 如何处理SoC中的性能瓶颈呢?
如何处理SoC中的性能瓶颈呢?

SoC 中不断添加处理核心,但它们不会都得到充分利用,因为真正的瓶颈没有得到解决。
SoC 需要处理的数据量激增,虽然处理核心本身可以处理这些数据,但内存和通信带宽成为瓶颈。现在的问题是可以采取什么措施解决这个问题。
内存和 CPU 带宽之间的差距(即所谓的内存墙)不是一个新问题,还在继续恶化。
早在 2016 年,德克萨斯州高级计算中心的研究科学家 John McCalpin 就发表了一次演讲,研究了高性能计算 (HPC) 的内存带宽和系统资源之间的平衡。他分析了当时排名前 500 的机器,并剖析了它们的核心性能、内存带宽、内存延迟、互连带宽和互连延迟。他的分析表明,每个插槽的峰值 FLOPS 每年增加 50% 到 60%,而内存带宽每年仅增加约 23%。此外,内存延迟每年减少约 4%,互连带宽和延迟每年增加约 20%。这些表明数据移动方面存在持续且不断扩大的不平衡。
这意味着,如果我们传输数据,则每次内存传输所花费的时间相当于 100 次浮点算术运算。也就是说,如果无法预取并且错过了cache,你就失去了执行超过 4,000 次浮点运算的机会。
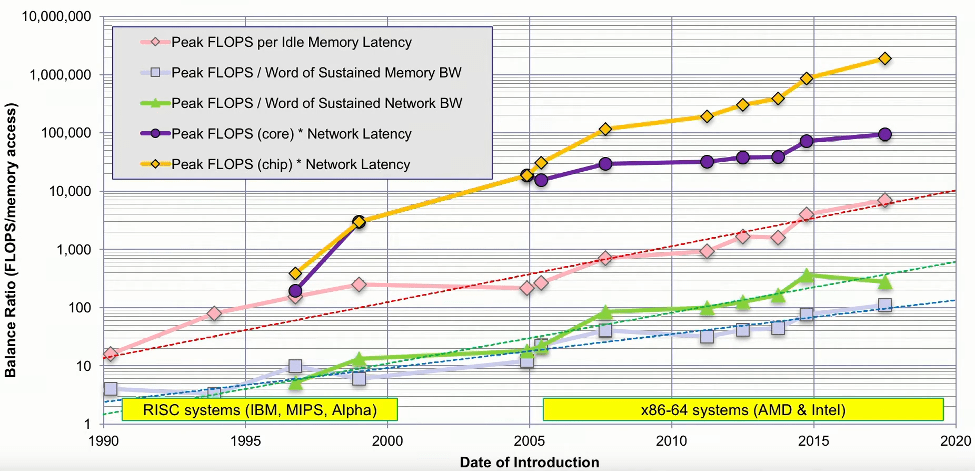
系统性能要素的不平衡。
一个设计良好的系统是平衡的。大多数人想要的是更有效地使用晶体管,目标每美元的吞吐量和每瓦特的吞吐量将会更高,总之利用率越高越好。
在考虑系统性能时,要么受计算限制,要么受内存限制,要么受 I/O 限制。随着计算速度的加快,需要更加重视内存是否能够跟上计算速度,并且还需要更高的带宽接口来将传输数据。
但业界对处理性能非常着迷。实际上,计算单元很重要,但它们通常不是实际系统速度的限制因素。系统速度和工作负载强相关,它取决于数据从某个地方来、以某种方式处理并发送到数据被需要的地方有多快,并受到沿途乱七八糟事情的干扰。
这意味着不可能构建一个适合所有任务的最佳系统。关键是要确保其均衡性良好,并且在任何区域都不会过度配置。
移动数据
移动数据肯定会影响系统性能,也与功耗有关,因为移动一段数据比对其执行计算消耗的功耗高几个数量级。完成一项任务,一般意味着将数据通过外部接口移入内存,从内存到CPU,中间结果在内存和CPU之间来回切换,最后结果通过外部接口推回。
无论你的计算速度有多快,或者你的内存阵列有多大,最终决定芯片和系统性能的是连接两者的总线带宽。这就是最大的瓶颈所在,不仅仅是总线,还有高速接口,它们都为解决数据访问瓶颈做出了自己的努力。
有效的内存带宽的提升是cache的采用。假设大多数内存访问来自cache而不是主存,这有效地使数据更接近处理器,并减少延迟。处理器性能的提高如此之快,主要是通过核心数量的快速增加。然而,cache性能一直在下降,这是导致延迟增加的主要原因之一。即使 HBM 的引入也未能扭转这一趋势。cache性能的降低是因为cache设计变得越来越复杂,特别是随着更多核心保持cache coherent,并且多级cache串行lookup以节省功耗。
另一种选择是将计算移至更靠近内存的位置。in-memory computing的时代才刚刚开始,这可以通过三种方式实现。
1、通常,由于 DRAM 制造的经济性,我们不会在 DRAM 芯片上看到很多复杂的逻辑。我们可能会看到少量非常具体的函数被添加到这些芯片中,例如累加或乘累加函数,这在许多 DSP 和 AI 算法中很常见。
2、第二种可能是像 CXL.mem 这样的技术,在这种技术中,将计算功能添加到控制内存阵列的逻辑芯片中是非常可行的。从技术上讲,这是在内存附近处理而不是在内存中处理。
3、第三个介于两者之间。对于某些堆叠式存储器(例如 HBM),通常有一个逻辑芯片与 DRAM 共同封装在同一堆叠中,并且该逻辑芯片是面向 CPU 和 DRAM 设备的总线之间的接口。该逻辑芯片为逻辑芯片上的中低复杂度处理元件提供了空间。
HBM 的成功无疑帮助普及了chiplets的概念,曾经受到光罩限制或产量限制的芯片现在可以在多个chiplets上制造并集成到一个封装中。然而,现在需要的芯片间连接解决方案可能比单个芯片上的连接解决方案慢。当公司将芯片分割成多个同质芯片时,希望在分割芯片上执行相同的操作,又不会降低性能或准确性。
实际上,这些chiplets是在系统环境中设计的,不仅仅是之前那样的存储器或控制器设计。封装中的 IC 会引入其自身的寄生效应,因此你需要将其视为一个系统,并查看眼图,看看如何根据系统的运行条件,信号的来源和接收方,对其进行优化,从而大幅增加带宽并减少延迟。这些目的决定了接口和协议。USB、SATA、PCIe、CXL、DDR、HMC、AXUI、MIPI,这些不胜枚举的协议都需要接口,业内正在创建更新的协议,并且需要新的接收器来实现这些芯片到芯片的连接。
multi-die系统的一大优势是可用连接的数量变得更多。从 I/O 的角度来看,我们曾经拥有 1,024 位总线,然后我们转向串行接口。但最近发生的情况是,那些串行接口现在已经变成并行接口,例如 x32 PCIe,它由 32 通道超高速串行连接组成。
工作负载
如前所述,系统性能和工作负载强相关。不可能制造针对所有情况优化的通用机器。找到PPA平衡迫使人们重新思考和定制芯片。
像人工智能这样的任务也存在着不同的工作负载。如果你观察人工智能,就会发现它有两个方面。一个是训练,在训练中你需要不断地访问内存,因为权重就在那里。而且你会不断改变权重,此时内存访问是关键。然而,如果你看推理,模型已经训练好了,你所要做的就是 MAC 操作,没有访问内存去改变权重。
寻找适当的平衡需要采用协同设计方法。在架构阶段,需要评估芯片的各种场景,关注芯片内以及芯片外的吞吐量和带宽。另一方面,物理设计团队必须找出芯片的最佳尺寸。由于产量和功率的原因,它不能太大,更不能太小。然后设计团队必须为他们构建接口和协议。架构团队、物理设计团队和设计团队不断地进行三方战斗,以找到让每个人都满意的最佳点。当然,少不了验证这个守门员。
计算范式
对于某些问题,使用传统软件可能会导致解决方案效率低下。这发生在从单核到多核的过渡以及 GPGPU 的采用期间。业界正在等待新一代人工智能硬件的实现。GPU 可以进行大规模并行计算,除了渲染形状之外还可以做各种事情。
结论
添加更多或更快的处理核心固然很棒,但除非你能让它们保持忙碌,否则就是在浪费时间、金钱和电力。
随着 DRAM 迁移到封装中,预计潜在带宽将持续增加,但 DRAM 性能在过去 20 年里始终没有跟上处理器,那么业界将不得不通过自身架构来解决这个问题。
-
处理器
+关注
关注
68文章
20371浏览量
255554 -
DRAM
+关注
关注
41文章
2406浏览量
189720 -
SoC芯片
+关注
关注
2文章
678浏览量
37314 -
Cache
+关注
关注
0文章
130浏览量
29822 -
HPC
+关注
关注
0文章
351浏览量
25094
原文标题:处理 SoC 中的性能瓶颈
文章出处:【微信号:数字芯片实验室,微信公众号:数字芯片实验室】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
DLPC3433的PCLK和PDATA【0~23】该如何处理呢?
NANO芯片系统中,其对应的AVDD,VREF等引脚该如何处理呢?
SoC中的处理单元性能分析

如何处理电子污染
在国外人们都是如何处理电子垃圾的呢_电子垃圾回收产业现状及其意义
处理DS2155中的性能报告消息

如何处理HTTP 503故障问题?
ttl与非门中不用的输入端如何处理?
广播系统出现噪音、啸叫如何处理?




评论