 星脉网络深度解析:GOR全链路流量规划与拥塞控制机制
星脉网络深度解析:GOR全链路流量规划与拥塞控制机制

转载自:
作者:Rock、付博睿
前言
DCN(Data Center Network)数据中心网络是现代信息技术基础设施的重要组成部分。它提供了连接与通信的基础,支撑数据中心内外部各种应用和服务。作为一个复杂的网络系统,DCN承载着大量数据流量和通信需求,为AI、大数据、云计算等关键技术提供基础底座。
在传统DCN中,CPU被用作核心来处理复杂的计算任务和少量数据。然而,随着AI人工智能的迅速发展,GPU的重要性日益凸显。作为一种高度并行的硬件加速器,GPU非常适合处理AI所需的大量数据。AI的快速发展不仅增加了对GPU计算能力的需求,还对网络的传输和稳定性提出了新的挑战,传统的DCN已经无法满足AI大模型训练的需求。在这个背景下,传统的以CPU为核心的DCN正在向全新的以GPU为核心的星脉AI高性能网络演进升级。腾讯星脉AI高性能网络专为AI大模型而设计,提供大带宽、高利用率以及零丢包的高性能网络服务,以保障AI大模型的训练效率。星脉AI高性能网络架构如图1所示,包括:高速自研交换机、端网协同的拥塞控制+负载均衡TiTa+GOR(Global Optimized Routing)、高性能集合通信库TCCL(Tencent Collective Communication Library)以及端到端运营系统GOM(Global Optimized Monitoring)。
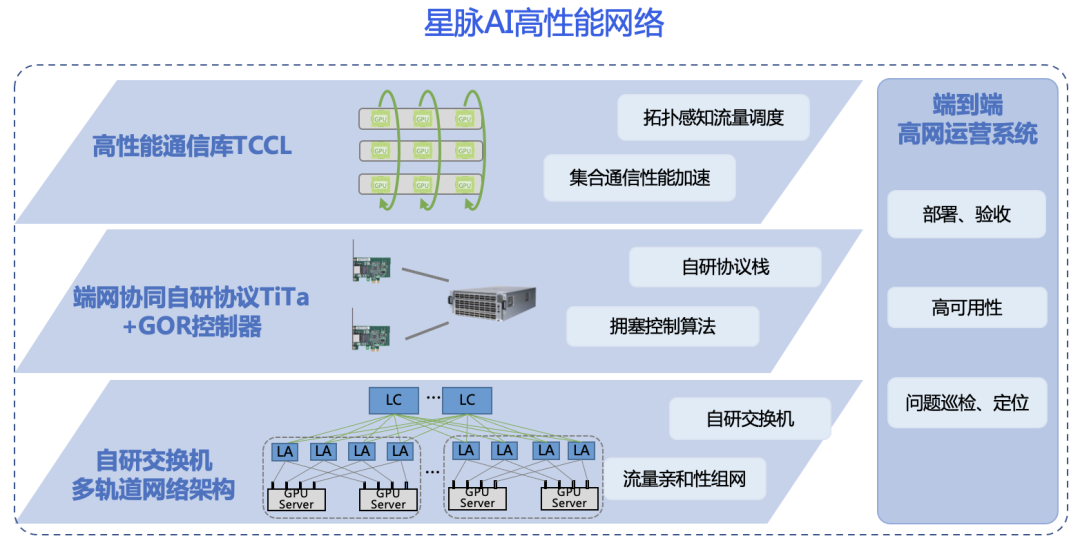
图1.星脉AI高性能网络 在传统DCN中,我们已经广泛应用网络控制器来实现网络变更灰度和路由监控,以确保网络的稳定性,此时的控制器叫做DCN控制器1.0。然而,在星脉AI高性能网络中,由于AI大模型训练需要处理大量的数据,同时各种并行模式和加速框架也引入了海量的通信需求,因此为了保证AI大模型训练的效率,超高速且无拥塞的网络成为至关重要的前提条件。在这个背景下,我们将网络控制器进一步演进升级到DCN控制器2.0—GOR控制器。GOR是星脉AI高性能网络的关键技术之一,通过GOR控制器的精细控制,实现网络流量合理规划和动态调整,从而达到超低时延与超高带宽,保障AI大模型训练效率。
DCN控制器1.0,网络稳定性的守护者
网络变更灰度:DCN中网络设备数量多、组网复杂、流量复杂,并且单台设备承载的流量大。日常运营中经常涉及设备的维修替换,这就需要处理设备从在线到隔离再到重上线的过程。设备处于隔离状态时没有入向流量,从隔离状态转换到重上线状态过程中重新对外引流。此时如果设备有问题(硬件、配置等),影响的用户范围非常广,稳定性风险很高。因此我们在实际运营中,使用DCN控制器将少部分流量引到隔离设备上。通过观察灰度流量是否正常来判断设备是否正常。如果灰度流量有问题则快速回滚,将故障影响面控制到最小,保证网络的稳定性。
路由监控:路由监控的目标是对DCN内外网路由进行采集、监控,对不符合预期的路由进行提前告警和控制,优化路由自动管理,提前发现网络故障隐患。DCN承载的业务复杂多样,内、外网路由策略各不相同,甚至部分业务还对路由存在特殊需求,因此如何确保各种场景下海量路由的正确性,是网络运营的一个重要挑战。 在路由监控中,DCN控制器与网络设备建立BGP邻居,收集设备上的路由,按照各种功能和业务需求进行监控:功能类监控面向通用场景,支持不同维度路由查询、回溯,监控特定路由(特定大段路由、汇总路由)等;业务类监控针对具体业务,路由的产生者是业务网关,不同业务路由策略各不相同,包括主备路由监控、anycast路由监控、路由震荡监控、公网路由掩码监控以及路由来源监控等。通过多维度的路由监控,确保网络的正确性、一致性。
星脉GOR控制器(DCN控制器2.0),网络流量工程的领航员
AI网络中的数据流就好像拉力赛道上飞驰的赛车,在赛道上高速前进。但是由于赛道的宽度有限,如果一条赛道上同时有多辆赛车,那么赛车就需要降低速度来避免碰撞;AI网络中的数据流也类似,如果一条网络链路上有多条数据流,那么不同流的总和容易超过链路的最大带宽,从而出现拥塞导致流降速,最终影响AI大模型的训练效率。为了避免上述冲突,拉力赛中需要领航员规划赛车路线,避免多辆赛车同时通过赛道。此外在出现突发状况时,领航员快速调整路线避免赛车间冲突碰撞,如图2所示。在AI网络中,我们也需要类似负责规划与调度的领航员,这就是星脉网络GOR控制器。一方面GOR控制器预先规划网络中数据流路径,避免拥塞;另一方面在拥塞发生时(例如网络链路故障),GOR控制器动态调度快速消除拥塞,从而保证AI大模型的训练效率。
●AI大模型网络特征 组网复杂。AI大模型网络通常组网复杂、流量复杂。图3分别是4K卡和16K卡集群的组网抽象图。在如此复杂的网络拓扑下,多任务并行以及相应的网络流量规划和网络流量拥塞调度都面临着极大的挑战。
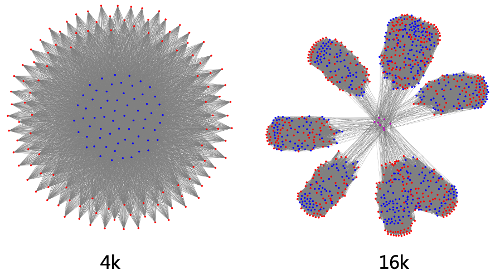
图3.4K、16K卡集群组网抽象图 局部负载不均。负载均衡是网络领域的经典问题。如何均衡网络流量、提高利用率、避免拥塞,从而保证业务质量是网络持续追求的目标。虽然我们的网络带宽越来越大(设备交换芯片容量从6.4T、12.8T、25.6T到51.2T),但伴随着业务的井喷式发展,服务器端侧的带宽也在快速增加(从10G、25G、100G到200G)。因此,大象流或者局部负载不均导致的网络拥塞在DCN仍然很常见,尤其在AI网络中问题更加突出。这是因为AI大模型业务特征是业务流数少,单流带宽大。这种流量模型对网络基于流Hash的负载均衡机制“并不友好”,容易造成局部热点,从而产生拥塞。 我们在现网运营中观察到很多AI网络集群并不能达到理想的负载均衡,图4是某个AI集群的网络流量分布热力图,颜色越深代表链路上流量越大,可以看到明显的负载不均。
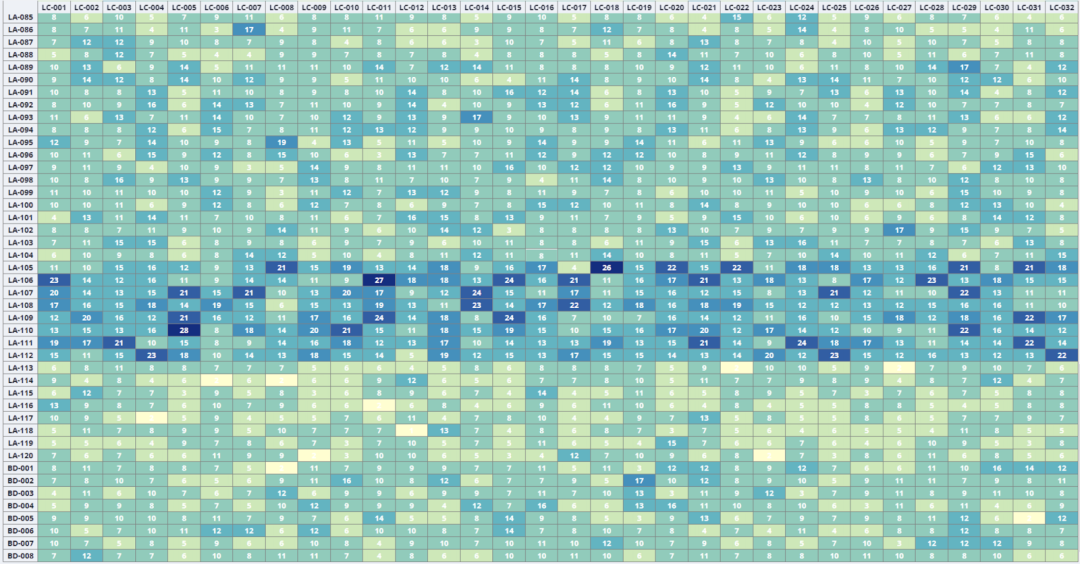
图4. 网络链路流量分布 AI网络性能决定GPU集群算力,负载不均引起的网络拥塞会导致有效带宽降低、端侧通信时长增加,从而影响AI大模型的训练效率。我们可以采用多种指标衡量网络拥塞,例如:拥塞计数、延时、带宽占用率、缓存队列等。从图5可以看出,ECN计数突增的同时,伴随端侧计算通信时长显著增加,严重降低AI大模型训练效率、影响训练成本。
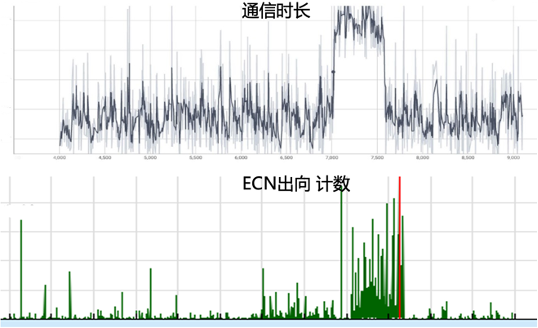
图5.ECN计数与端侧通信时长 流量可预测。AI大模型网络流量具有高度可预测特性。从宏观角度看,一旦AI大模型训练任务启动,我们可以提前确定哪些节点之间需要进行通信,以及在何时、如何进行通信;从微观角度看,节点之间的通信数据流呈现出高度周期性的特点。图6分别是RDMA QP(Queue Pair)维度和五元组数据流维度的趋势图,可以看到无论从单个QP还是多个QP聚合的五元组数据流维度统计,流量都呈现明显的周期性。
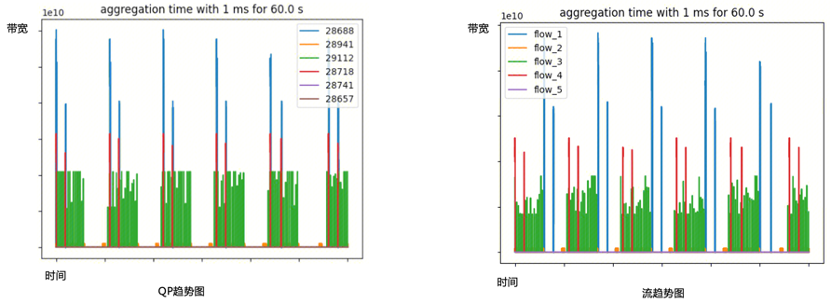
图6.QP、流趋势图 ●GOR控制器设计 GOR控制器包括两部分:训练任务启动前的预规划以及训练任务进行中的动态调度。预规划阶段,控制器通过结合全局网络拓扑与任务信息,为每条业务流规划最佳路径;动态调度阶段,将热点区域的数据流进行调度换路,绕开拥塞,从而保障AI大模型的训练效率。预规划的目标是尽量减少、避免网络拥塞;动态调度的目标是当拥塞发生时(例如网络链路故障),通过对相关流进行动态换路来消除拥塞。线上数据表明,通过GOR控制器的调度,网络拥塞时间缩短超过90%。 GOR控制器包括三个部分:采集、计算和调度/监控,总体控制流程如图7所示。采集阶段,GOR控制器通过分析秒级Telemetry数据找到出现拥塞的交换机端口以及业务流详情,按照一定的策略选出需要调度走的业务流。
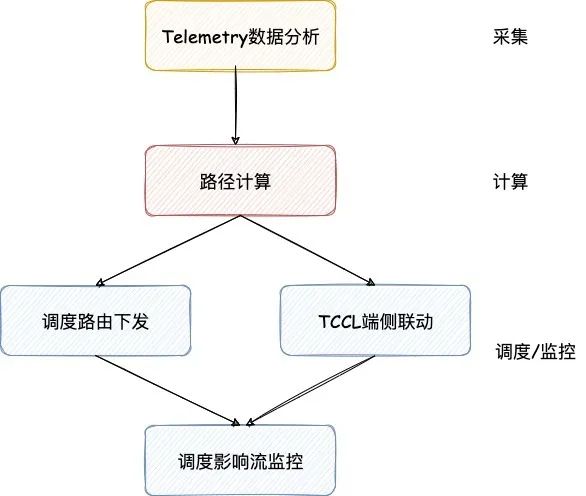
图7. GOR控制器流程 路径计算的核心诉求是结合网络实时拓扑,为上一阶段选出的每个要调度的流找到最优新路径。同时要对新路径进行容量评估,避免调度到新路径后产生新的拥塞。 调度的方法是修改流路径,具体有两种方式:下发调度路由和TCCL端侧联动。下发调度路由方式中,控制器通过向网络设备下发路由从而修改对应流路径;TCCL端侧联动方式中,控制器与TCCL联动修改流路径,最终绕开出现拥塞的交换机端口。 调度下发后,控制器对影响的训练任务流进行监控。当训练任务结束后需要撤销相应的调度路由,避免AI训练任务变化后,之前下发的调度路由对新任务产生非预期的影响。 ●GOR控制器规划、调度效果 GOR预规划的目标是避免拥塞,保证端侧通信速率,从而保障AI大模型训练效率。预规划阶段,控制器为每条数据流进行高速算路,单条路径计算时间在微秒级,万条路径计算时间小于1秒。图8所示是千卡任务预规划后的网络链路流量分布,颜色越深代表链路上流量越大,颜色相近代表链路负载均衡,与图4对比可以看到GOR预规划对网络负载均衡效果显著。预规划可以实现95%以上的业务均衡,在业务亲和情况下可以实现近100%无拥塞。
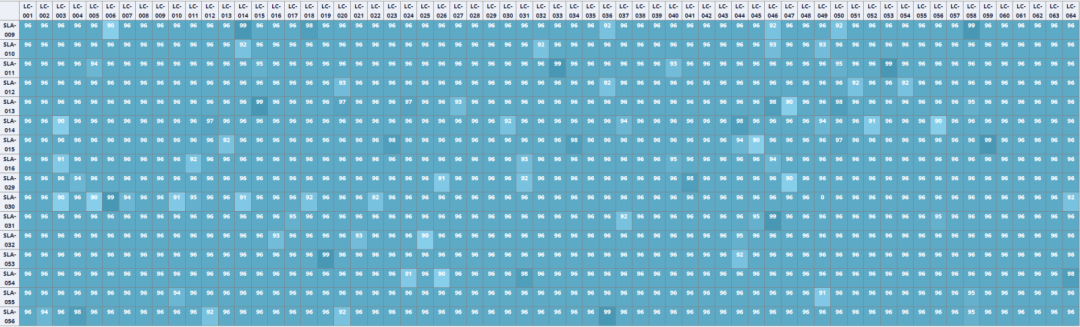
图8.预规划后网络流量分布 预规划提高网络负载均衡度,从而保证端侧通信速率。图9是AllReduce通信模型下,GPU集群针对不同Message size预规划前后的通信速率性能测试结果。可以看到GOR预规划对端侧通信速率提升明显,AllReduce性能提升近20%。
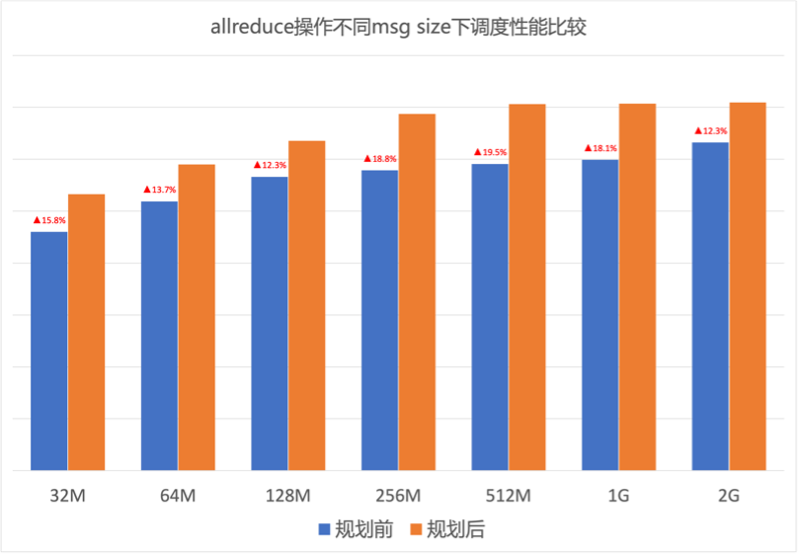
图9.AllReduce性能对比 GOR动态调度的目标是当拥塞出现时快速消除拥塞。我们对线上某个AI网络集群的ECN告警数与告警时长持续监控一个月,如图10所示。开启GOR控制器调度后,拥塞告警数与告警时长均显著下降,告警恢复时间小于3分钟,GOR调度对网络总体的拥塞消除效果显著。
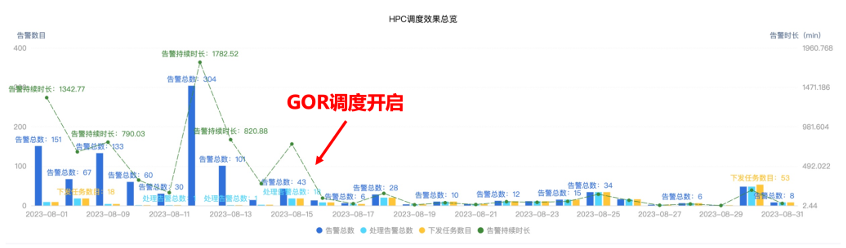
图10. 某AI网络集群ECN告警统计 为了更加直观展示GOR控制器调度效果,我们选取一些典型业务场景进行分析说明。图11是一个线上发生一般拥塞后,GOR控制器调度消除拥塞的效果。这种流量模型一般常见于AllReduce通信场景。从图中可以看到,GOR控制器执行调度后,交换机端口的ECN数归零,代表拥塞立即消除。
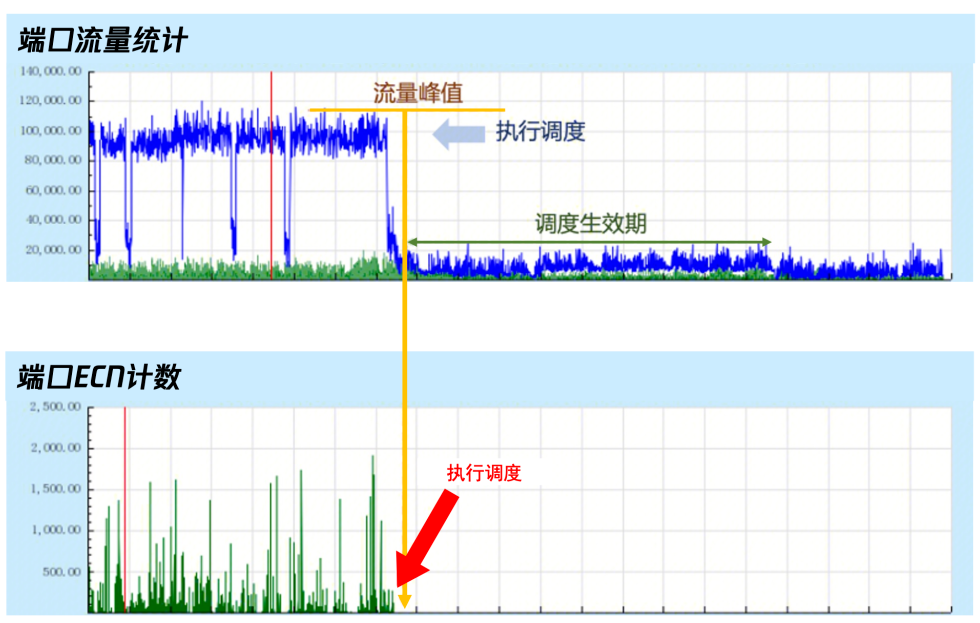
图11. 一般拥塞链路上的GOR调度 图12是线上一个网络链路严重拥塞时GOR的调度效果。这种流量模型通常出现在多个训练任务叠加场景,以及All2All通信场景。从图中可以看到,初始ECN数值超过了10000,表明链路已经严重拥塞。在首次调度后,GOR控制器成功将拥塞链路中的最大流调度至目的链路-1,这使得拥塞链路的带宽利用率显著降低,同时ECN计数也得到一定程度缓解,降至2000左右。在GOR控制器完成告警恢复校验后,继续调度,将链路中的次大流调度至目标链路-2,从而使ECN数值进一步降至约1000左右。经过两次调度,拥塞链路的ECN数值仍然很高,GOR继续第三次调度,最终成功将ECN数值降低至500以下,从而消除了该链路的拥塞。
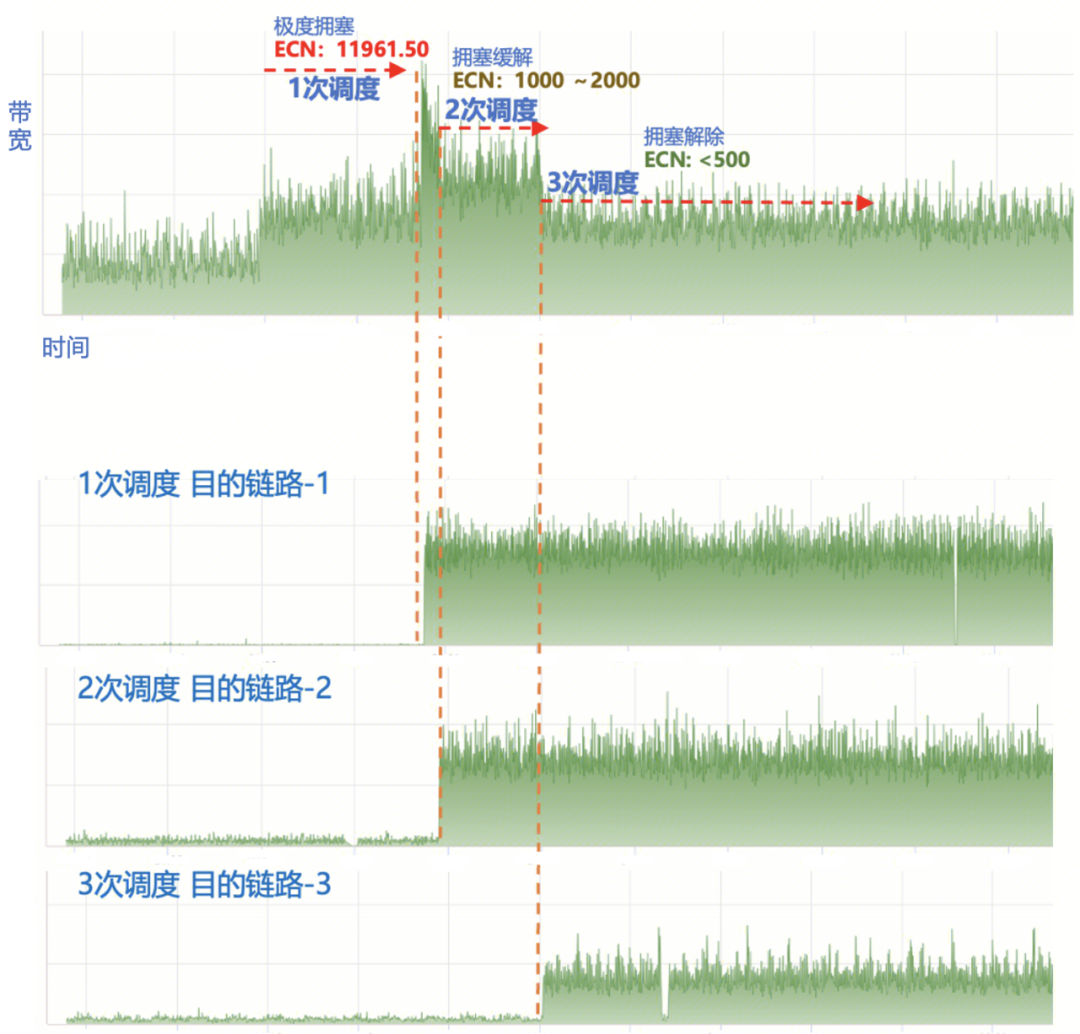
图12.严重拥塞链路上的GOR调度 图13是一台机器网卡的RDMA速率监控,可以看到GOR控制器调度后,网卡的出方向速率持续升高,最终达到预期值。
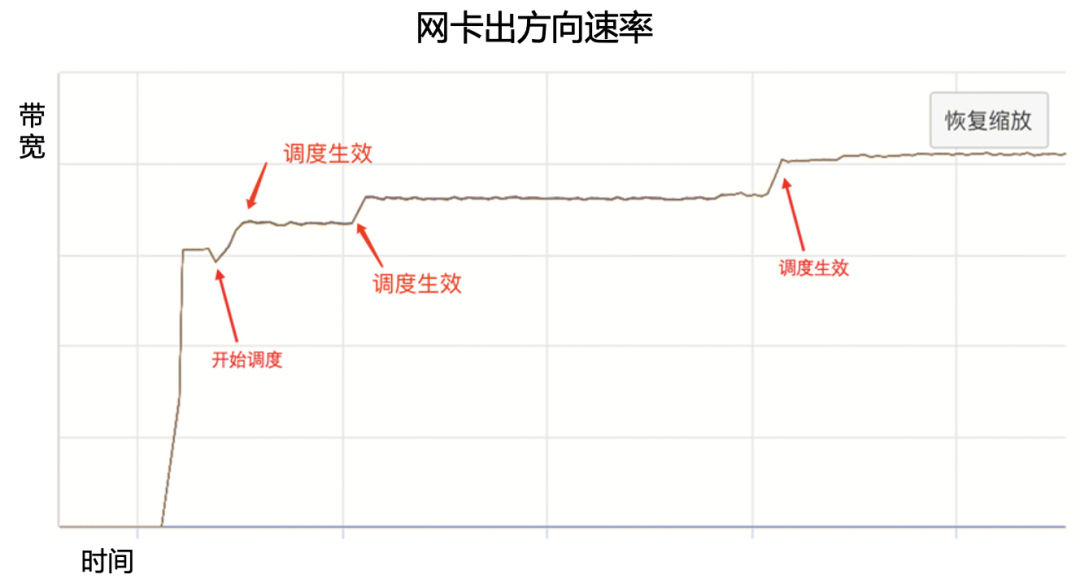
图13.GOR调度对网卡出向速率的影响 AI大模型的算力基础是GPU,不同厂商异构GPU的通信模式、流量模型差异很大。GOR控制器在不同GPU集群中都可以显著消除网络拥塞,加速端侧通信速率,从而保证AI大模型训练效率。图14、图15分别所示在A、B两种GPU集群中针对不同Message size调度前后的All2All测试结果,可以看到GOR调度后效果显著,All2All性能提升30%~50%。
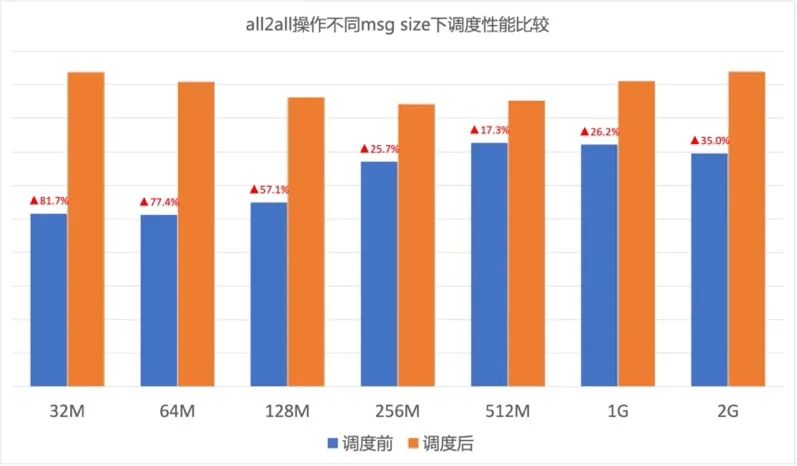
图14. A厂商GPU集群调度开启前后All2All性能对比
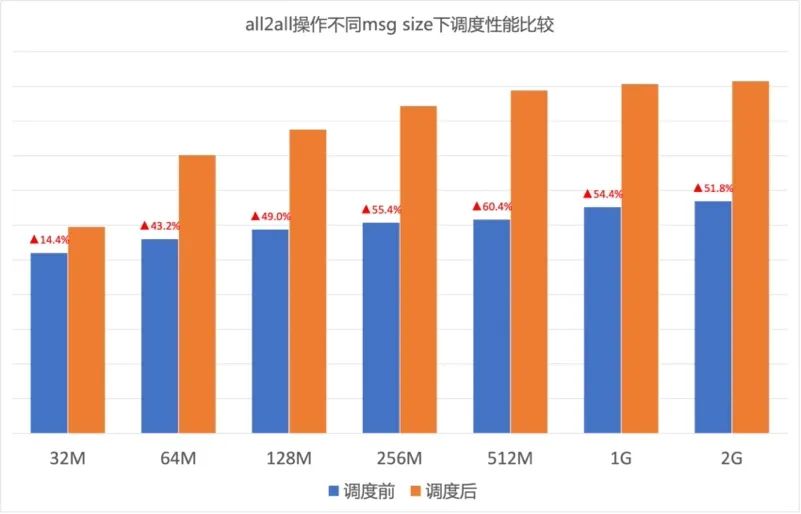
图15. B厂商GPU集群调度开启前后All2All性能对比 实际场景中,GOR控制器预规划与动态调度结合使用。图16所示在GPU集群All2All性能测试场景中,预规划提升All2All性能45%以上,显著解决负载不均问题。当网络链路故障时,性能下降约20%。检测到拥塞后,GOR控制器动态调度将性能恢复到理想水平。
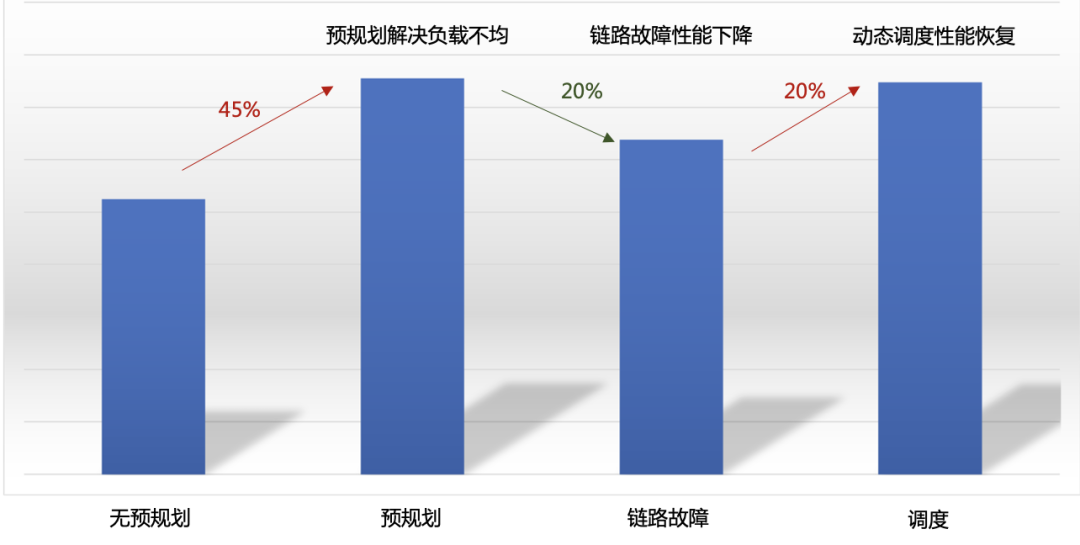
图16. 各场景下All2All性能 ●GOR控制器业务级运营效果 除了规划和调度功能外,GOR控制器还实时监控网络中流的五元组信息,并结合业务侧的AI大模型训练任务,以提供星脉网络的业务级运营能力。业务级运营将底层网络流的五元组信息与上层的AI大模型训练任务结合起来,以便在训练任务出现问题时快速定位相应的网络流,同时结合规划和调度信息判断是否与网络有关。同样地,当检测到网络拥塞时,能够快速找到相关的训练任务信息,并判断其对业务的影响。 图17是GOR控制器对网络流五元组信息的实时监控效果,网络中任一时刻、任一条链路上的所有流的五元组信息均可以完整记录,并且可以根据某个五元组还原对应流在网络中的完整路径。
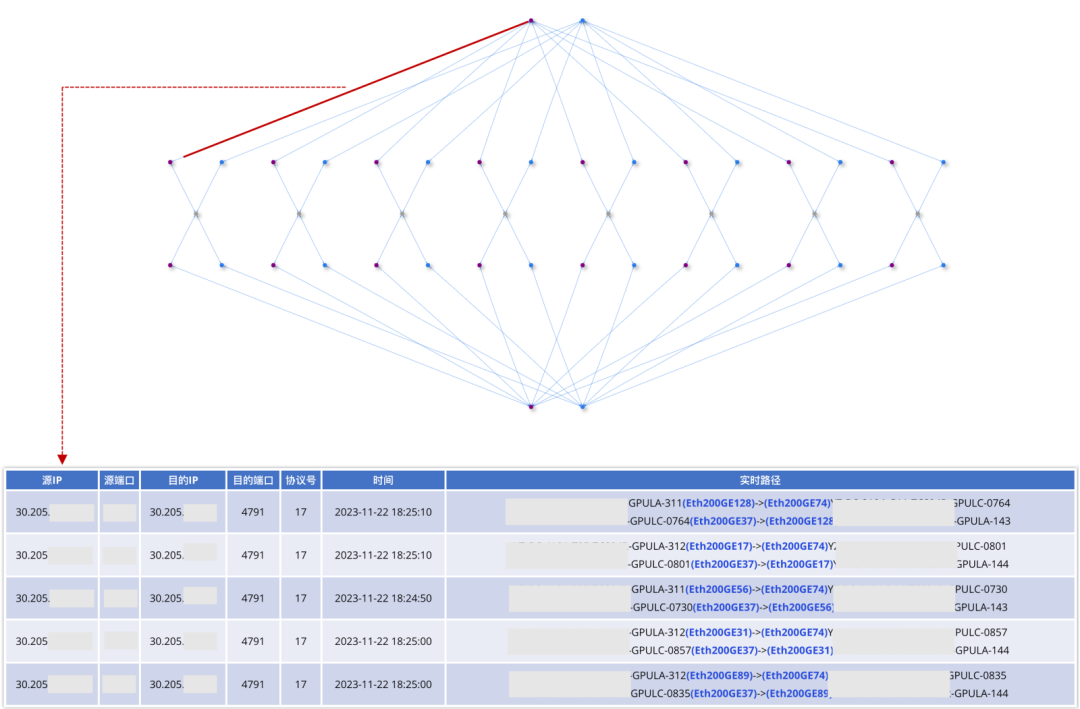
图17.网络流五元组信息实时监控 图18是训练任务与端侧节点的对应关系,GOR控制器通过聚合网络流的五元组信息并结合端侧和训练框架信息,还原出训练任务以及与训练任务相关的所有端侧节点信息。
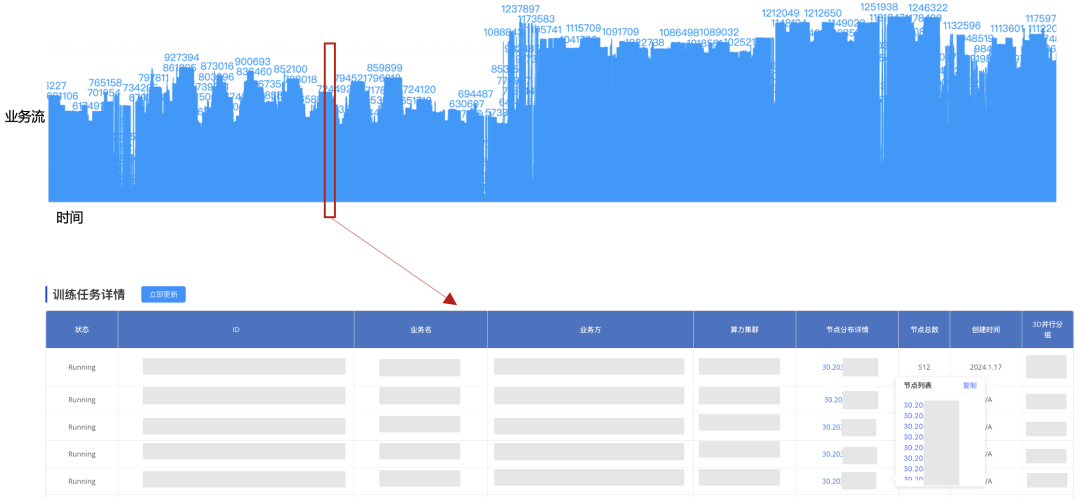
图18.训练任务与端侧节点对应关系
总结
作为现代信息技术的基础设施,DCN承载了AI、大数据、云计算等应用的海量数据流量和通信需求。尤其随着ChatGPT、Sora的出现,AI大模型引爆了新一轮算力网络需求浪潮,传统的以CPU为核心的DCN演进升级到了全新的以GPU为核心的星脉AI高性能网络。在传统DCN中,我们应用DCN控制器1.0实施网络变更灰度和路由监控来保证网络的稳定性;在星脉AI高性能网络中,DCN控制器1.0进一步演进升级到星脉GOR控制器。星脉GOR控制器通过精细控制实现网络流量合理规划和动态调整,并提供业务级运营能力,全面提升AI大模型的训练效率。
审核编辑:黄飞
-
控制器
+关注
关注
114文章
17877浏览量
195101 -
cpu
+关注
关注
68文章
11327浏览量
225878 -
数据中心
+关注
关注
18文章
5767浏览量
75202 -
AI
+关注
关注
91文章
41101浏览量
302577 -
dcnn
+关注
关注
0文章
7浏览量
3137
原文标题:星脉网络解密之——GOR全链路流量规划与拥塞控制
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
TCP优化之TCP/IP网络流量加速
因特网络拥塞控制机制的数学架构研究




评论