 LabVIEW操作InfluxDB数据库应用特点和原理概念
LabVIEW操作InfluxDB数据库应用特点和原理概念
在测试系统中,数据存储通常是不可或缺的一环,面对少量数据时,我们可以采用本地文件保存的方式,进行存储查看;而面对大量实时数据时,例如在监控场景,如运维和IOT(物联网)领域,通常会有监控传感器和系统的性能指标等数据需要存储,这时对于时序型数据库就有了很好的应用场景。小编近期使用到的一种时序型数据库——InfluxDB,对于InfluxDB的集成官方有一组API和工具,但大多适用于文本语言,查询许多资料,关于LabVIEW对此数据库的操作教程甚少,所以今天小编分享下使用LabVIEW实现对InfluxDB数据库的连接、写入、查询等操作。
本文分享:
InfluxDB介绍
LabVIEW Client of InfluxDBV2.x教程
一、InfluxDB介绍
InfluxDB 是一个用于存储和分析时间序列数据的开源数据库,由 Golang 语言编写,过多的概念小编在这里就不多赘述了,主要介绍下应用到的特点和原理概念。进一步了解可查看官方说明文档。
1、特点
内置 HTTP 接口,使用方便
数据可以打标记,这样查询可以很灵活
类 SQL 的查询语句
安装管理很简单,并且读写数据很高效
能够实时查询,数据在写入时被索引后就能够被立即查出
2、原理概念
写入协议:InfluxDB 行协议
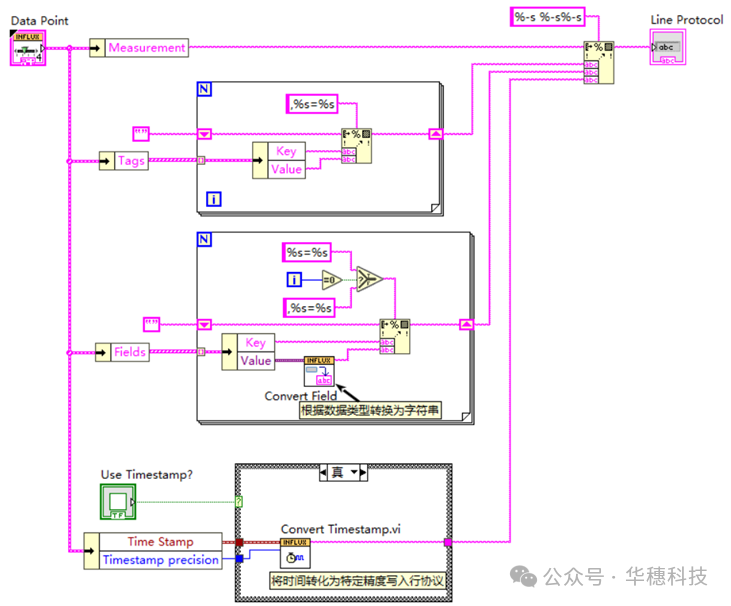
InfluxDB的行协议是一种写入数据点到InfluxDB的文本格式。必须要是这样的格式的数据点才能被Influxdb解析和写入成功,当然除非你使用一些其他服务插件。一行数据由4种元素构成:measurement(测量名称)、Tag Set(标签集)、Field Set(字段集)、Timestamp(时间戳)。

(1)measurement(测量名称)
必需
测量的名称。每个数据点都必须声明自己是哪个测量里面,不可省略。
大小写敏感
不可以下划线_开头
(2)Tag Set(标签集)
标签应该用在一些值的范围有限的,不太会变动的属性上。比如传感器的类型和id等等。在InfluxDB中一个Tag相当于一个索引。给数据点加上Tag有利于将来对数据进行检索。但是如果索引太多了,就会减慢数据的插入速度。
可选
键值关系使用=表示
多个键值对之间使用英文逗号分隔
标签的键和值都区分大小写
标签的键不能以下划线_开头
键的数据类型:字符串
值的数据类型:字符串
(3)Field Set(字段集)
必需
一个数据点上所有的字段键值对,键是字段名,值是数据点的值。
一个数据点至少要有一个字段。
字段集的键是大小写敏感的。
字段
键的数据类型:字符串
值的数据类型:浮点数|整数|无符号整数|字符串|布尔值
(4)Timestamp(时间戳)
可选
数据点的Unix时间戳,每个数据点都可以指定自己的时间戳。
如果时间戳没有指定。那么InfluxDB就使用当前系统的时间戳。
数据类型:Unix timestamp
如果你的数据里的时间戳不是以纳秒为单位的,那么需要在数据写入时指定时间戳的精度。
协议中的数据类型及其格式:
空格:行协议中的空格决定了InfluxDB如何解释数据点。第一个未转义的空格将测量值&Tag Set(标签集)与Field Set(字段集)分开。第二个未转义空格将Field Set(字段级)和时间戳分开。
Float(浮点数):IEEE-754标准的64位浮点数。这是默认的数据类型。
Integer(整数):有符号64位整数。需要在数字的尾部加上一个小写数字i。
UInteger(无符号整数):无符号64位整数。需要在数字的尾部加上一个小写数字u。
String(字符串):普通文本字符串,长度不能超过64KB
Boolean(布尔值)
Unix Timestamp(Unix时间戳)
注释:以井号#开头的一行会被当做注释。
二、安装部署,初始化配置
安装和部署方式不唯一,这里分享下小编使用到的方法:
数据库版本:InfluxDB OSSv2.7.1
系统环境:Win10专业版
安装
安装 InfluxDB |InfluxDB OSS v2 文档 (influxdata.com)
从以上官网链接下载后会看到一个.zip文件,将其解压。
部署
打开cmd,输入‘influxd.exe的文件地址’,回车。
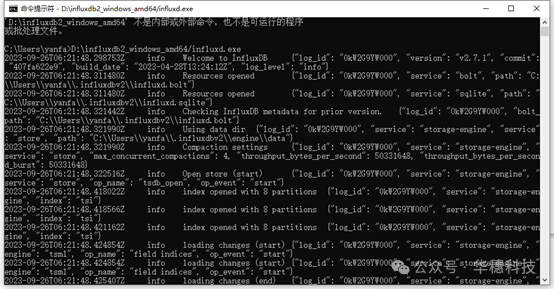
浏览器打开http://localhost:8086。
初始化配置
点击GET STARTED 按钮,进入下一个步骤(添加用户)。
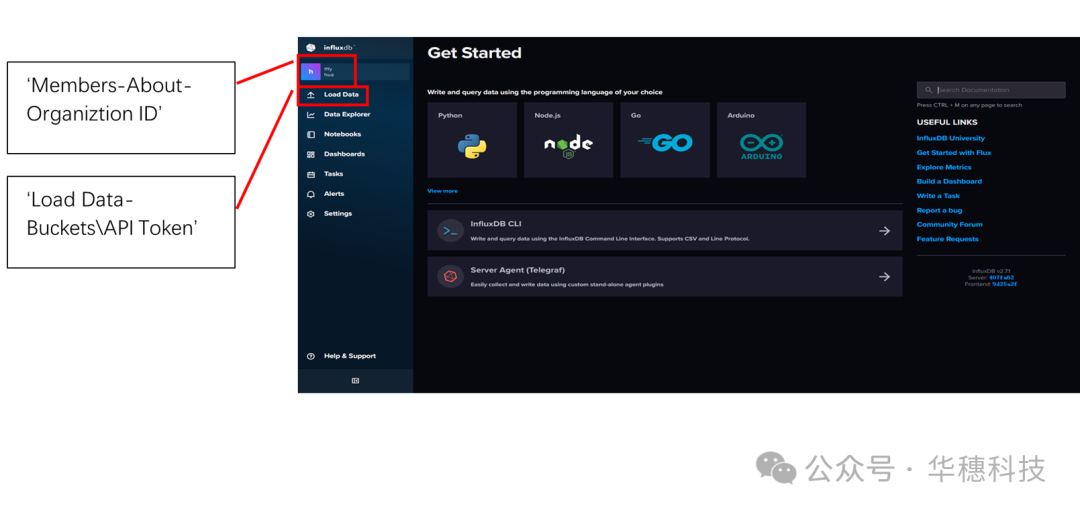
可以留意下clone你的Token、Organizition和organization id(客户端连接时要用)。Bucket用于存放数据的篮子相当于Database。
?API Token 是干什么用的
简单来说,influxdb 会向外暴露一套HTTP API。所以,在InfluxDB中,对权限的管理主要就体现在API的Tokens上。客户端会将 token放到http的请求头上,influxdb 服务端就根据客户端发来的请求头部的token,来判断你能不能对某个存储桶读写,能不能删除存储桶,创建仪表盘等。
配置完成
Token、Organization忘记也可从这里查询:
三、程序Demo介绍
依赖工具包:i3 JSON
目前实现了连接、错误分析处理、写入和查询功能。上文有介绍到InfluxDB内置 HTTP 接口,所以使用LabVIEW中HTTP客户端的API进行实现。
以下介绍均以 ‘步骤功能:语言(程序Demo截图)’形式介绍
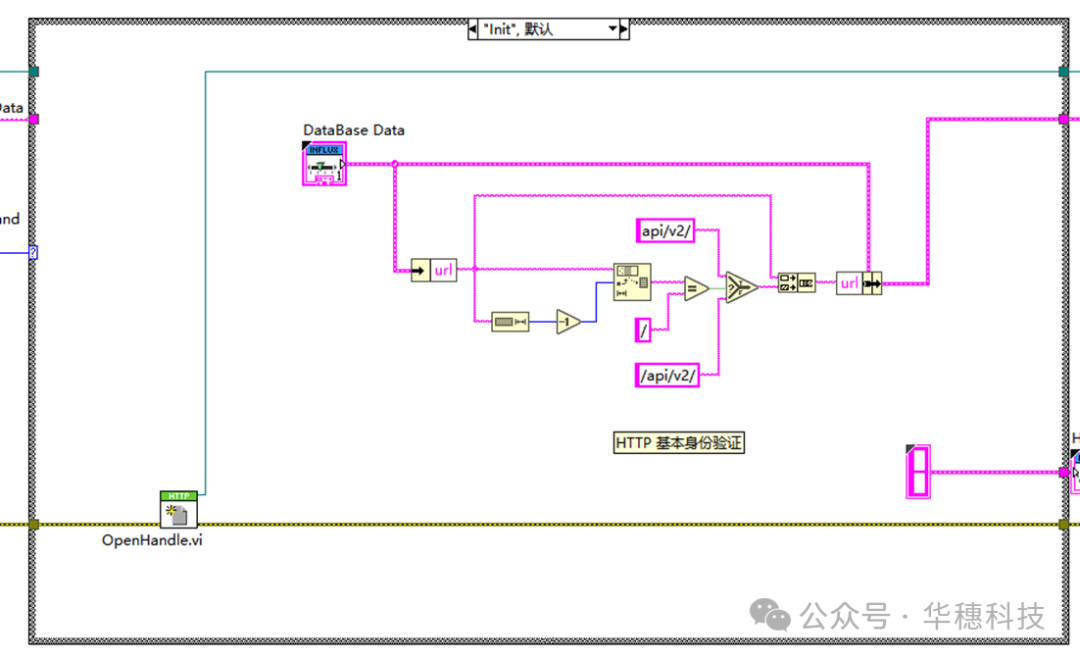
1、连接
基本身份验证:‘url’api/v2/authorizations
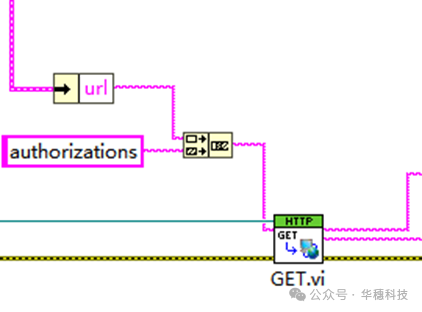
Token验证:Authorization: Token INFLUX_API_TOKEN
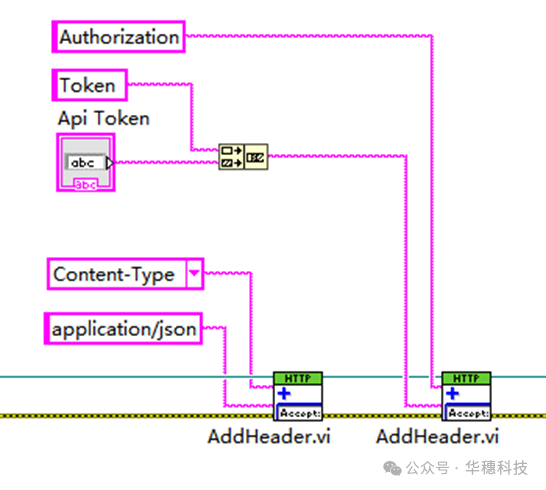
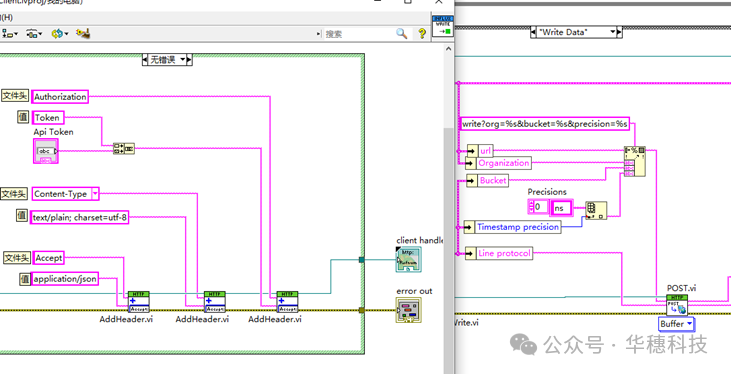
2、数据写入
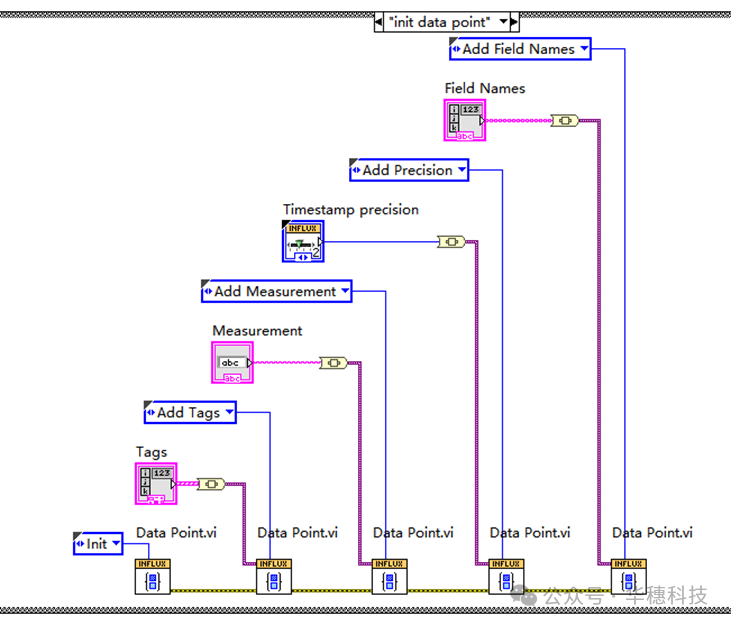
先将measurement(测量名称)、field name(字段名)、precision(时间精度)写入:
其次将field values(数据)、time stamp(时间戳)转换为字符串的格式,组成行协议写入:
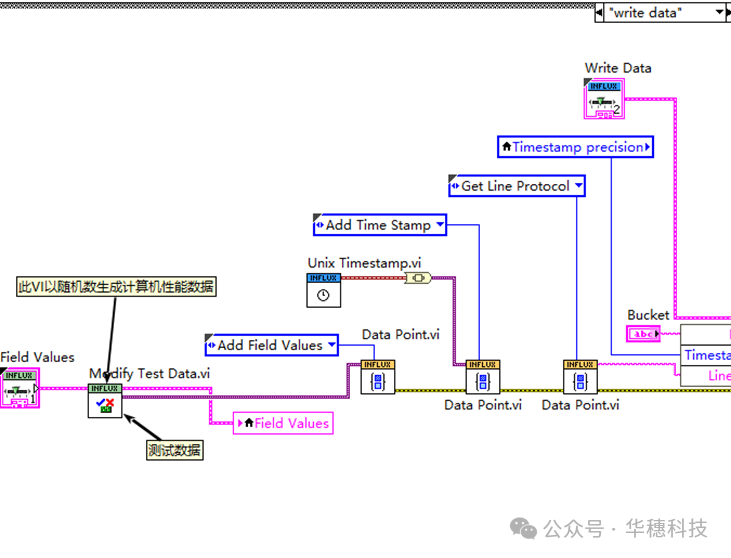
最后发送写入数据的报文请求:
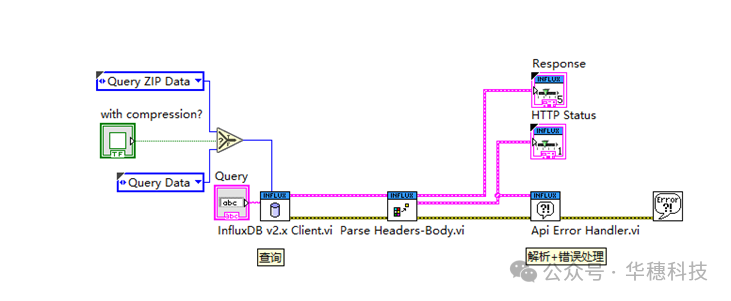
3、查询
以Flux语法查询,查询语句的释议太多,有需要的还需自行查看Query data with Flux | InfluxDB OSS v2 Documentation (influxdata.com)
这里简单摘一点:
from(bucket: "example-bucket") #需要查询的bucket
|> filter(fn: (r) => r._measurement == "example-measurement" and r.tag == "example-tag") #measurement名 tag名
|> filter(fn: (r) => r._field == "example-field")
|> range(start:-1h) #相对时间范围 (最近1小时)
|> range(start:-1h, stop: -10m) #最近1h到最近10分钟
|> aggregateWindow(every: 1s, fn: last, createEmpty: false) #数据可视化
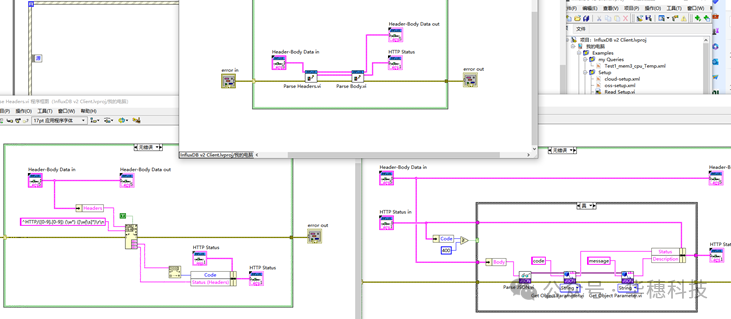
这里实现了两种方式查询:聚合和非聚合。区别在于发送的header不一样,如下图:
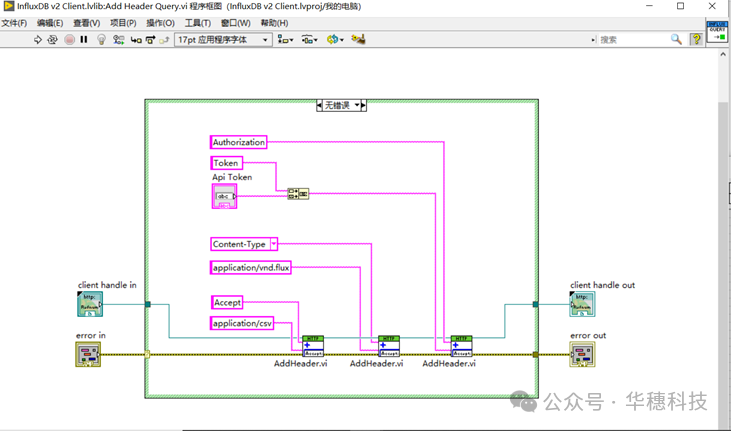
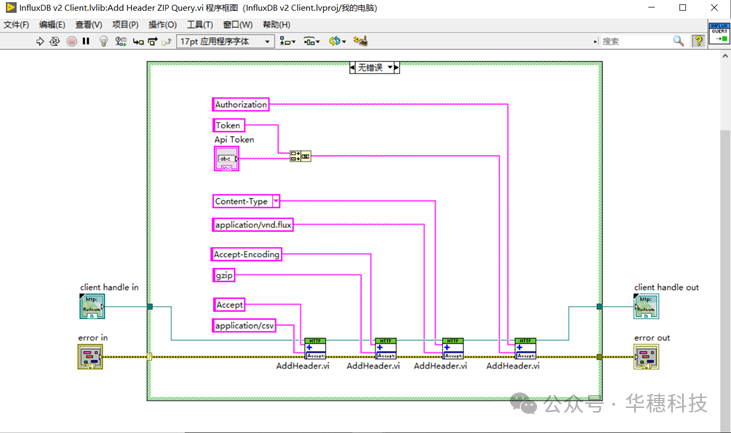
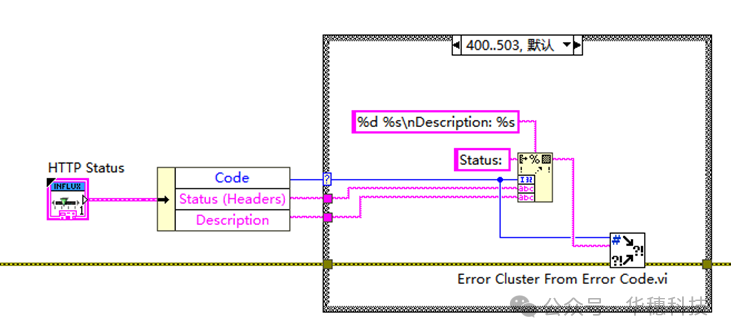
4、错误处理
根据官网API帮助文档中API操作返回的HTTP响应代码,解析Body和Headers文件而设计。(一般代码≥400为错误)
四、内容总结
1.InfluxDB的特点和原理概念
2. 安装部署及初始化配置InfluxDB
3.使用LabVIEW实现对InfluxDB的连接、写入、查询、错误分析的操作
审核编辑:黄飞
-
LabVIEW
+关注
关注
1970文章
3654浏览量
323267 -
数据库
+关注
关注
7文章
3794浏览量
64355 -
UNIX
+关注
关注
0文章
296浏览量
41476
原文标题:教程 | LabVIEW操作InfluxDB数据库
文章出处:【微信号:华穗科技,微信公众号:华穗科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
labview 数据库操作问题
(专题)Labview 对于大数据的操作 途径:使用数据库
关于Labview数据库操作的内存问题
Labview对SQL Server数据库连接并操作
ADO和LabSQL在数据库操作方面的应用
LabVIEW访问Access数据库的研究
数据库的设计概念总结
influxdb+grafana+nodemcu






 工商网监
工商网监
评论