 AI时代的存储墙,哪种存算方案才能打破?
AI时代的存储墙,哪种存算方案才能打破?
电子发烧友网报道(文/周凯扬)回顾计算行业几十年的历史,芯片算力提升在几年前,还在遵循摩尔定律。可随着如今摩尔定律显著放缓,算力发展已经陷入瓶颈。而且祸不单行,陷入同样困境的还有存储。从新标准推进的角度来看,存储市场依然在朝着更高性能的方向发展。但以这些通用标准推出的产品,终究还是会被用到冯诺依曼架构的计算体系中去。或许单个产品的性能有所增加,可面对AI计算的海量数据,这点提升还是有些不够看。
以LLM这个热门AI应用而言,其数据量已经在以2年750倍的速度爆发式增长,相较之下硬件算力正在以2年3倍的速度增长。但与存储不同,硬件算力是可以靠堆规模来实现持续提升的,可存储带宽和互联带宽却没法拥有同样的拓展性,只有存储容量能够勉强跟上。所以市场上多数都在追求某种形式的存算一体方案,但实现的形式和技术路线不尽相同。
近存方案,更大的SRAM和HBM
对于我们说的存储墙而言,其实在SRAM上并不那么明显,这种最接近处理单元的存储,常被用作高速缓存,不仅读写速度极快,能效比更是远超DRAM。但SRAM相对其他存储而言,存储密度最低,成本却不低。所以尽管现如今虽然更大的SRAM设计越来越普遍,但容量离DRAM还差得很远。
但这并不代表这样的设计没有人尝试,对于愿意花大成本的厂商而言,还是很高效的一条技术路线。以特斯拉为例,其Tesla Dojo超算系统的自研芯片D1就采用了超大SRAM的技术路线。Dojo在其网格设计中采用了超快且平均分布的SRAM。
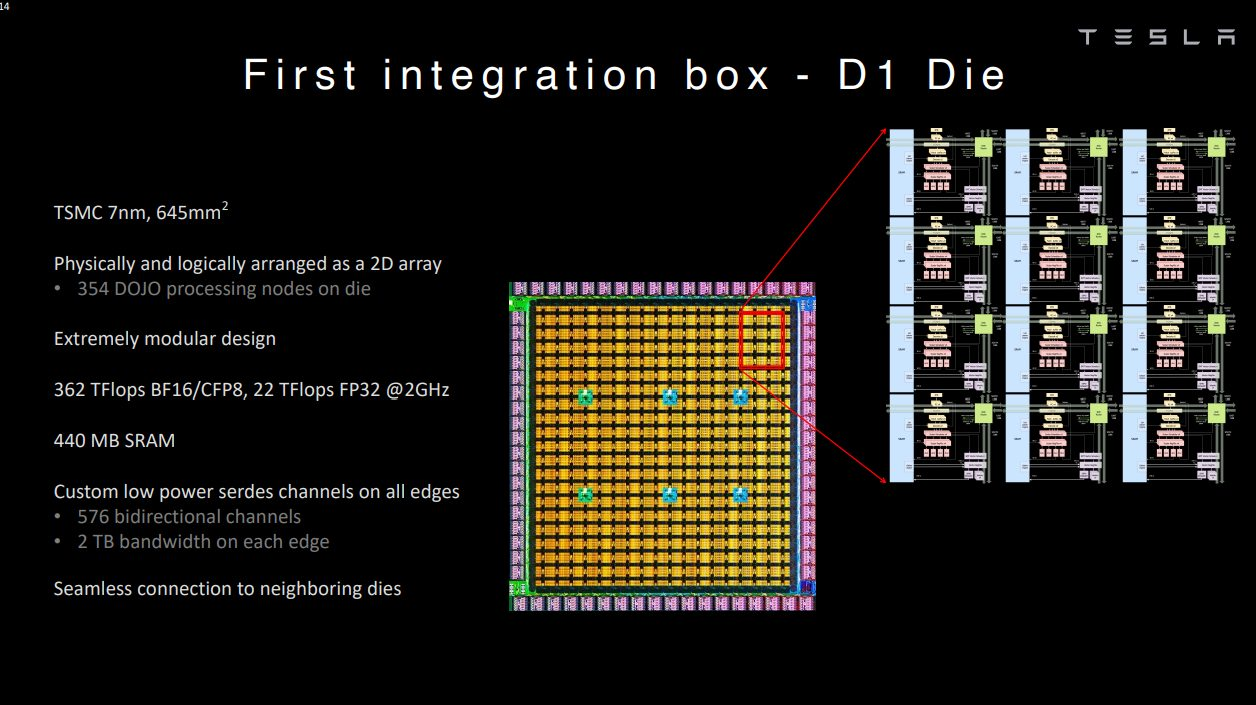
单个D1核心拥有1.25MB的SRAM,加载速度达到400GB/s,存储速度达到270GB/s。单个D1芯片的SRAM缓存达到440MB。简单来说,Dojo可以用远超L2缓存级别的SRAM容量,实现L1缓存级别的带宽和延迟。
当然了,这样的设计注定代表了投入大量的成本。在特斯拉2023财年Q4的财报会议上,马斯克强调他们做了英伟达和Dojo的两手准备。Dojo作为长远计划,因为最终的回报可能会值回现在的投入,但他也强调这确实不是什么高收益的项目。
所以对于已有的计算架构来说,走近存路线,提高DRAM的性能是最为适合的,比如HBM。HBM作为主流的近存高带宽方案,已经被广泛应用在新一代的AI芯片、GPU上。以HBM3e为例,1.2TB/s的超大带宽足以满足现如今绝大多数AI芯片的数据传输。未来的HBM4更是承诺1.5TB/s到2TB/s的带宽,
HBM的方案象征了目前DRAM堆叠的集大成技术,但目前还是存在不少问题,比如更高的成本以及对产能的要求。在现如今的AI需求驱动下,新发布的芯片很难再采用HBM设计的同时,保证大批量量产,无论是HBM产能还是CoWoS产能都处于满载的阶段,而且与制造厂商强绑定。可恰恰存储带宽决定了AI应用的速度,所以在HBM方案量产困难成本高昂的前提下,即便是英特尔和AMD这样的厂商也经不起这样挥霍,不少其他厂商更是选择了看下存内计算。
存内计算与处理,需要解决算力与存储双瓶颈
为了解决AI计算中数据存取的效率问题,把数据处理和筛选的工作放在存储端,就能极大地降低数据移动的能耗。以三星的PIM技术为例,其将关键的算法内核放在内存中的PCU模块中执行,相比已有的HBM方案,PIM-HBM可以将能耗降低70%以上。而且不仅是HBM,PIM也可以集成到LPDDR、GDDR等存储方案中。
不过存内处理的方案只解决了功耗和效率的问题,并没有对计算性能和存储性能带来任何大幅提升。至于将主要计算工作交给存内的计算单元,就是存内计算的目标了,比如不少厂商尝试的模拟存内计算(AIMC)。但这类方案实现大规模并行化运算的同时,还是需要昂贵的数模转换器,以及逃不开的错误检测。至于数字存内计算方案,一定程度上规避了模拟存内计算的缺陷,但还是牺牲了一些面积效率。对于一些大模型AI应用而言,单芯片的存储容量扩展性堪忧。
所以数模混合成了新的研究方向,比如中科院微电子研究所就在今年的ISSCC大会上发表了数模混合存算一体芯片的论文,其采用模拟方案来进行阵列内位乘法计算,利用数字方案来进行阵列外多位移位累加计算,从而达到整体的高能量效率和面积效率,INT8精度下的计算峰值能效可达111.17TFLOPS/W.

除此之外,还有存间计算的厂商,将计算单元放在不同的SRAM之间。以存间计算初创公司Untether AI为例,他们以打造存内推理加速器AI为主,通过将计算单元放在两个存储单元之间,其IC可以提供更高能效比的推理性能。比如他们在打造的第二代IC,speedAI240,集成了1400个定制RISC-V核心,可以提供至高2PetaFlops的推理性能,能耗比最高可达30 TFLOPS/W。
除了各种存算一体架构的算力瓶颈外,存储本身也需要做出突破。以三星的PIM为例,其虽然在DRAM上引入了PIM计算单元,但并未对DRAM本身的带宽的性能带来提升,这就造成了在存算一体的架构中,依然存在计算单元与存储器性能不平衡的问题,各种其他类型的存储器,包括MRAM、PCM、RRAM,除了量产问题外,写入速度和功耗的问题也还未实现突破。
西安紫光国芯为此提出了一种3D异质集成DRAM架构,逻辑晶圆通过3D混合键合工艺堆叠至SeDRAM晶圆上,进一步提升了访存带宽,降低了单位比特能耗,还能实现超大容量。从去年紫光国芯在VLSI 2023发布的论文来看,其SeDRAM已经发展至新一代多层阵列架构。结合低温混合键合技术和mini-TSV堆叠技术,可以实现135Gbps/Gbit的带宽和0.66pJ/bit的能效。
写在最后
其实无论是哪一种突破存储墙瓶颈的方式,最终都很难逃脱复杂工艺带来的挑战。行业迟迟不愿普及相关的存算技术,还是在制造工艺上没有达到适合普及的标准,无论是良率、成本还是所需的设计、制造流水线变化。已经占据主导地位的计算芯片厂商,也不会选择非得和存储绑在一条船上,但行业必然会朝这个方向发展。
此外,不少存内计算的堆叠方案中,还没有选择将主计算资源的CPU或GPU与存储垂直堆叠,而是把部分计算负载交给与存储结合的计算单元。这样一来既提高了AI计算的效率,又不会因为结构变化而出现不兼容的情况。从行业发展的角度来看,近存计算和存内处理最有可能先普及开来。
以LLM这个热门AI应用而言,其数据量已经在以2年750倍的速度爆发式增长,相较之下硬件算力正在以2年3倍的速度增长。但与存储不同,硬件算力是可以靠堆规模来实现持续提升的,可存储带宽和互联带宽却没法拥有同样的拓展性,只有存储容量能够勉强跟上。所以市场上多数都在追求某种形式的存算一体方案,但实现的形式和技术路线不尽相同。
近存方案,更大的SRAM和HBM
对于我们说的存储墙而言,其实在SRAM上并不那么明显,这种最接近处理单元的存储,常被用作高速缓存,不仅读写速度极快,能效比更是远超DRAM。但SRAM相对其他存储而言,存储密度最低,成本却不低。所以尽管现如今虽然更大的SRAM设计越来越普遍,但容量离DRAM还差得很远。
但这并不代表这样的设计没有人尝试,对于愿意花大成本的厂商而言,还是很高效的一条技术路线。以特斯拉为例,其Tesla Dojo超算系统的自研芯片D1就采用了超大SRAM的技术路线。Dojo在其网格设计中采用了超快且平均分布的SRAM。
D1芯片 / 特斯拉
单个D1核心拥有1.25MB的SRAM,加载速度达到400GB/s,存储速度达到270GB/s。单个D1芯片的SRAM缓存达到440MB。简单来说,Dojo可以用远超L2缓存级别的SRAM容量,实现L1缓存级别的带宽和延迟。
当然了,这样的设计注定代表了投入大量的成本。在特斯拉2023财年Q4的财报会议上,马斯克强调他们做了英伟达和Dojo的两手准备。Dojo作为长远计划,因为最终的回报可能会值回现在的投入,但他也强调这确实不是什么高收益的项目。
所以对于已有的计算架构来说,走近存路线,提高DRAM的性能是最为适合的,比如HBM。HBM作为主流的近存高带宽方案,已经被广泛应用在新一代的AI芯片、GPU上。以HBM3e为例,1.2TB/s的超大带宽足以满足现如今绝大多数AI芯片的数据传输。未来的HBM4更是承诺1.5TB/s到2TB/s的带宽,
HBM的方案象征了目前DRAM堆叠的集大成技术,但目前还是存在不少问题,比如更高的成本以及对产能的要求。在现如今的AI需求驱动下,新发布的芯片很难再采用HBM设计的同时,保证大批量量产,无论是HBM产能还是CoWoS产能都处于满载的阶段,而且与制造厂商强绑定。可恰恰存储带宽决定了AI应用的速度,所以在HBM方案量产困难成本高昂的前提下,即便是英特尔和AMD这样的厂商也经不起这样挥霍,不少其他厂商更是选择了看下存内计算。
存内计算与处理,需要解决算力与存储双瓶颈
为了解决AI计算中数据存取的效率问题,把数据处理和筛选的工作放在存储端,就能极大地降低数据移动的能耗。以三星的PIM技术为例,其将关键的算法内核放在内存中的PCU模块中执行,相比已有的HBM方案,PIM-HBM可以将能耗降低70%以上。而且不仅是HBM,PIM也可以集成到LPDDR、GDDR等存储方案中。
不过存内处理的方案只解决了功耗和效率的问题,并没有对计算性能和存储性能带来任何大幅提升。至于将主要计算工作交给存内的计算单元,就是存内计算的目标了,比如不少厂商尝试的模拟存内计算(AIMC)。但这类方案实现大规模并行化运算的同时,还是需要昂贵的数模转换器,以及逃不开的错误检测。至于数字存内计算方案,一定程度上规避了模拟存内计算的缺陷,但还是牺牲了一些面积效率。对于一些大模型AI应用而言,单芯片的存储容量扩展性堪忧。
所以数模混合成了新的研究方向,比如中科院微电子研究所就在今年的ISSCC大会上发表了数模混合存算一体芯片的论文,其采用模拟方案来进行阵列内位乘法计算,利用数字方案来进行阵列外多位移位累加计算,从而达到整体的高能量效率和面积效率,INT8精度下的计算峰值能效可达111.17TFLOPS/W.
speedAI240 / Untether AI
除此之外,还有存间计算的厂商,将计算单元放在不同的SRAM之间。以存间计算初创公司Untether AI为例,他们以打造存内推理加速器AI为主,通过将计算单元放在两个存储单元之间,其IC可以提供更高能效比的推理性能。比如他们在打造的第二代IC,speedAI240,集成了1400个定制RISC-V核心,可以提供至高2PetaFlops的推理性能,能耗比最高可达30 TFLOPS/W。
除了各种存算一体架构的算力瓶颈外,存储本身也需要做出突破。以三星的PIM为例,其虽然在DRAM上引入了PIM计算单元,但并未对DRAM本身的带宽的性能带来提升,这就造成了在存算一体的架构中,依然存在计算单元与存储器性能不平衡的问题,各种其他类型的存储器,包括MRAM、PCM、RRAM,除了量产问题外,写入速度和功耗的问题也还未实现突破。
西安紫光国芯为此提出了一种3D异质集成DRAM架构,逻辑晶圆通过3D混合键合工艺堆叠至SeDRAM晶圆上,进一步提升了访存带宽,降低了单位比特能耗,还能实现超大容量。从去年紫光国芯在VLSI 2023发布的论文来看,其SeDRAM已经发展至新一代多层阵列架构。结合低温混合键合技术和mini-TSV堆叠技术,可以实现135Gbps/Gbit的带宽和0.66pJ/bit的能效。
写在最后
其实无论是哪一种突破存储墙瓶颈的方式,最终都很难逃脱复杂工艺带来的挑战。行业迟迟不愿普及相关的存算技术,还是在制造工艺上没有达到适合普及的标准,无论是良率、成本还是所需的设计、制造流水线变化。已经占据主导地位的计算芯片厂商,也不会选择非得和存储绑在一条船上,但行业必然会朝这个方向发展。
此外,不少存内计算的堆叠方案中,还没有选择将主计算资源的CPU或GPU与存储垂直堆叠,而是把部分计算负载交给与存储结合的计算单元。这样一来既提高了AI计算的效率,又不会因为结构变化而出现不兼容的情况。从行业发展的角度来看,近存计算和存内处理最有可能先普及开来。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
存储
+关注
关注
13文章
4298浏览量
85804 -
sram
+关注
关注
6文章
767浏览量
114676 -
AI
+关注
关注
87文章
30747浏览量
268900 -
HBM
+关注
关注
0文章
379浏览量
14746 -
存算一体
+关注
关注
0文章
102浏览量
4297 -
存内计算
+关注
关注
0文章
30浏览量
1378
发布评论请先 登录
相关推荐

开源芯片系列讲座第24期:基于SRAM存算的高效计算架构
先进的计算架构技术,以克服传统冯诺依曼架构中计算单元与存储单元分离导致的“内存墙”问题。基于SRAM的存算一体技术在智能计算中具有高能效、高密度等优势,近年来在A

知存科技荣获2024中国AI算力层创新企业
中国科技产业智库「甲子光年」主办、中关村东升科学城协办的「AI创生时代2024甲子引力X科技产业新风向」大会在北京正式举行。作为压轴,「甲子光年」重磅发布了【星辰100】2024创新企业榜。知存
存算一体架构创新助力国产大算力AI芯片腾飞
在湾芯展SEMiBAY2024《AI芯片与高性能计算(HPC)应用论坛》上,亿铸科技高级副总裁徐芳发表了题为《存算一体架构创新助力国产大算力AI
存力与算力并重:数据时代的双刃剑
在2024年的今天,人工智能(AI)技术已经全面渗透至我们生活的方方面面,从医疗诊断到智能交通,从金融分析到智能家居,AI正以前所未有的速度重塑我们的世界。这一变革背后,算力和存力成为
大模型时代的算力需求
现在AI已进入大模型时代,各企业都争相部署大模型,但如何保证大模型的算力,以及相关的稳定性和性能,是一个极为重要的问题,带着这个极为重要的问题,我需要在此书中找到答案。
发表于 08-20 09:04
后摩智能推出边端大模型AI芯片M30,展现出存算一体架构优势
了基于M30芯片的智算模组(SoM)和力谋®️AI加速卡。 后摩智能存算一体架构芯片产品 后摩智能是一家专注于存
2024多样性算力产业峰会:江波龙解码AI存储方案的未来之路
6月18日,多样性算力产业峰会2024在北京圆满举行,江波龙企业级存储事业部市场总监曹浔峰受邀出席本次峰会并发表了《大模型时代AI存储

知存科技助力AI应用落地:WTMDK2101-ZT1评估板实地评测与性能揭秘
一体领域的研发领导者
存算一体技术作为解决冯诺依曼架构下存储墙问题的重要方案,吸引了国内外众多企业的研发投入,其中知
发表于 05-16 16:38
存内计算WTM2101编译工具链 资料
出来再进行计算,读取时间与参数规模成正比,计算芯片的功耗和性能受限,GPU算力利用率甚至不到8%。
存内计算芯片实现了存储单元与计算单元的物理融合,没有独立的计算单元,直接通过在存储器
发表于 05-16 16:33


大算力时代, 如何打破内存墙
设计的不断革新,进入了大算力时代。 目前,主流AI芯片的架构仍然沿用了传统的冯·诺依曼模型,这一设计将计算单元与数据存储分离。在这种架构下,处理器需要从内存中读取数据,执行计算任务,然





 工商网监
工商网监
评论