 基于Python和深度学习的CNN原理详解
基于Python和深度学习的CNN原理详解
介绍
卷积神经网络 (CNN) 彻底改变了计算机视觉领域,成为图像和视频分析应用的基石。在本文中,我们将深入研究使 CNN 强大的关键组件和操作,探索卷积、最大池化、步长、填充、上采样、下采样等概念。此外,我们将使用 Python 和流行的深度学习框架讨论数据集上的简单 CNN 模型。
卷积神经网络 (CNN) 由各种类型的层组成,这些层协同工作以从输入数据中学习分层表示。每个层在整体架构中都发挥着独特的作用。让我们探索典型 CNN 中的主要层类型:
1. 输入层 输入层是网络的初始数据输入点。在基于图像的任务中,输入层表示图像的像素值。在下面的示例中,我们假设我们正在处理大小为 28x28 像素的灰度图像。
从tensorflow.keras.layersimport Input input_layer=Input(shape=(28, 28, 1))2.卷积层 卷积层是 CNN 的核心构建块。这些层使用可学习的滤波器对输入数据应用卷积运算。这些滤波器扫描输入,提取边缘、纹理和图案等特征在卷积神经网络 (CNN) 中,“核”和“滤波器”这两个术语经常互换使用,指的是同一个概念。让我们来分析一下这些术语的含义:
from tensorflow.keras.layers import Conv2D conv_layer=Conv2D(filters=32, kernel_size=(3, 3), activation='relu')(input_layer)2.1核 核是卷积运算中使用的小矩阵。它是一组可学习的权重,应用于输入数据以生成输出特征图。核是让 CNN 自动学习输入数据中特征的空间层次结构的关键元素。在图像处理中,核可能是 3x3 或 5x5 这样的小矩阵。
2.2滤波器 另一方面,滤波器是一组多个内核。在大多数情况下,卷积层使用多个滤波器来捕获输入数据中的不同特征。每个滤波器与输入进行卷积以产生特征图,并且网络通过在训练期间调整这些滤波器的权重(参数)来学习提取各种模式。
在这个例子中,我们定义了一个有 32 个滤波器的卷积层,每个滤波器的内核大小为 3x3。在训练期间,神经网络会调整这 32 个滤波器的权重(参数),以从输入数据中学习不同的特征。让我们通过一个图像示例来看一下:
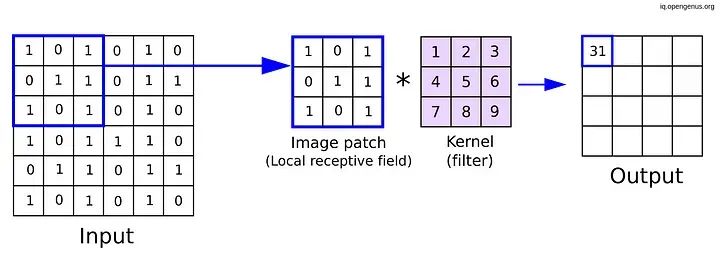
核形状(3X3)
总之,核是在输入数据上滑动或卷积的小矩阵,而滤波器是一组用于从输入中提取各种特征的核,从而允许神经网络学习分层表示。
3.激活层 (ReLU) 在卷积操作之后,逐元素应用激活函数(通常是整流线性单元 (ReLU)),以将非线性引入模型。ReLU 可帮助网络学习复杂的关系并使模型更具表现力。使用哪种激活完全取决于您的用例,在大多数情况下,研究人员使用 ReLU,但也可以使用一些激活,例如:Leaky ReLU、ELU。
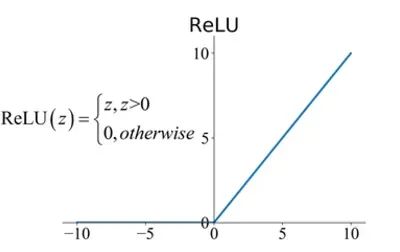
ReLU 激活 在 Python 中实现整流线性单元 (ReLU) 函数非常简单。ReLU 是神经网络中常用的引入非线性的激活函数。这是一个简单的 Python 实现:
def relu(x):
return max(0,x)
4.池化层 池化层(例如MaxPooling或AveragePooling)可减少卷积层生成的特征图的空间维度。例如,MaxPooling 从一组值中选择最大值,重点关注最显著的特征。
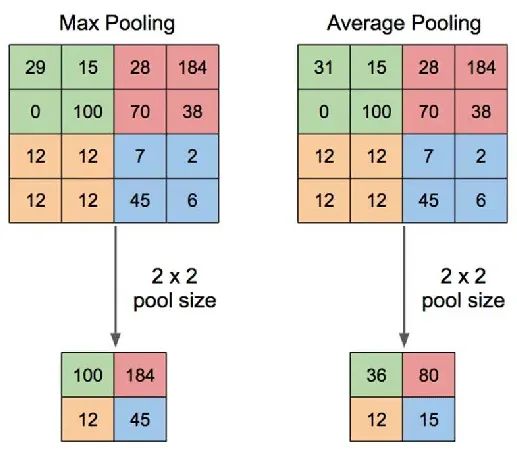
最大池化——平均池化 池化层减少了空间维度。MaxPooling 通常用于:
从tensorflow.keras.layers import MaxPooling2D pooling_layer = MaxPooling2D(pool_size=( 2 , 2 ))(conv_layer)5.全连接(密集)层 全连接层将一层中的每个神经元连接到下一层中的每个神经元。这些层通常位于网络的末端,将学习到的特征转换为预测或类概率。全连接层通常用于网络的末端。对于分类任务:
从tensorflow.keras.layers import Dense、Flatten
flatten_layer = Flatten()(pooling_layer) density_layer = Dense(units= 128 ,activation= 'relu' )(flatten_layer)6.Dropout 层 Dropout 层用于正则化以防止过拟合。在训练期间,随机神经元被“丢弃”,这意味着它们被忽略,从而迫使网络学习更稳健和更通用的特征。它通过在训练期间随机忽略一小部分输入单元来帮助防止过拟合:
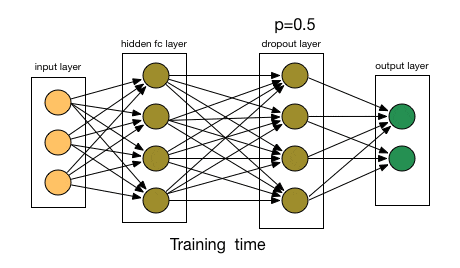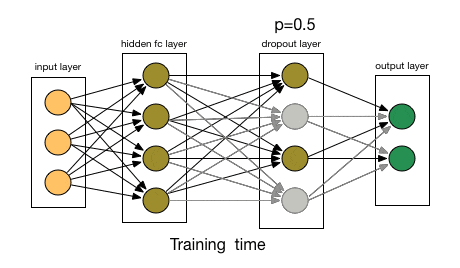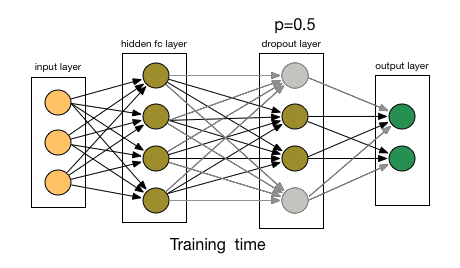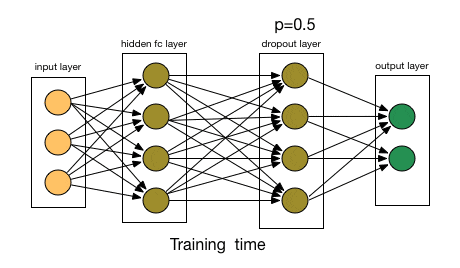
Dropout 机制
从tensorflow.keras.layers import Dropout
dropout_layer = Dropout(rate= 0.5)(dense_layer)7.批量标准化层 批量标准化 (BN) 是神经网络中用于稳定和加速训练过程的一种技术。它通过在训练期间调整和缩放层输入来标准化层输入。批量标准化背后的数学细节涉及标准化、缩放和移位操作。让我们深入研究批量标准化的数学原理。假设我们有一个大小为m且包含n 个特征的小批量。批量标准化的输入可以总结如下:
7.1均值计算 计算每个特征的小批量的均值μ :
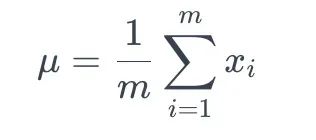
数组 X 的平均值
这里,xi 表示小批量中第 i个特征的值。
7.2方差计算 计算每个特征的小批量方差σ² :
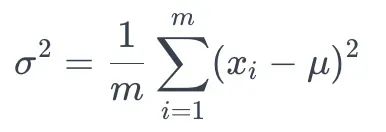
方差计算
7.3标准化 通过减去平均值并除以标准差(σ)来标准化输入:
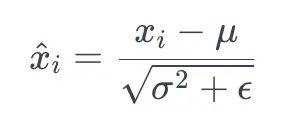
在范围内标准化
这里,ϵ是为了避免被零除而添加的一个小常数。
7.4缩放和平移 引入可学习参数(γ和β)来缩放和平移标准化值:
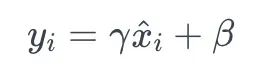
这里,γ是尺度参数,β是平移参数。
批量标准化操作通常插入神经网络层中的激活函数之前。它已被证明具有正则化效果,可以缓解内部协变量偏移等问题,使训练更稳定、更快速。这是一个简单的代码,用于 CNN 或任何深度神经网络中的批量标准化。
从tensorflow.keras.layers import BatchNormalization
batch_norm_layer = BatchNormalization()(dropout_layer)总之,批量标准化对输入进行标准化,缩放和移动标准化值,并引入可学习的参数,使网络在训练期间能够适应。批量标准化的使用已成为深度学习架构中的标准做法。 8.Flatten Layer Flatten Layer 将多维特征图转换为一维向量,为输入到全连接层准备数据。
flatten_layer=Flatten()(batch_norm_layer)9.上采样层 上采样是深度学习中用来增加特征图空间分辨率的技术。它通常用于图像分割和生成等任务。以下是常见上采样方法类型的简要说明:
9.1最近邻 (NN) 上采样 最近邻 (NN) 上采样,也称为通过复制或复制进行上采样,是一种简单而直观的方法。在这种方法中,输入中的每个像素都被复制或复制以生成更大的输出。虽然简单明了,但 NN 上采样可能会导致块状伪影和精细细节的丢失,因为它不会在相邻像素之间进行插值。
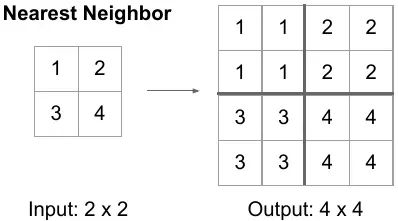
最近邻上采样
9.2转置卷积(反卷积)上采样 转置卷积,通常称为反卷积,是一种可学习的上采样方法。它涉及使用具有可学习参数的卷积运算来增加输入的空间维度。转置卷积层中的权重在优化过程中进行训练,使网络能够学习特定于任务的上采样模式。
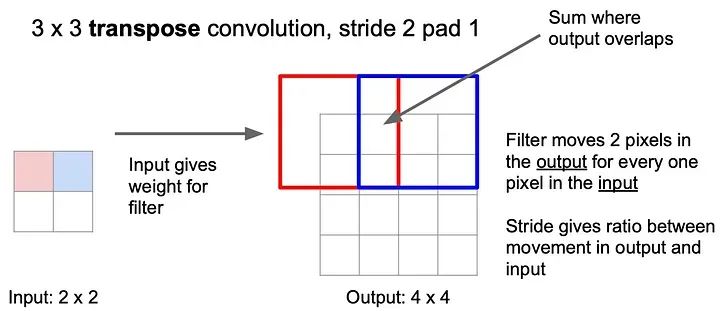
importtensorflowas tf from tensorflow.keras.layers import Conv2DTranspose #转置卷积上采样 transposed_conv_upsampling=Conv2DTranspose(filters=32, kernel_size=(3, 3), strides=(2, 2), padding='same')
每种上采样方法都有其优点和权衡,选择取决于任务的具体要求和数据的特点。
填充和步幅
这些是卷积神经网络 (CNN) 中的关键概念,它们会影响卷积运算后输出特征图的大小。让我们讨论三种类型的填充,并解释一下步幅的概念。
有效填充(无填充):在有效填充(也称为无填充)中,在应用卷积运算之前不会向输入添加任何额外填充。因此,卷积运算仅在滤波器和输入完全重叠的地方执行。这通常会导致输出特征图的空间维度减少。
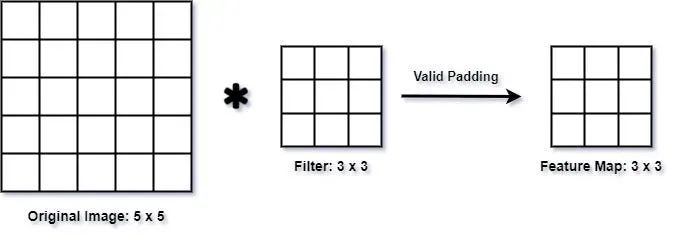
from tensorflow.keras.layersimportConv2D # 有效填充 valid_padding_conv=Conv2D(filters=32,kernel_size=(3,3), strides=(1,1),padding='valid')
相同填充:相同填充确保输出特征图具有与输入相同的空间维度。它通过向输入添加零填充来实现这一点,这样滤波器就可以在输入上滑动而不会超出其边界。填充量经过计算以保持维度相同。
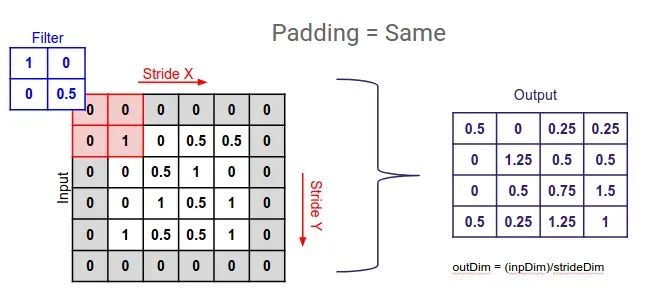
from tensorflow.keras.layers import Conv2D #Keras中的填充 same_padding_conv=Conv2D(filters=32,kernel_size=(3,3), strides=(1,1),padding='same')
步幅:步幅定义卷积过程中滤波器在输入上移动的步长。步幅越大,输出特征图的空间维度就越小。可以调整步幅来控制网络中的下采样级别。
从tensorflow.keras.layers导入Conv2D
# Keras 中带步幅的卷积示例
conv_with_stride = Conv2D(filters= 32 , kernel_size=( 3 , 3 ),
strides=( 2 , 2 ), padding= 'same' )
在此示例中,步幅设置为 (2, 2),表示滤波器在水平和垂直方向上每次移动两个像素。步幅是控制特征图的空间分辨率和影响网络感受野的关键参数。
在本文中,我想探索如何从头开始构建一个简单的卷积神经网络。让我们做早期计算机视觉学习任务中最流行的分类任务:猫与狗分类。此任务包括以下几个步骤:
导入库:
import tensorflow_datasets as tfds import tensorflow as tf from tensorflow.keras import layers import keras from keras.models import Sequential,Model from keras.layers import Dense,Conv2D,Flatten,MaxPooling2D,GlobalAveragePooling2D from keras.utils import plot_model import numpy as np import matplotlib.pyplot as plt import scipy as sp import cv2
加载数据:Cats vs Dogs 数据集
!curl -O https://download.microsoft.com/download/ 3 /E/ 1 /3E1C3F21-ECDB- 4869 - 8368 -6DEBA77B919F/kagglecatsanddogs_5340.zip !unzip -qkagglecatsanddogs_5340.zip ! ls
下面的单元将对图像进行预处理并创建批次,然后将其输入到我们的模型中。
def augment_images ( image, label ): # 转换为浮点数 image = tf.cast(image, tf.float32) # 标准化像素值 image = (image/ 255 ) # 调整大小为 300 x 300 image = tf.image.resize(image,( 300 , 300 )) return image, label # 使用上面的实用函数预处理图像 augmented_training_data = train_data.map ( augment_images) # 在训练前打乱并创建批次 train_batches = augmented_training_data.shuffle( 1024 ).batch( 32 )
过滤掉损坏的图像
在处理大量现实世界的图像数据时,损坏的图像是常有的事。让我们过滤掉标题中不包含字符串“JFIF”的编码不良的图像。
import os
num_skipped = 0
for folder_name in ("Cat", "Dog"):
folder_path = os.path.join("PetImages", folder_name)
for fname in os.listdir(folder_path):
fpath = os.path.join(folder_path, fname)
try:
fobj = open(fpath, "rb")
is_jfif = tf.compat.as_bytes("JFIF") in fobj.peek(10)
finally:
fobj.close()
if not is_jfif:
num_skipped += 1
# Delete corrupted image
os.remove(fpath)
print("Deleted %d images" % num_skipped)
生成Dataset
image_size = (300, 300) batch_size = 128 train_ds, val_ds = tf.keras.utils.image_dataset_from_directory( "PetImages", validation_split=0.2, subset="both", seed=1337, image_size=image_size, batch_size=batch_size, )
可视化数据
这是训练数据集中的前 9 张图片。如你所见,标签 1 是“狗”,标签 0 是“猫”。
import matplotlib.pyplot as plt
plt.figure(figsize=(6, 6))
for images, labels in train_ds.take(1):
for i in range(9):
ax = plt.subplot(3, 3, i + 1)
plt.imshow(images[i].numpy().astype("uint8"))
plt.title(int(labels[i]))
plt.axis("off")
使用图像数据增强
如果您没有大型图像数据集,最好通过对训练图像应用随机但现实的变换(例如随机水平翻转或小幅随机旋转)来人为地引入样本多样性。这有助于让模型接触训练数据的不同方面,同时减缓过拟合。
data_augmentation = keras.Sequential(
[
layers.RandomFlip("horizontal"),
layers.RandomRotation(0.1),
]
)
data_augmentation让我们通过反复应用数据集中的第一个图像来直观地看到增强样本的样子:
plt.figure(figsize=(6, 6))
for images, _ in train_ds.take(1):
for i in range(9):
augmented_images = data_augmentation(images)
ax = plt.subplot(3, 3, i + 1)
plt.imshow(augmented_images[0].numpy().astype("uint8"))
plt.axis("off")
配置数据集以提高性能
我们将数据增强应用到我们的训练数据集,并确保使用缓冲预取,这样我们就可以从磁盘中获取数据而不会导致 I/O 阻塞:
# 将 `data_augmentation` 应用于训练图像。 train_ds = train_ds.map( lambda img, label: (data_augmentation(img), label), num_parallel_calls=tf.data.AUTOTUNE, ) # 在 GPU 内存中预取样本有助于最大限度地提高 GPU 利用率。 train_ds = train_ds.prefetch(tf.data.AUTOTUNE) val_ds = val_ds.prefetch(tf.data.AUTOTUNE)构建分类器
这看起来会很熟悉,因为它与我们之前构建的模型几乎相同。关键区别在于输出只是一个 S 激活单元。这是因为我们只处理两个类。
classCustomModel(Sequential): def __init__(self): super(CustomModel, self).__init__() self.add(Conv2D(16, input_shape=(300, 300, 3), kernel_size=(3, 3), activation='relu', padding='same')) self.add(MaxPooling2D(pool_size=(2, 2))) self.add(Conv2D(32, kernel_size=(3, 3), activation='relu', padding='same')) self.add(MaxPooling2D(pool_size=(2, 2))) self.add(Conv2D(64, kernel_size=(3, 3), activation='relu', padding='same')) self.add(MaxPooling2D(pool_size=(2, 2))) self.add(Conv2D(128, kernel_size=(3, 3), activation='relu', padding='same')) self.add(GlobalAveragePooling2D()) self.add(Dense(1, activation='sigmoid')) # Instantiate the custom model model = CustomModel() # Display the model summarymodel.summary()损失可以根据上次进行调整,以仅处理两个类别。为此,我们选择binary_crossentropy。
# 使用 GPU 进行训练大约需要 30 分钟。 #如果您的本地机器上没有GPU,请随意使用 model.compile(loss='binary_crossentropy', metrics=['accuracy'], optimizer=tf.keras.optimizers.RMSprop(lr=0.001)) model.fit(train_ds, epochs=25, validation_data=val_ds,)
测试模型
让我们下载一些图像并看看类别激活图是什么样子的。
!wget -O cat1.jpg https://storage.googleapis.com/laurencemoroney-blog.appspot.com/MLColabImages/cat1.jpg !wget -O cat2.jpg https://storage.googleapis.com/laurencemoroney-blog.appspot.com/MLColabImages/cat2.jpg !wget -O catanddog.jpg https://storage.googleapis.com/laurencemoroney-blog.appspot.com/MLColabImages/catanddog.jpg !wget -O dog1.jpg https://storage.googleapis.com/laurencemoroney-blog.appspot.com/MLColabImages/dog1.jpg !wget -O dog2.jpg https://storage.googleapis.com/laurencemoroney-blog.appspot.com/MLColabImages/dog2.jpg
# utility function to preprocess an image and show the CAM def convert_and_classify(image): # load the image img = cv2.imread(image) # preprocess the image before feeding it to the model img = cv2.resize(img, (300,300)) / 255.0 # add a batch dimension because the model expects it tensor_image = np.expand_dims(img, axis=0) # get the features and prediction features,results = cam_model.predict(tensor_image) # generate the CAM show_cam(tensor_image, features, results) convert_and_classify('cat1.jpg') convert_and_classify('cat2.jpg') convert_and_classify('catanddog.jpg') convert_and_classify('dog1.jpg') convert_and_classify('dog2.jpg')审核编辑:黄飞
-
滤波器
+关注
关注
161文章
7795浏览量
177993 -
计算机视觉
+关注
关注
8文章
1698浏览量
45974 -
python
+关注
关注
56文章
4792浏览量
84627 -
cnn
+关注
关注
3文章
352浏览量
22203 -
卷积神经网络
+关注
关注
4文章
367浏览量
11863
原文标题:CNN的原理详解及代码实战(人手都会)
文章出处:【微信号:vision263com,微信公众号:新机器视觉】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论