 DPU技术赋能下一代AI算力基础设施
DPU技术赋能下一代AI算力基础设施

4月19日,在以“重构世界 奔赴未来”为主题的2024中国生成式AI大会上,中科驭数作为DPU新型算力基础设施代表,受邀出席了中国智算中心创新论坛,发表了题为《以网络为中心的AI算力底座构建之路》主题演讲,勾勒出在通往AGI之路上,DPU技术赋能下一代AI算力基础设施中的关键作用。
算力是当前人工智能领域发展的关键,是AI时代的“面包”。要训练百万亿参数超大预训练模型,算力基础设施架构优化是提升算力的首要步骤。当前,DPU算力基础已经发展迭代了4到5年,算力领域对DPU的期望和需求已经涵盖计算、网络、存储、安全等多个领域。
中科驭数旨在通过DPU将计算加速、存储加速、网络加速、安全加速及云原生加速等基础设施层深度整合,构建高性能、高集成的AI服务基础架构。公司已基于此打造出涵盖云原生DPU软硬一体加速、RDMA/RoCE AI计算网络、NVMe-oF高性能存储、灵活存算分离架构、DPU硬件级安全隔离以及数据中心资源池化与统一调度的丰富产品矩阵与解决方案,不仅仅能够助力AI算力底座的整体性能提升,也为用户提供了更高效更完整的基础设施解决方案,有力支撑各类AI应用的快速发展。
以中科驭数自研FLEXFLOW-2100R RDMA加速DPU卡为例,该加速卡产品能够将高性能、稳定性、便捷性和通用性融为一体,提供2x100GbE网口的连接能力,支持RoCEv2的硬件卸载能力以及无损网络能力,为国产化业务场景提供微秒级时延和百G带宽的RDMA网络环境,为用户提供灵活和高性能的网络解决方案。同时,适配市面上所有主流支持无损网络的交换机,以及国内外主流服务器和操作系统,可以快速接入现有RDMA网络环境。经实测,KPU FLEXFLOW-2100R在4K以下小文件send、read、write测试场景中,时延数据均在5us以下,最低可达3us,优于国内外主流RDMA智能网卡性能水准。
需要看到的是,随着AI向更多领域渗透,对基础设施的需求将更加多元化、智能化。同样,DPU的成功落地和使用需要经过精心设计和打磨,以满足整个基础设施领域的多样需求。中科驭数将继续秉持着技术创新和开放合作的理念,欢迎服务器厂商、CPU/GPU厂商、操作系统厂商等上下游合作伙伴加入驭数DPU生态,共同推动AI算力底座的发展。
审核编辑:刘清
-
交换机
+关注
关注
23文章
2938浏览量
104909 -
DPU
+关注
关注
0文章
418浏览量
27152 -
人工智能
+关注
关注
1821文章
50385浏览量
267136 -
RDMA
+关注
关注
0文章
102浏览量
9674 -
生成式AI
+关注
关注
0文章
538浏览量
1135
原文标题:通往AGI路上,DPU将如何构建生成式AI时代的坚实算力基石?
文章出处:【微信号:yusurtech,微信公众号:驭数科技】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
智算监控的下半场:从基础设施报警到算力精算师
伟创力携手博通,推进下一代AI液冷解决方案落地

AI算力中心下一代液冷电源架构研究报告
中科曙光scaleX万卡超集群重塑超大规模算力基础设施
设计下一代AI SSD,如何选对PLP电容?

安森美SiC器件赋能下一代AI数据中心变革
科士达全栈解决方案亮相2025 ODCC,驱动绿色AI智算基础设施革新

睿海光电领航AI光模块:超快交付与全场景兼容赋能智算时代——以创新实力助力全球客户构建高效算力底座
摩尔线程“AI工厂”:以系统级创新定义新一代AI基础设施

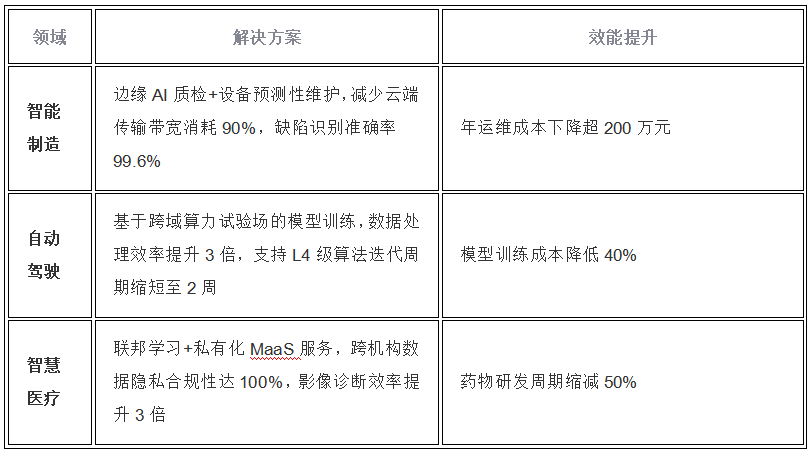
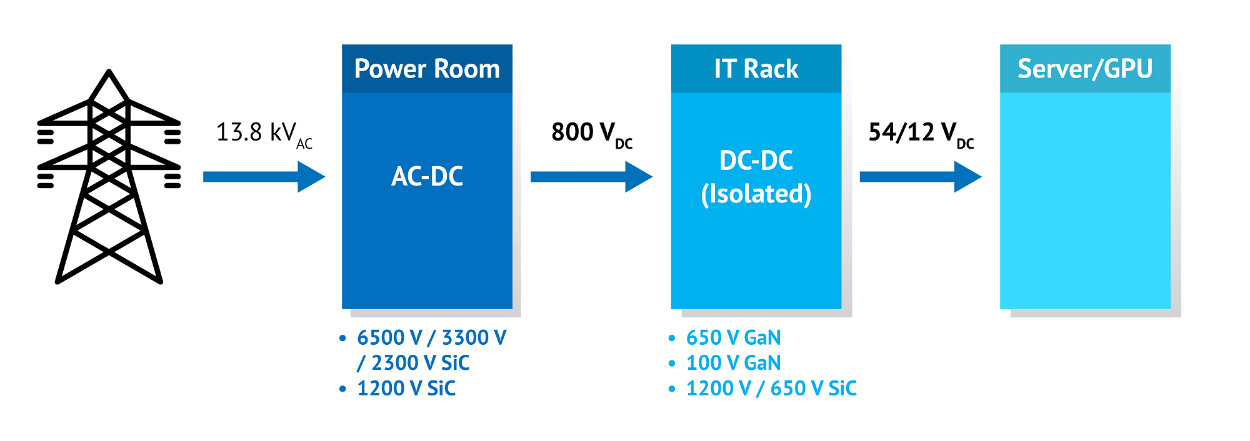
NVIDIA 采用纳微半导体开发新一代数据中心电源架构 800V HVDC 方案,赋能下一代AI兆瓦级算力需求



评论