 基于MADDPG迭代的编队协同控制框架
基于MADDPG迭代的编队协同控制框架
作者:文永明,李博研,张宁宁,李小建,熊楚依,刘洁玺
采用深度强化学习算法解决了多智能体编队协同控制问题。基于多智能体深度确定性策略梯度算法(MADDPG)构建分布式编队控制架构,并结合集中式训练-分布式执行框架进行求解。针对多智能体环境不稳定问题,依据单个智能体的局部信息构建对应奖励函数。针对大规模编队协同控制,实现了多个多智能体环境下的算法训练与评估。试验结果表明,应用该算法的多智能体能够完成协同任务,且所有智能体都可得到合理的协同控制策略。
0引言
多智能体系统(MAS)由若干单独控制的、通过无线网络连接的智能体构成,在诸如控制、编队、分配、博弈和分布式估计等问题中广泛研究并取得了一定进展。在已知系统动力学模型基础上,研究者们对多智能体系统基础理论开展了大量研究。传统的系统识别试验依据输入-输出数据确定分析模型,但在实际应用中,复杂过程建模困难且昂贵。此外,传统的控制方法在与复杂环境交互时存在局限性,固定策略不能应用于不同环境或任务场景中。深度强化学习关注一个智能体的策略模型,借鉴了不完全可知马尔可夫决策中的最优控制思想,智能体通过与环境交互来最大化长期累积奖励,控制优化与策略学习之间存在着紧密联系。因此,深度强化学习技术在系统控制方面存在广阔的应用前景。 深度强化学习算法分为基于值的强化学习算法和基于策略的强化学习算法2类。
1) Q学习及深度Q学习算法是最常用且直接的基于值的算法,它通过动作值函数来获得最优策略。通过每个智能体学习一个独立的最优方程,将基于值的算法直接应用于多智能体系统。然而,在学习过程中邻居智能体更新时,当前智能体的奖励和状态转移等信息也会发生改变。在这种情况下,环境就会出现不稳定性问题,并且也不再满足马尔可夫性,最终导致基于值的算法的收敛性得不到保证。
2) 基于策略的算法是另一类深度强化学习算法,该类算法通过独立的神经网络来近似随机策略。执行者-评估者 (Actor-Critic, AC) 算法结合了基于值和基于策略的算法,其中执行者代表生成动作的策略函数,评估者代表评价动作奖励的值逼近器。深度确定性策略梯度算法(DDPG)是一种无模型的AC算法,它结合了确定性策略梯度和深度Q学习算法,其中执行者和评估者均用深度神经网络进行逼近。多智能体深度确定性策略梯度方法(MADDPG)将DDPG扩展到一个多智能体协同完成的任务环境,在这个环境中智能体智能获得局部信息。MADDPG是一个针对多智能体场景重新设计的AC模型,旨在解决不断变化的环境和多智能体间的复杂问题。
1理论基础
1.1 代数图论


1.2 问题描述

2基于MADDPG迭代的编队协同控制框架
2.1 传统控制设计

2.2 编队协同控制算法框架设计

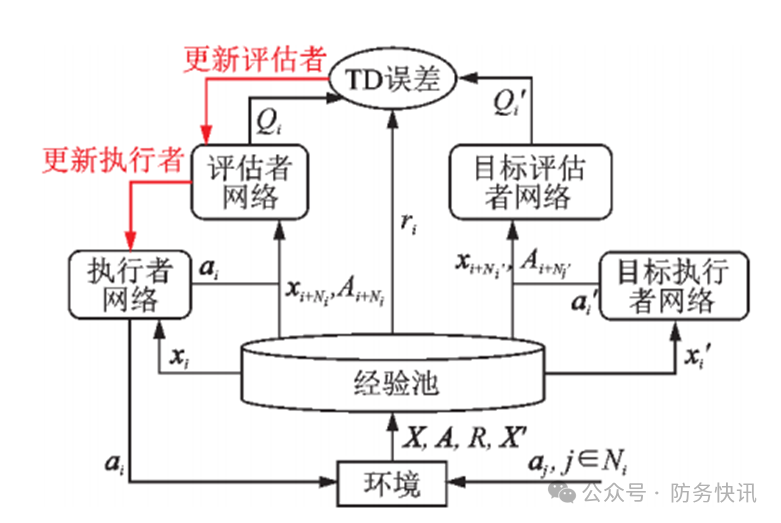
图1 编队控制算法框架
2.3 学习目标设计


2.4 编队协同控制算法流程


3试验结果与分析
3.1 试验设置

图2 试验交互拓扑图
3.2 结果与分析
本文在3.1节展示的环境中运行并评估本文算法,仿真结果如图3所示,图4给出了智能体训练前后运动轨迹对比。 4个智能体的长期累计奖励得分如图3(a)所示。在学习过程中得分是逐渐增加的,并且在50 000次迭代后收敛到6以内,这意味着MAS在50 000次迭代后可以有效消除初始误差;同时,这个得分也意味着MAS实现理想编队和到达目标位置所需的代价。图3(b)是智能体最后50次训练收敛时的稳定奖励。由图可见,4个智能体可以快速实现稳定编队,且跟踪误差同样意味着奖惩可以在1 s内收敛至接近于0。 4个智能体在训练前后的初始、1 s、2 s、3 s和4 s编队状态如图4所示。图中蓝色点为领航者,对应图2中0号蓝色点,粉色、灰色和绿色点分别对应图2中1号粉色点、2号紫色点和3号橙色点。试验结果表明,由于缺乏环境的先验知识,MAS在首次尝试时会偏离队形。当智能体通过在环境中反复试错积累经验,MAS会收敛形成一个稳定的编队。最终,领航者可以到达目标位置且追随者可以与领航者保持编队位置稳定。
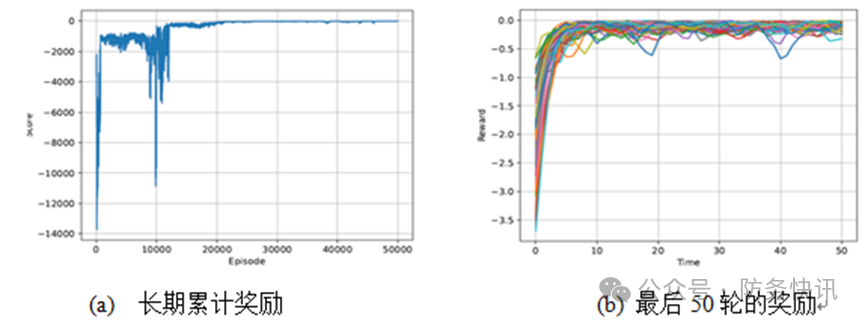
图 3 试验环境下仿真结果

图 4 智能体训练前后状态对比
4结束语
本文采用多智能体策略梯度算法,结合集中训练和分布执行的框架,研究并求解多智能体协同编队控制问题,设计构建了一种基于多智能体深度确定性策略梯度算法的分布式编队控制框架,并给出了算法的训练流程。通过对多智能体合作环境的仿真训练与评估,验证了本文算法的有效性。试验结果表明,本文算法能够使智能体在动力学模型先验知识未知的情况下协同完成任务,有助于解决数学模型过于复杂而难以识别的控制问题。
审核编辑:黄飞
-
神经网络
+关注
关注
42文章
4771浏览量
100698 -
算法
+关注
关注
23文章
4606浏览量
92811 -
无线网络
+关注
关注
6文章
1431浏览量
65924 -
深度学习
+关注
关注
73文章
5500浏览量
121100
原文标题:基于深度强化学习的多智能体编队协同控制
文章出处:【微信号:AI智胜未来,微信公众号:AI智胜未来】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【飞控开发高级篇7】疯壳·开源编队无人机-编队飞行
【飞控开发高级教程7】疯壳·开源编队无人机-编队飞行
【疯壳·无人机教程29】开源编队无人机-编队飞行
基于二层邻居信息的多智能体系统编队控制
基于迭代填充的内存计算框架分区映射算法
多无人机协同编队飞行控制的关键技术和发展展望

集群无人艇协同微波网络通信技术探讨
想做无人机编队表演?需要掌握哪些?






 工商网监
工商网监
评论