 MCX N系列微处理器之NPU使用方法简析
MCX N系列微处理器之NPU使用方法简析

MCX N系列是高性能、低功耗微控制器,配备智能外设和加速器,可提供多任务功能和高能效。部分MCX N系列产品包含恩智浦面向机器学习应用的eIQNeutron神经处理单元(NPU)。低功耗高速缓存增强了系统性能,双块Flash存储器和带ECC检测的RAM支持系统功能安全,提供了额外的保护和保证。这些安全MCU包含恩智浦EdgeLock安全区域Core Profile,根据设计安全方法构建,提供具有不可变信任根和硬件加速加密的安全启动。
MCX N系列微型处理器:MCXN94xMCXN54x基于两个高性能的Arm Cortex-M33核心构建,核心运行速度可达150 MHz。它配备了2MB的板载闪存(Flash),并可选择配置完整的ECC(错误校正码)RAM,同时集成了一款专属的神经处理单元(eIQ Neutron NPU)。该NPU在机器学习(ML)任务处理速度上,比M33核心快出40倍,显著减少了设备的唤醒时间,并有效降低了总体功耗。
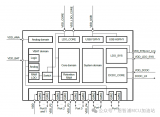
eIQ Neutron NPUs能够支援包括CNN(卷积神经网络)、RNN(循环神经网络)、TCN(时间卷积网络)以及Transformer等多种类型的神经网络。利用eIQ Neutron NPU进行机器学习应用的开发,将得到eIQ机器学习软件开发环境的全方位支持。eIQ Neutron NPU系统框图如下所示:
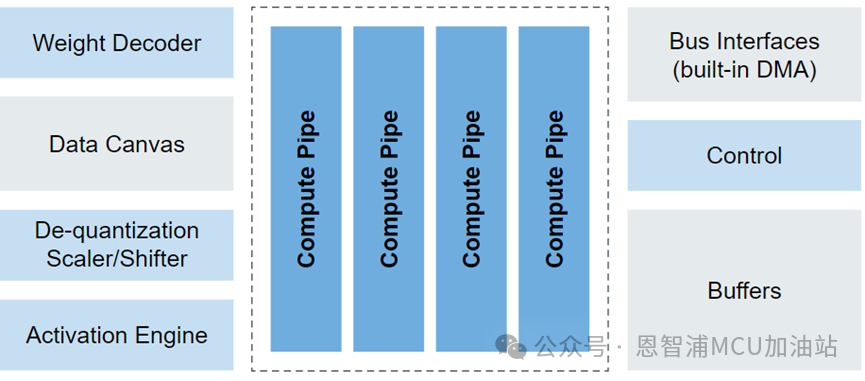
NPU由计算单元,权重解码器,量化器,优化函数加速器,RAM以及DMA快速访问接口组成,其ML算力可达4.8G。强大的算力给ML推理带来极大的加速,在TinyML Perf benchmark测试模型上的性能对比如下图所示:
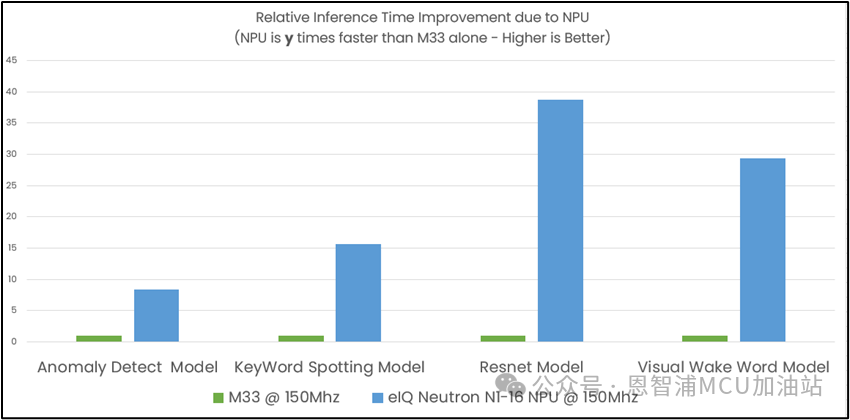
图中表示NPU的性能提升倍数,绿色柱体代表M33,蓝色柱体代表NPU基于M33的提升倍数。从图中可以看到Anomaly Detect异常检测模型NPU提供8倍的性能提升,Keyword spotting关键词检测模型NPU提供15倍的提升,Resnet图像分类模型NPU提供38倍的性能提升,VisualWake Word模型NPU提供28倍的性能提升。
对于不同类型的模型,NPU的加速效果略有不同。Resnet主要是由卷积网络构成,NPU的主要计算单元是乘累加计算器,并且通道间权重是共享的,所以NPU对卷积网络性能提升是最大的,异常检测模型主要由全连接网络组成,全连接网络的权重无法共享故而无法最大限度的利用NPU,所以全连接网络的加速是最小的。
推理速度的提升必然会减少核心的运行时间从而降低了整体的功耗,打开NPU会额外增加1.4mA(3.3V)的电流,相比运算速度的提升,这个增量可以忽略不记。
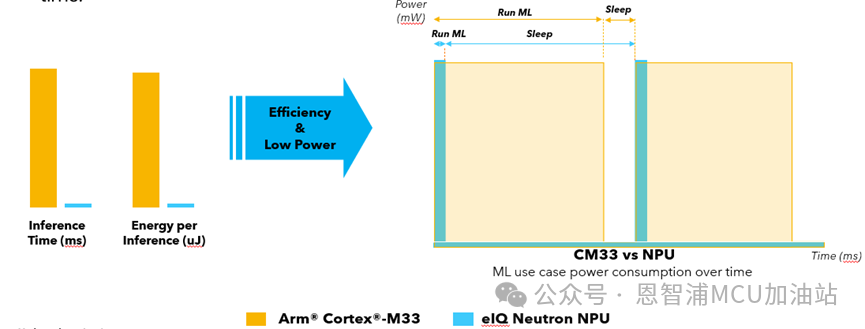
从运行时序图上看,NPU使能后Core的大部分时间是在休眠状态,如果不在NPU上推理模型,Core基本一直处于运行状态,NPU节能效果显而易见。
审核编辑:刘清
-
微控制器
+关注
关注
49文章
8890浏览量
165909 -
加速器
+关注
关注
2文章
841浏览量
40278 -
神经网络
+关注
关注
42文章
4844浏览量
108223 -
机器学习
+关注
关注
67文章
8567浏览量
137288 -
NPU
+关注
关注
2文章
387浏览量
21385
原文标题:MCX N系列微处理器之NPU使用方法简介
文章出处:【微信号:NXP_SMART_HARDWARE,微信公众号:恩智浦MCU加油站】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
恩智浦MCX A系列微处理器之供电系统
恩智浦 MCX N系列之电源管理(MCX N94/54与MCX N23)
恩智浦MCU解析 MCX A系列微处理器之系统架构


什么是ARM处理器 ARM处理器有哪些系列
微控制器与微处理器简析
处理器系列之X86微处理器体系结构

恩智浦全新MCX N微控制器推出!助力实现高性能、低功耗的边缘安全智能
npu是什么处理器?NPU卡是什么?
恩智浦推出首次搭载专属神经处理单元(NPU)的MCX N系列!

MCX N系列微处理器之NPU的入门使用方法介绍



评论