 TinyML计算机视觉正在通过microNPU(µ NPU)变为现实
TinyML计算机视觉正在通过microNPU(µ NPU)变为现实
今天的计算机视觉(CV)技术正处于一个转折点,主要趋势正在融合,使云技术在微小的边缘AI设备中变得无处不在。技术进步使这种以云为中心的人工智能技术能够扩展到边缘,新的发展将使边缘的人工智能视觉无处不在。
有三个主要的技术趋势使这种演变。新的精益神经网络算法适合微型设备的内存空间和计算能力。新的硅架构为神经网络处理提供了比传统微控制器(MCU)高几个数量级的效率。用于较小微处理器的AI框架正在成熟,减少了在边缘开发微型机器学习(ML)实现(tinyML)的障碍。
当所有这些元素结合在一起时,毫瓦级的微型处理器可以拥有强大的神经处理单元,这些单元可以执行非常高效的卷积神经网络(CNN)-视觉处理中最常见的ML架构-利用成熟且易于使用的开发工具链。这将在我们生活的各个方面实现令人兴奋的新用例。
边缘CV的承诺
数字图像处理(过去的叫法)用于从半导体制造和检测到高级驾驶员辅助系统(ADAS)功能(如车道偏离警告和盲点检测),再到移动的设备上的图像美化和操作等各种应用。展望未来,边缘CV技术正在实现更高级别的人机界面(HMI)。
HMI在过去十年中发生了重大变化。除了键盘和鼠标等传统界面之外,我们现在还拥有触摸显示屏、指纹识别器、面部识别系统和语音命令功能。在明显改善用户体验的同时,这些方法还有一个共同点它们都对用户操作做出反应。HMI的下一个层次将是通过上下文感知来理解用户及其环境的设备。
情境感知设备不仅能感知用户,还能感知它们所处的环境,所有这些都是为了做出更好的决策,实现更有用的自动化交互。例如,笔记本电脑可以在视觉上感知用户何时注意,并相应地调整其行为和电源策略。Synaptics的Emza Visual Sense技术已经实现了这一点,OEM可以使用该技术在用户不观看显示器时自适应调暗显示器以优化功耗,从而降低显示器的能耗。通过跟踪旁观者的眼球(旁观者检测),该技术还可以通过提醒用户并隐藏屏幕内容来增强安全性,直到海岸清晰。
另一个例子:智能电视机感知是否有人在观看以及从哪里观看,然后相应地调整图像质量和声音。它可以自动关闭,以保存电力时,没有人在那里。或者,空调系统根据房间占用情况优化电力和气流,以保存能源成本。这些和其他建筑物中智能能源利用的例子在家庭-办公室混合工作模式下变得更加重要。
在工业领域中,视觉感测也有无穷无尽的用例,从用于安全监管的物体检测(即,限制区、安全通道、防护装备执行)直到用于制造过程控制的异常检测。在农业技术中,作物检查以及CV技术实现的状态和质量监控都至关重要。
无论是在笔记本电脑、消费电子产品、智能建筑传感器还是工业环境中,当微型和负担得起的微处理器、微型神经网络和优化的人工智能框架使设备更加智能和节能时,这种环境计算能力就可以实现。nbsp;
神经网络视觉处理的发展
2012年是CV开始从启发式CV方法转向深度卷积神经网络(DCNN)的转折点,Alex Krizhevsky和他的同事发表了AlexNet。DCNN在那年赢得ImageNet大规模视觉识别挑战赛(ILSVRC)后就再也没有回头路了。
从那时起,地球仪的团队一直在寻求更高的检测性能,但对底层硬件的效率没有太多的关注。所以CNN仍然是数据和计算饥渴的。这种对性能的关注对于在云基础设施中运行的应用程序来说是很好的。
2015年,ResNet152被引入。它有6000万个参数,单次推理操作需要超过11gigaflops,并且在ImageNet数据集上表现出94%的前5名准确率。这继续推动CNN的性能和准确性。但直到2017年,随着谷歌的一组研究人员发表了MobileNets,我们才看到了效率的提升。
MobileNets-针对智能手机-比当时现有的神经网络(NN)架构轻得多。例如,MobileNetV 2有350万个参数,需要336 Mflops。这种大幅减少最初是通过艰苦的劳动实现的-手动识别深度学习网络中的层,这并没有增加太多的准确性。后来,自动化的架构搜索工具允许进一步改进层的数量和组织。在内存和计算负载方面,MobileNetV 2比ResNet 192大约“轻”20倍,表现出90%的前5名准确率。一组新的移动友好应用程序现在可以使用AI。
硬件也在不断发展
通过更小的NN和对所涉及的工作负载的清晰理解,开发人员现在可以为微型AI设计优化的硅。这导致了微神经处理单元(微NPU)。通过严格管理内存组织和数据流,同时利用大规模并行性,这些小型专用核心可以比典型MCU中的独立CPU快10倍或100倍地执行NN推理。一个例子是Arm Ethos U55微型NPU。
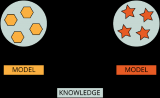
让我们来看看microNPU(µ NPU)影响的一个具体示例。CV的基本任务之一是对象检测。物体检测本质上需要两个任务:定位,确定物体在图像中的位置,以及分类,识别检测到的物体(图2)。
Emza在Ethos U55 µNPU上实现了一个人脸检测模型,训练了一个对象检测和分类模型,该模型是单镜头检测器的轻量级版本,由Synaptics优化,仅用于检测人脸类别。结果令我们惊讶,模型执行时间不到5毫秒:这与强大的智能手机应用处理器(如Snapdragon 845)的执行速度相当。当在使用四个Cortex A53内核的Raspberry Pi 3B上执行相同的模型时,执行时间要长六倍。
AI框架和民主化
广泛采用任何像ML这样复杂的技术都需要良好的开发工具。TensorFlow Lite for Microcontrollers(TFLM)是一个框架,旨在更轻松地为tinyML训练和部署AI。对于完整TensorFlow所涵盖的运算符子集,TFLM会发出微处理器C代码,用于在µNPU上运行解释器和模型。来自Meta的PyTorch移动的框架和Glow编译器也针对这一领域。此外,现在有很多AI自动化平台(称为AutoML)可以自动化针对微小目标的AI部署的某些方面。例如Edge Impulse、Deeplite、Qeexo和SensiML。
但要在特定硬件和µ NPU上执行,必须修改编译器和工具链。Arm开发了Vela编译器,可以优化U55 µ NPU的CNN模型执行。Vela编译器通过自动在CPU和µ NPU之间分割模型执行任务,消除了包含CPU和µ NPU的系统的复杂性。
更广泛地说,Apache TVM是一个开源的,端到端的ML编译器框架,用于CPU,GPU,NPU和加速器。TVM micro的目标是微控制器,其愿景是在任何硬件上运行任何AI模型。AI框架、AutoML平台和编译器的这种演变使开发人员更容易利用新的µ NPU来满足他们的特定需求。
无处不在的边缘AI
在边缘无处不在的基于ML的视觉处理的趋势是明确的。硬件成本正在下降,计算能力正在显著提高,新的方法使训练和部署模型变得更加容易。所有这些都减少了采用的障碍,并增加了CV AI在边缘的使用。
但是,即使我们看到越来越普遍的微小边缘AI,仍然有工作要做。为了使环境计算成为现实,我们需要服务于许多细分领域的长尾用例,这些用例可能会带来可扩展性挑战。在消费品、工厂、农业、零售和其他领域,每个新任务都需要不同的算法和独特的数据集进行训练。解决每个用例所需的研发投资和技能组合仍然是当今的主要障碍。
这一差距最好由人工智能公司通过开发丰富的模型示例集("模型动物园")和应用程序参考代码来围绕其NPU产品升级软件来填补。通过这样做,他们可以为长尾提供更广泛的应用,同时通过针对目标硬件优化正确的算法来确保设计成功,以在定义的成本、大小和功耗限制范围内解决特定的业务需求。
审核编辑 黄宇
-
人工智能
+关注
关注
1792文章
47409浏览量
238924 -
计算机视觉
+关注
关注
8文章
1698浏览量
46030 -
NPU
+关注
关注
2文章
286浏览量
18655 -
边缘AI
+关注
关注
0文章
96浏览量
5031 -
TinyML
+关注
关注
0文章
42浏览量
1250
发布评论请先 登录
相关推荐







 工商网监
工商网监
评论