 利用NVIDIA组件提升GPU推理的吞吐
利用NVIDIA组件提升GPU推理的吞吐

利用NVIDIA 组件提升GPU推理的吞吐
本实践中,唯品会 AI 平台与 NVIDIA 团队合作,结合 NVIDIA TensorRT 和 NVIDIA Merlin HierarchicalKV(HKV)将推理的稠密网络和热 Embedding 全置于 GPU 上进行加速,吞吐相比 CPU 推理服务提升高于 3 倍。
应对GPU推理上的难题
唯品会(NYSE: VIPS)成立于 2008 年 8 月,总部设在中国广州,旗下网站于同年 12 月 8 日上线。唯品会主营业务为互联网在线销售品牌折扣商品,涵盖名品服饰鞋包、美妆、母婴、居家、生活等全品类。
唯品会 AI 平台服务于公司搜索、推荐、广告等业务团队,提供公司级一站式服务平台。搜索、推荐、广告等业务旨在通过算法模型迭代,不断优化用户购买体验,从而提升点击率和转化率等业务指标,最终实现公司销售业绩增长。
在使用 GPU 打开推理算力天花板过程中,遇到了如下问题:
稠密网络,如何获取更好的 GPU 推理性能;
Embedding table 如何使用 GPU 加速查询。
为了解决上面的问题,我们选择使用了 NVIDIA TensorRT 和 Merlin HierarchicalKV。具体原因如下:
稠密网络使用 TensorRT 推理,通过 TensorRT 和自研 Plugin 方式获取更好的推理性能;
HierarchicalKV 是一个高性能 GPU Table 实现,我们将热 Embedding 缓存在 GPU 中,冷 Embedding 则通过内存和分布式 KV 存储,加速查表过程。
GPU推理服务设计方案
AI 平台支持搜索、推荐、广告等所有算法业务,提供大规模分布式训练、推理、实时模型等基础引擎平台,打造属于唯品会自己的 AI 基础能力引擎。
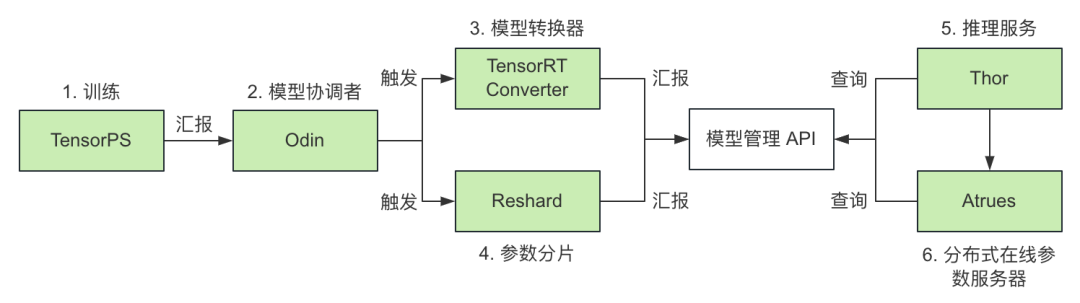
图 1. GPU 推理服务工作流程图
如上图所示,支持 GPU 推理服务,可以分为如下几步:
TensorPS(自研训练框架)
支持离线和实时训练;
离线训练:生成天级全量模型,完成后同步给 Odin;
实时训练:生成小时级别的全量模型和分钟级别的增量模型,完成后同步给 Odin;
2. Odin(模型协调者)
(离线/实时)单机模型的全量模型:触发 TensorRT Converter;
(离线/实时)分布式模型的全量模型:同时触发 TensorRT Converter 和 Reshard;
(离线/实时)单机/分布式模型的增量模型:触发 TensorRT Converter;
3. TensorRTConverter(模型转换器)
将 Dense 网络转换成 TensorRT Engine;
转化完成,如果是全量模型,向模型管理 API 汇报全量版本;如果是增量模型,向模型管理 API 汇报增量版本;
4. Reshard(参数分片模块)
对模型参数分片后,向模型管理 API 汇报版本;
分片后参数,同步到分布式在线参数服务 Atreus;
5. Thor(自研推理服务)
单机模型:通过模型管理 API 获取全量模型版本,拉取模型并启动推理服务 Thor;
分布式模型:需要部署分布式参数服务 Atreus 和推理服务 Thor;
如果开启了实时模型特性,Thor 会定时通过模型管理 API 获取增量版本,拉取并更新增量模型;
6. Atreus(自研分布式在线参数服务)
仅用于分布式模型,可支持 TB 级参数;
如果开启了实时模型特性,Atreus 会定时通过模型管理 API 获取增量版本,拉取并更新增量参数。
GPU模型推理
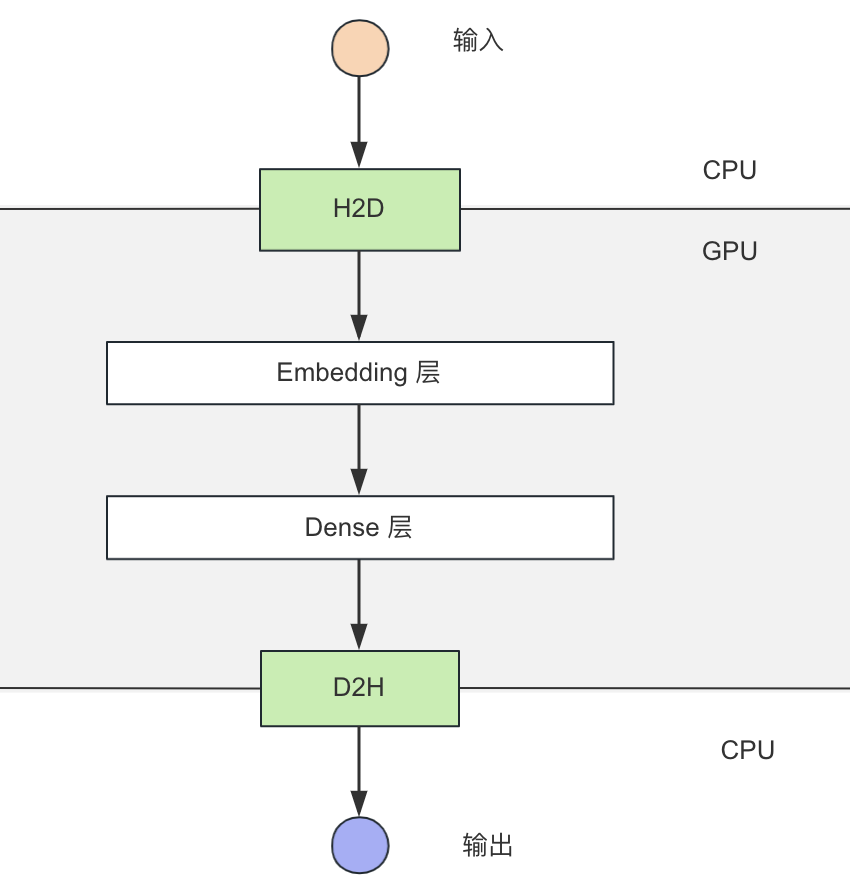
图 2. 前向计算流程图
如上图所示,前向计算可以分为如下几步:
H2D 拷贝(CPU -> GPU);
Embedding 层,使用 GPU Table lookup(GPU);
Dense 层,使用 TensorRT +自研 Plugin 推理(GPU);
D2H 拷贝(GPU -> CPU)。
稠密网络使用TensorRT在GPU上计算
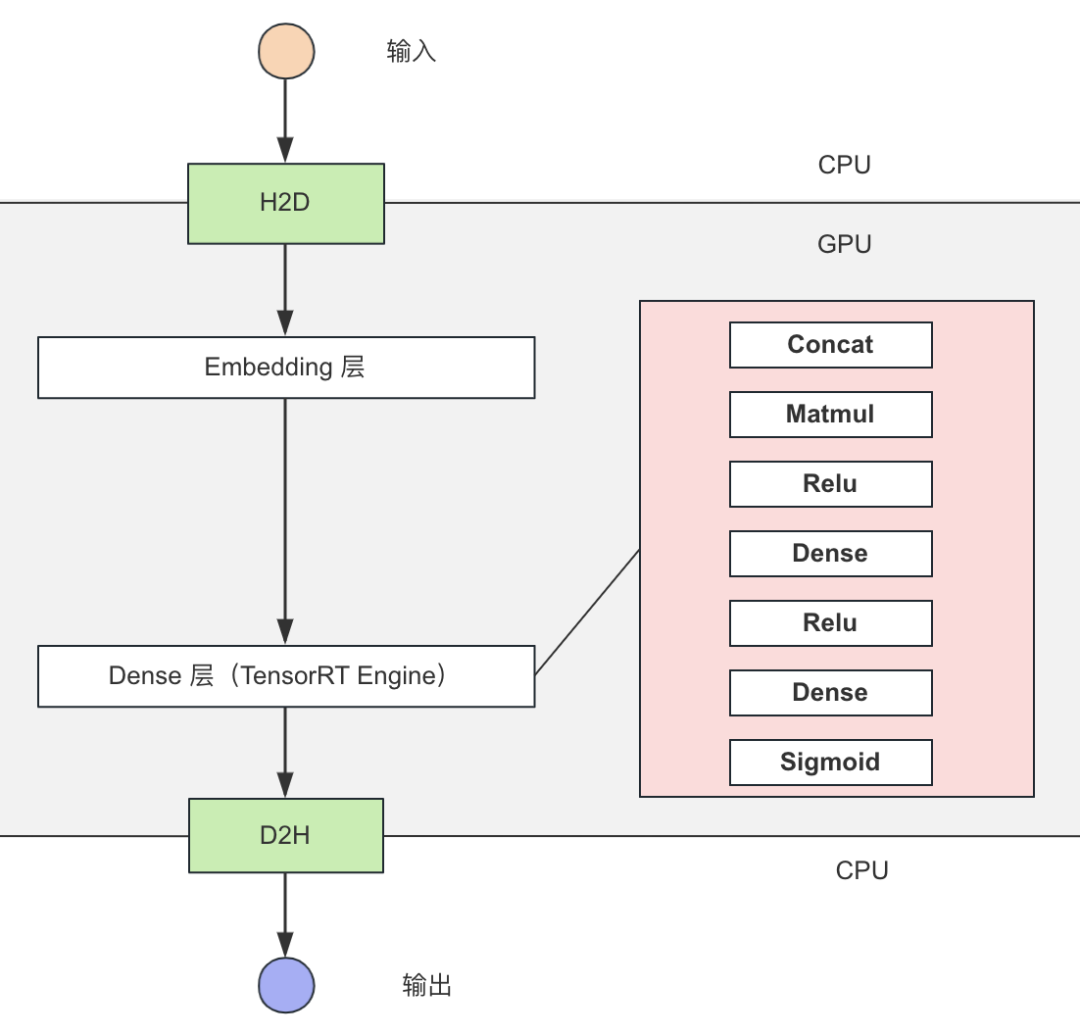
图 3. 稠密网络 TensorRT 推理优化
如上图所示:
稠密网络使用 TensorRT 推理,结合自定义 Plugin 实现推理性能优化。
利用HierarchicalKV实现GPUTablelookup
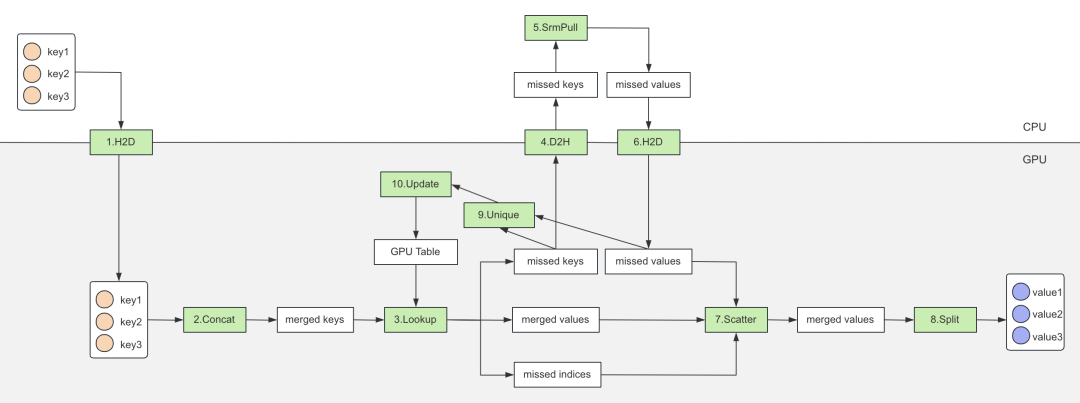
图 4. 基于 HierarchicalKV 的 GPU Table
如上图所示,查表过程可以分为如下几步:
将 keys 拷贝到 GPU;
将 keys concat 成一个大的 merged keys,减少后续查表次数;
merged keys 查 GPU Table,输出 merged values,并输出未命中 missed keys 和 missed indices;
拷贝 missed keys 到 CPU;
查询 Atreus(分布式参数服务器),获取 missed values;
missed values 拷贝到 GPU;
将 missed values 更新到 merged values;
将 merged values 输出 Split 成多个 Tensor(和 keys 一一对应);
对 missed keys 进行去重;
去重之后,异步更新 GPU Table。
TensorRTConverter实现GPU模型转换
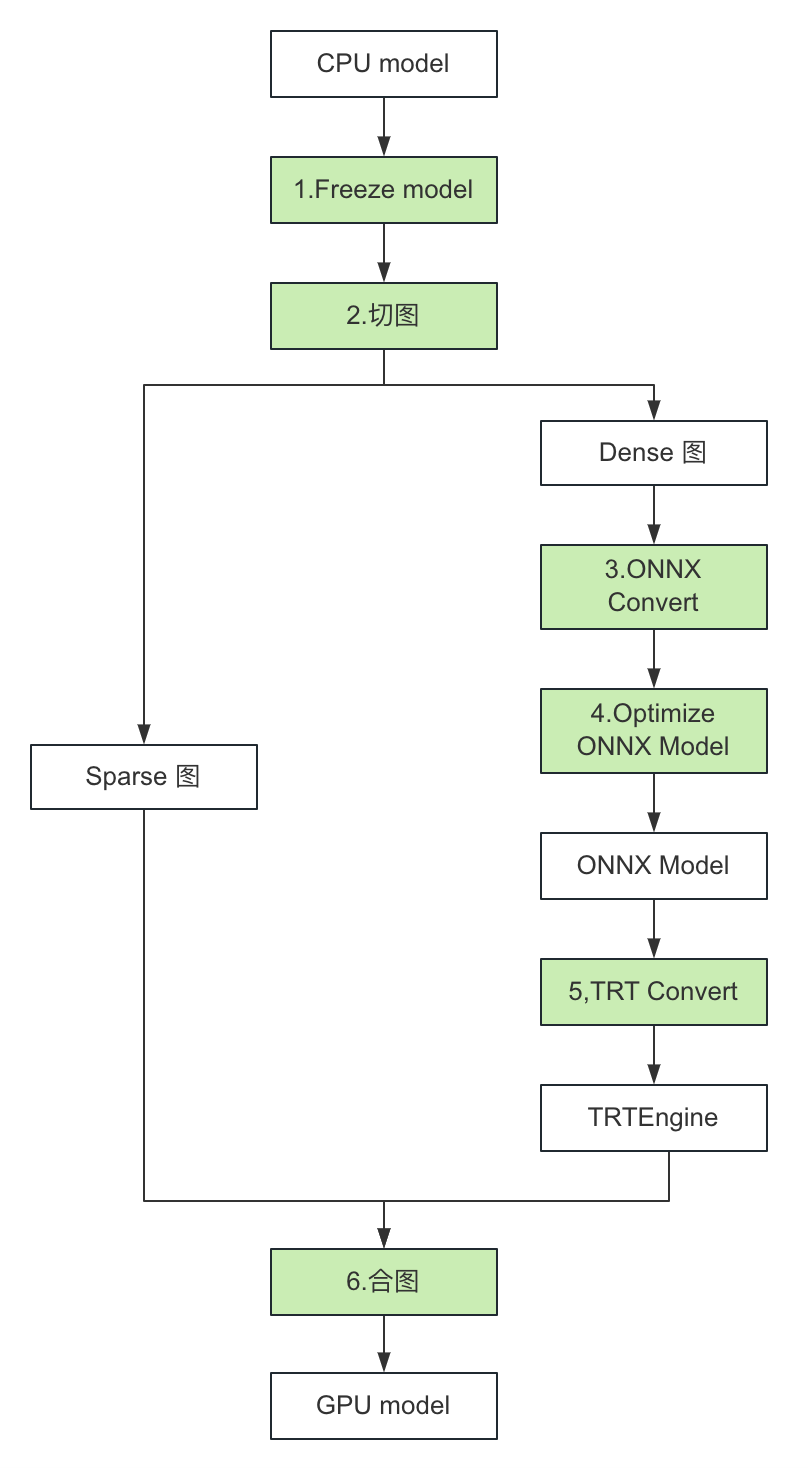
图 5. TensorRT Converter 转换流程
如上图所示,TensorRT Converter 可以分为如下几步:
Freeze CPU 模型;
切分模型 Graph 成 Sparse 和 Dense 两个子图,Sparse 图在 GPU 上执行,Dense 图经过图优化后使用 TensorRT 推理;
Dense 图转化成 ONNX 模型;
优化 ONNX 模型,把图中 OP 替换成自定义的高性能 TensorRT Plugin;
转换 ONNX 模型成 TensorRT Engine;
合并 Sparse 图和 TensorRT Engine 生成 GPU 模型。
自研CUDAKernel,提高性能
GPUTable加速查表
基于 HierarchicalKV 增强了 find 接口,支持获取未命中 keys indices 等信息,在高命中率情况下有更好的性能,并贡献给社区:
void find(const size_type n,
const key_type* keys, // (n)
value_type* values, // (n, DIM)
key_type* missed_keys, // (n)
int* missed_indices, // (n)
int* missed_size, // scalar
score_type* scores = nullptr, // (n)
cudaStream_t stream = 0) const
2. GPU支持CSR(Compressedsparserow)格式的序列特征
根据统计,序列特征有 85%+的数据都是填充值,使用 CSR 格式压缩序列特征可以大幅度减小序列特征大小。考虑到搜推序列数据的特殊性(填充值都在序列尾部),这里仅使用 value 和 offset 两个序列表示原始稀疏矩阵,如下图:
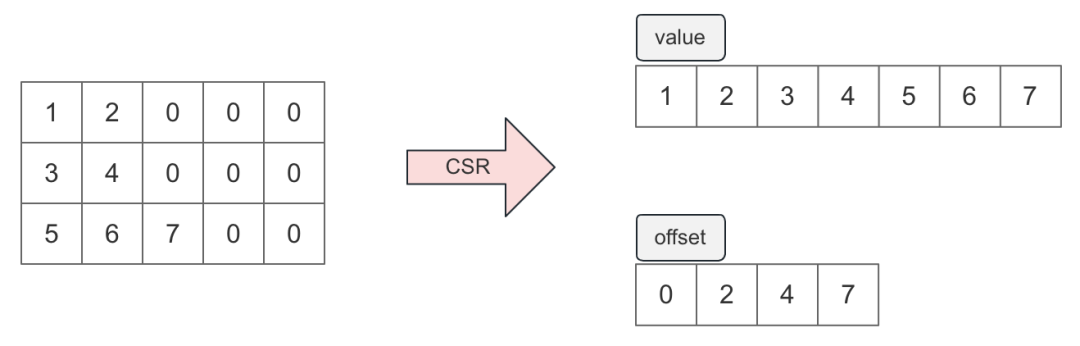
图 6. CSR 的稀疏矩阵
通过 Fusion 的方式,减少 Lookup 过程 CUDA Kernel 数量,提升推理性能。

图 7. Lookup 过程优化对比
优化前:N 个输入对应 N 个 Lookup CUDA Kernel;
优化后:通过提前合并,将 CUDA Kernel 数量减少为 3 个(Concat、Lookup 和 Split)。
通过 Fusion 的方式,减少 CSR 处理过程 CUDA Kernel 数量,提升推理性能,下图以 ReduceSum 举例。
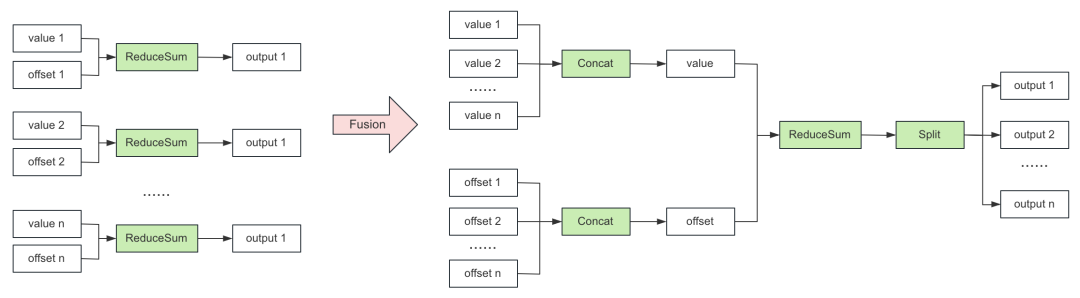
图 8. CSR 处理优化流程
优化前:N 对输入对应 N 个 ReduceSum CUDA Kernel;
优化后:通过提前合并,将 CUDA Kernel 数量减少为 4 个(2 个 Concat,1 个 ReduceSum 和 1 个 Split)。
3.H2D,合并CPU->GPU内存拷贝
搜推模型中有较多的特征输入,GPU 推理中需要将这些 Tensor 从 CPU 拷贝到 GPU,频繁小内存的 cudaMemcpy 会导致性能下降,最佳实践是将这些 Tensor 打包在一块连续内存中,将整个大内存 H2D 拷贝到 GPU。
4.Tile算子融合
搜推模型中有超过 200个 Tile,大量的 Kernel Launch 会带来 GPU 推理性能恶化,最佳实践是进行 Kernel Fusion,在一个大的算子中执行多个小 Kernel,从而充分发挥 GPU 的并发优势。
持续在搜推广场景中GPU加速
唯品会 AI 平台一直追求性能上的极致,未来将会持续与 NVIDIA 技术团队合作,继续探索使用 HierarchicalKV 在训练超大型模型上的 GPU 性能优化,在提升 GPU 性能方面进行不断地探索和实践,也会对 Generative Recommenders 进行探索和实践。
审核编辑:刘清
-
NVIDIA
+关注
关注
14文章
5721浏览量
110230 -
CSR
+关注
关注
3文章
120浏览量
70923 -
GPU芯片
+关注
关注
1文章
308浏览量
6577
原文标题:利用 NVIDIA Merlin HierarchicalKV 实现唯品会在搜推广场景中的 GPU 推理实践
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
NVIDIA-SMI:监控GPU的绝佳起点
NVIDIA 在首个AI推理基准测试中大放异彩
Nvidia GPU风扇和电源显示ERR怎么解决
在Ubuntu上使用Nvidia GPU训练模型
充分利用Arm NN进行GPU推理
NVIDIA Triton推理服务器简化人工智能推理
使用NVIDIA GPU助力美团CTR预测服务升级
利用NVIDIA Triton推理服务器加速语音识别的速度
NVIDIA Triton助力腾讯PCG加速在线推理
NVIDIA助力阿里巴巴天猫精灵大幅提升服务运行效率
腾讯云TI平台利用NVIDIA Triton推理服务器构造不同AI应用场景需求
蚂蚁链AIoT团队与NVIDIA合作加速AI推理
NVIDIA GPU 加速 WPS Office AI 服务,助力打造优质的用户体验



评论