提升可达 1.8% - 7.9%(图 7)。当读取百分比大于 50% 时,性能提升可达 1% - 7%。
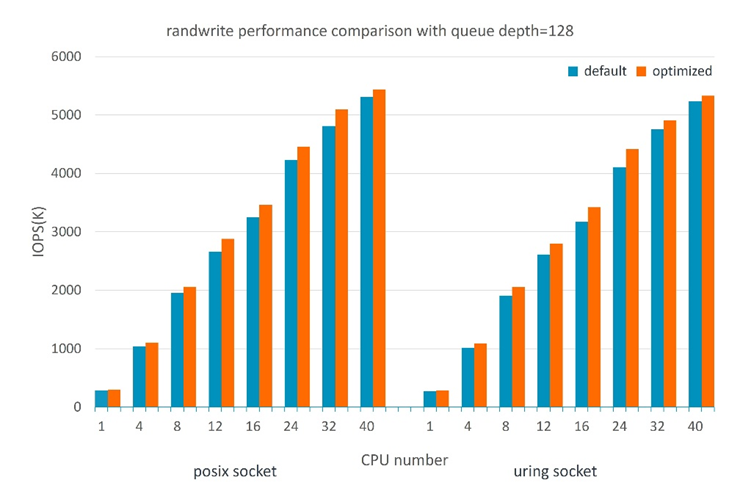
图 7:qdepth=128 时的 4KB 随机写入性能
功耗优化
以前在 SPDK 中,无论要处理的工作负载数量如何 ,CPU 核心上的每个线程都工作在轮询模式下。然而,如果工作负载随时间变化较大,可能会造成功耗浪费。为了解决这个问题,我们引入了动态调度程序框架,以实现节能并降低 CPU 占用率。
调度程序框架会动态收集每个线程和 Reactor 的数据,并执行包括移动线程、切换 Reactor 模式和设置 CPU 核心频率等在内的操作。例如,如果 Reactor 1 到 Reactor N 中的轮询器空闲,则相应的 SPDK 线程将迁移至 Reactor 0(图 8)。然后,Reactor 1 至 Reactor N 切换至中断模式。Reactor 0 的 CPU 频率会根据该 Reactor 的繁忙程度进行调整。我们将这称之为 CPU 频率调节。
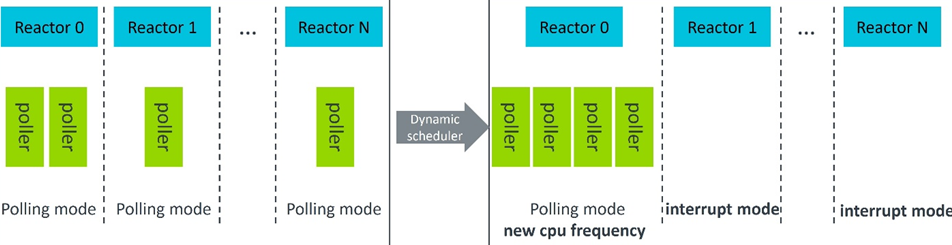
图 8:SPDK 动态调度程序解决方案
Linux 内核通过 CPU 频率调节 (CPUFreq) 子系统支持 CPU 性能调节。它由三个模块组成:
核心
调节调控器
调节驱动程序
调节驱动程序与硬件通信。cppc_cpufreq 驱动程序适用于大多数 AArch64 平台。该驱动程序使用 ACPIv5.1 规范中所述的协作处理器性能控制 (CPPC) 方法。CPPC 是以 CPU 性能值的抽象连续量表为基础的。这样就允许远程功耗处理器灵活地进行优化,以提高功率和性能。
为了启用 AArch64 上的 CPU 频率调节,cppc_cpufreq 驱动程序支持[11]被添加到 DPDK Power Library(DPDK 功率库)中。SPDK 利用它来调节 CPU 频率,也利用它来获取频率信息供调节使用。选项包括 highest_perf、nominal_perf 以及 scaling_max_freq、scaling_min_freq 等等。它为用户提供了 API,用于设置 CPU 频率和启用或禁用加速技术。请参阅 DPDK Power Library[12],获取有关 API 的更多信息。
结论
本文介绍了 SPDK、SPDK NVMe over TCP 以及如何对其进行优化,其中包括系统配置优化、数据局部性优化、内存零拷贝优化和功耗优化。它们可用于解决对性能至关重要的存储问题。
审核编辑:刘清
-
以太网
+关注
关注
41文章
6283浏览量
181865 -
SSD
+关注
关注
21文章
3165浏览量
122674 -
TCP
+关注
关注
8文章
1436浏览量
83866 -
固态硬盘
+关注
关注
12文章
1659浏览量
60752 -
非易失性存储器
+关注
关注
0文章
140浏览量
24145
原文标题:在 Arm 平台上进行 SPDK NVMe over TCP 优化
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录





评论