 MySQL联表查询优化
MySQL联表查询优化
sql执行顺序
执行FROM语句
执行ON过滤
join添加外部行
执行where条件过滤
执行group by以及分组语句,(开始使用select中的别名,后面的语句中都可以使用别名)
执行having
select列表
执行distinct去重复数据
执行order by字句
执行limit字句
多表联合查询优化建议
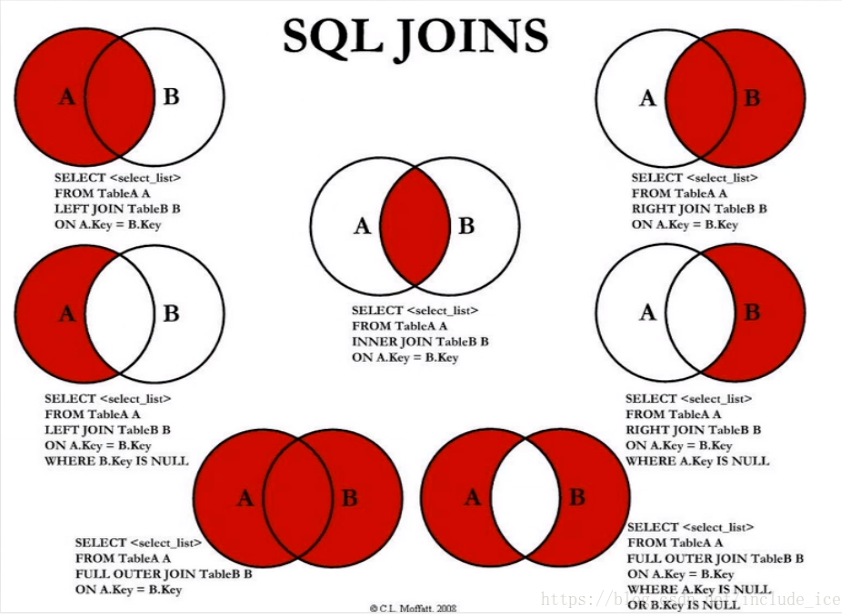
1、使用显示连接left join(right join,inner join),尽量避免隐式连接(where逗号连接表 .... and .... and ...)这类写法,假设三张表每张表有一千条数据,本意想查出<=1000条数据,当使用where语句查询,就查出了1000*1000*1000=10亿条数据,很大程度上浪费了内存执行时间
ps:在不使用on语法时,join、inner join、逗号、cross join结果相同,都是取2个表的笛卡尔积。逗号与其他操作符优先级不同,所以有可能产生语法错误,尽量减少用逗号
2、需要哪些列就查哪些列,不要有很多冗余的列查询出来,有的时候一张表当中有好几十个字段,我们需要的可能就是其中的三四个或者四五个字段,在这样的情况下,我们就直接查这几个我们需要的字段就可以了
3、尽量避免使用 .* ,因为使用点* 需要先去数据字典当中查找你所查找的表当中所拥有的字段,再转换成对应的字段的放在select后面查询出来
4、优先使用大于等于,比大于执行效率高
5、查询的时候我们应该把更具有限制条件的条件语句放在最前面,比如我们有一张学生成绩表(score),分别有学号、语数英三科成绩以及总成绩总共五列,要查找数学、英语优秀,语文及格,总成绩再前一百名的人
select * from score where sno in(select sno from score where language>60 and math>80 and english>80 order by total_score desc)(慢) select sno,language,math,english,total_score from score where exist (select sno from where engilsh>=80 and math>=80 and language>=80 order by total_score desc)(快)
上面那条语句将大于60分的条件放前面,大于80的放后面,导致很多情况下多查了很多数据
就比如说一张表里有有很多字段,有一百万条记录,主键id由1到1百万,当我们需要查找小于1000大于100的数据的时候,我们就应该把小于1000这个条件放前面,这就是相对比下最具限制性的条件
6、尽量使用连接查询 替代 子查询,因为子查询需要建立/销毁临时表,开销昂贵
select a.id,a.name from a where a.id in(select b.aid from b where b.id=123); select a.id,a.name from a inner join b on a.id=b.aid wehre b.id=123;
子查询执行表现为,外表遍历每一条,内表都需要扫描一次,边遍历查询外表,边扫描内表;
如果数量较大,则使用连接查询,因为子查询会扫描多次;
如果数据量较小,则子查询与连接查询对比不明显
如果需要用到子查询:
6.1、用EXISTS(或内连接)替代IN、用NOT EXISTS(或者外连接)替代NOT IN
6.2、用EXISTS替换DISTINCT
7、where条件尽量使用索引,避免在索引列使用计算(加减乘除),避免索引列使用函数(转换类型),避免索引列使用is(not)null,避免索引列使用通配符,否则数据库将放弃索引,执行全表扫描
8、where代替having,优化group by
提高GROUP BY 语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉,如下
低效: SELECT JOB , AVG(SAL) FROM EMP GROUP BY JOB HAVING JOB = ‘PRESIDENT' OR JOB = ‘MANAGER'
高效: SELECT JOB , AVG(SAL) FROM EMP WHERE JOB = ‘PRESIDENT' OR JOB = ‘MANAGER' GROUP BY JOB
9、Order By语句加在索引列,最好是主键PK上
10、用EXISTS替换DISTINCT
当提交一个包含一对多表信息(比如部门表和雇员表)的查询时,避免在SELECT子句中使用DISTINCT. 一般可以考虑用EXIST替换, EXISTS 使查询更为迅速,因为RDBMS核心模块将在子查询的条件一旦满足后,立刻返回结果
11、in是把外表和内表作hash连接,而exists是对外表作loop循环,每次loop循环再对内表进行查询,一直以来认为exists比in效率高的说法是不准确的。如果查询的两个表大小相当,那么用in和exists差别不大;如果两个表中一个较小一个较大,则子查询表大的用exists,子查询表小的用in(减少遍历次数)
12、字符串型=,in,like’abc%‘索引生效;!=, not in, like'%abc', like'a%bc'索引失效
13、数值型=, !=, in, not in都可以索引生效
索引一般性建议
对于单键索引,尽量选择针对当前query过滤性更好的索引
在选择组合索引的时候,当前Query中过滤性最好的字段在索引字段顺序中,位置越靠前越好
在选择组合索引的时候,尽量选择可以能够包含当前query中的where子句中更多字段的索引
尽可能通过分析统计信息和调整query的写法来达到选择合适索引的目的
索引口诀
全职匹配我最爱,最左前缀要遵守
带头大哥不能死,中间兄弟不能断
索引列上少计算,范围之后全失效
like百分写最右,覆盖索引不写星
不等空值还有or,索引失效要少用
var引号不可丢,SQL高级也不难
审核编辑:黄飞
-
SQL
+关注
关注
1文章
776浏览量
44373 -
MySQL
+关注
关注
1文章
835浏览量
26876
原文标题:MySQL联表查询优化
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
MySQL表分区类型及介绍
Mysql优化选择最佳索引规则
详解MySQL的查询优化 MySQL逻辑架构分析
MySQL 基本知识点梳理和查询优化
MySQL数据库:理解MySQL的性能优化、优化查询

为什么ElasticSearch复杂条件查询比MySQL好?

查询SQL在mysql内部是如何执行?





 工商网监
工商网监
评论