 AI是把双刃剑,HPC面临的全新机遇与挑战
AI是把双刃剑,HPC面临的全新机遇与挑战
电子发烧友网报道(文/周凯扬)高性能计算也就是HPC(High Performance Computing),是一种利用超级计算机或高性能计算机集群的能力实现并行计算,以处理标准工作站无法完成的数据密集型计算任务的技术。现如今的HPC随着芯片设计和AI技术的发展,也在迈向全新的道路,带动整个HPC市场稳步增长。
HPC市场趋势——需求与政策带动市场稳步增长
据统计全球高性能计算市场规模在 2023 年达到569.8 亿美元,预计到 2028 年将达到 967.9 亿美元,在预测期间以 11.18% 的复合年增长率增长。过去几年由于疫情、灾难气候等事件,推动了HPC的新需求。随着HPC在云端部署和需求的增加,人工智能、数据分析上也面临着快速处理数据、高精度日益增长的需求,包括生命科学、汽车、金融和航天航空等行业。
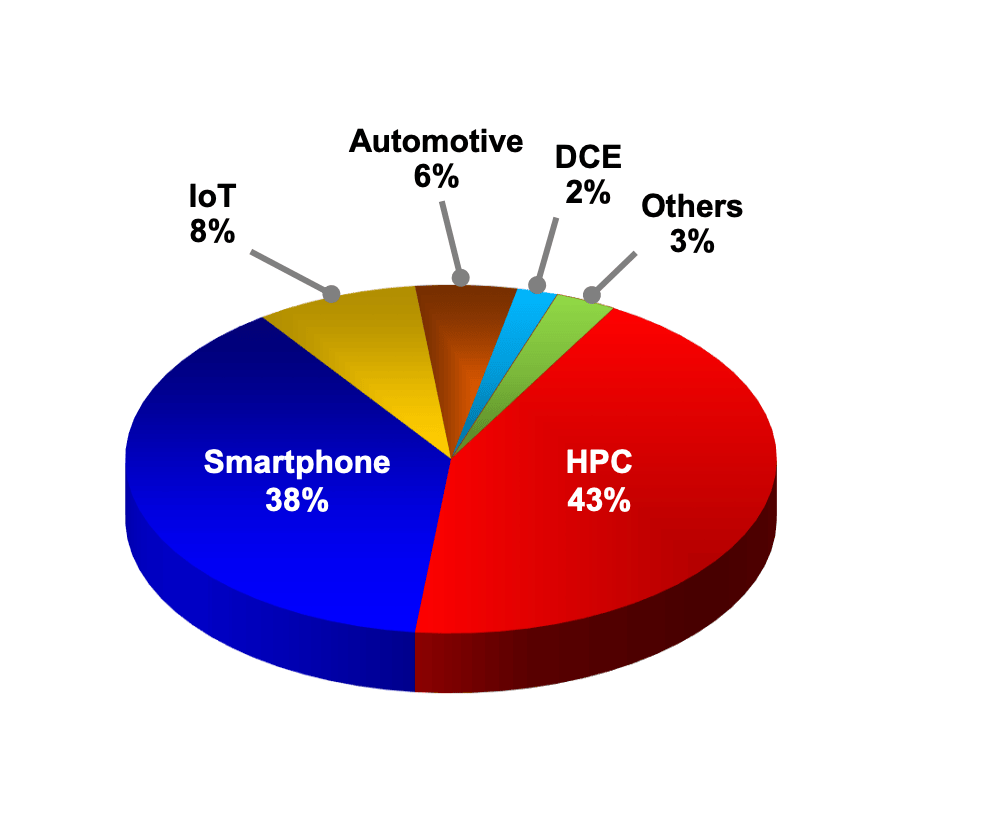
2023年不同平台营收占比 / 台积电
从上游晶圆厂的角度来看,HPC贡献的营收已经稳定超过智能手机业务。以台积电为例,其去年的HPC营收占比达到43%,已经是连续两年超过智能手机业务营收了。台积电CEO魏哲家预估,今年半导体产业产值将可望成长10%以上,晶圆代工产业将年成长20%,预期台积电2024年在人工智能(AI)和HPC需求带动下,全年营收有望实现20%以上的增长。
除了市场需求外,政策激励也在促进HPC的市场发展。比如国内发布的《十四五规划》中就提到,加快建设新型基础设施,建设 E 级和 10E 级超级计算中心,并在合肥、兰州、厦门、太原等地都将陆续建立高性能计算中心。
美国也发布了《保持美国高性能计算在E(百亿亿次级计算)时代的领先地位》这一指导文章,其中提到要落实芯片与科学法案中与HPC相关的投资与项目,增加能源部、区域创新中心超算项目的资助。
HPC不同应用的性能要求——不只是算力,I/O与时延同样重要
HPC提供了超高浮点计算能力解决方案,可用于各种海量数据处理等业务的计算需求,比如各种传统科学运算,常见的应用领域有基础科研、气象研究、制造仿真、材料计算、生命科学、地球物理等等。
除此之外,还有各种商业领域也得到了广泛应用,比如动画渲染、生物制药和基因测序等等。相较于其他通用计算系统而言,HPC系统往往需要对单一应用做出特殊的优化,无论是硬件还是软件。所以缺乏HPC系统弹性部署的同时,却也代表着极致的性能。不同的应用往往会对HPC系统的性能提出截然不同的要求。
比如在动画渲染中,关键参数为浮点算力、I/O性能,这是因为1.资产重、难度大的3D渲染,对缓存层的吞吐和I/O压力极大。2.需要快速交付海量算力,缩短制作周期,比如《长津湖之水门桥》《流浪地球2》《三体》等作品,都用到了贵安超算中心的庞大算力。
在气象研究中,关键参数为浮点算力、网络时延。因为1.气象观测时空分辨率增加,气象行业数据量大幅增长,处理能力有待提升。2.短临预报精度较低,需要更低的时延。在工程仿真中,网络时延、内存带宽至关重要。因为操作过程中,1.三维交互较多,对时延要求高2.要求高并发存取,更高的内存带宽可以显著提高效率。
HPC上游产业链——x86依然占据主导,Arm崛起
在HPC市场中,上游产业链主要是HPC系统的计算处理资源,包括CPU、GPU、DPU和其他加速器。中游则涵盖了服务器产品,以及对应的附属资源,包括存储、网络设备、电源、冷却设备等。下游则是把HPC系统投入应用的部署厂商,包括云服务厂商、超算中心和科研机构等等。
在上游产业链中,HPC系统最重要的莫过于CPU和GPU这两大硬件。CPU厂商包括英特尔、AMD、英伟达、IBM、申威和龙芯中科等。GPU则包括英伟达、AMD、英特尔等厂商。DPU则包括英伟达、AMD、英特尔、亚马逊、阿里巴巴、云豹智能、星云智联。除此之外,HPC系统偶尔也会集成别的加速器设备,比如谷歌NPU,Cerebras的晶圆级AI处理器、景嘉微的景宏系列智算模块等。
从占比的角度来看,x86 CPU在HPC系统中依然占据绝对的主导地位,具体产品以英特尔的Xeon系列CPU和AMD的EPYC系列CPU为主。除了本身的性能足够强外,也少不了这么多年以来x86在HPC软件生态上的积累。
不过随着Arm架构在设计上的不断创新,相关的产品也在层出不穷,比如基于Neoverse核心设计的英伟达Grace CPU、阿里倚天710、华为鲲鹏920,又或是依靠自研核心打造的富士通A64FX CPU、飞腾腾云S5000C等。而且随着Arm打通了开发高性能计算生态,相关的计算库和软件也已经跟进了。
除了以上两个架构外,还有其他架构的CPU也在超算领域崭露头角,比如RISC-V架构以及其他自研RISC架构,但除了IBM的Power架构外,相关的硬件与软件生态都还不完善。

B200 GPU / 英伟达
在HPC系统所用到的加速器中,GPU占据了绝对的主导地位,其中市场份额最高的当数英伟达的高性能GPU产品。在时下性能排名靠前的HPC系统中,集成了英伟达发布跨度数年的产品,从Tesla 100到H100,英伟达的CUDA生态也已经在HPC软件中得到应用。除此之外,英伟达也打造了自己的超算Earth-2,用于天气预测。
其次是AMD的Instinct系列产品,充分利用了AMD的CDNA架构,为HPC系统提供强大的通用GPU计算性能。目前全球排名第一的超算系统Frontier,用到的就是AMD的MI250X GPU。
最后是英特尔数据中心GPU Max系列,使用该系列GPU的HPC系统不多,主要是搭配英特尔的Xeon处理器作为打包方案提供给客户。
需要注意的是,之所以目前用于HPC的GPU系统几乎只有这三家,是因为其提供了主流HPC应用所需的FP64精度支持。而近几年发布的GPU,由于专注于AI计算和消费级应用上,大部分最高只支持到FP32。
HPC中游产业链——AI同时拔高了HPC系统的存储与供电要求
在HPC服务器厂商中,市场份额占比最高的为HPE和戴尔两家厂商,除此之外联想、浪潮、中科曙光、IBM、Atos、富士通和NEC等,也推出了对应的产品解决方案。在HPC存储器方案上,由于HPC系统的特殊文件系统,往往还是由服务器厂商提供解决方案,包括戴尔、IBM、HPE、联想、DDN和希捷等。最后则是电源等附属设备,HPC系统电源以台湾供应商居多,包括台达电子、光宝科技、康舒、群电、肯微等等。
AI和HPC相融合,对于HPC的存储提出了新的要求,比如在接口上,虽然POSIX还是主流解决方案。但由于英伟达GPU在AI HPC系统中的广泛使用,也出现支持GDS(GPU直接存储)接口的存储方案。除此之外,AI HPC往往有着处理海量小文件的需求,对存储系统的扩展性要求较高。而且为了留存计算得到的临时结果,需要一定的临时存储空间需求。
就HPC系统的发展来看,目前的趋势是处理器的功耗每两年翻一番。2000A 的峰值电流现在已经很普遍。但随着HPC系统功耗继续升高,我们面临的是更高的PUE要求。比如我国就要求新建成的服务器PUE要小于1.3。这不仅对电源效率提出了新的挑战,也对散热方案提出了更高的要求,未来液冷方案可能会成为HPC系统的主流散热方案。
此外,AI HPC集群的供电要求更高。AI HPC系统的电源已经达到了3kW到4kW的区间,随着氮化镓和碳化硅技术在服务器电源领域的普及,未来可以支持到10kW级别的服务器电源。
超算市场的变与不变
超级计算机作为高性能计算的子集应用,代表了市面上最强大的计算系统。它们在进行特定的通用科学运算方面表现突出,但在处理一般计算工作时性能并不突出。据mordorintelligence预测,超级计算机市场规模预计到 2024 年将达到 121.0 亿美元,预计到 2029 年将达到 121.5 亿美元, 年复合增长率只有0.09%。虽然看起来市场增长不多,但政府和企业都在持续投入超算的部署。
超级计算机对一个国家的科学进步和国家安全作出了重大贡献,能源中心、超级计算中心均使用超算来处理工作负载。不仅如此,超算也用来打造国家超算互联网,接入第三方应用、数据、模型服务商,提供科学计算、工业仿真、人工智能模型训练的商用,缓解算力供需矛盾。
在企业投入上,云服务厂商加大投入,尤其是将HPC与AI计算结合的超算系统,并已经成为为HPC市场增长的主要贡献者。为了解决超算系统利用率低的问题,云服务厂商在服务器资源规划和灵活部署上采用了新的设计。
接着我们来看看TOP500超算榜单中的前十名,从23年11月公布的TOP500超算榜单中可以看出,中国已公开成绩的最强超算,神威太湖之光已经掉出前十的行业。当然了,这是由于多方面因素造成的,其实国内已经至少有两台E级的超算了,只是出于各种原因并未提交成绩。
其实还有不少私有HPC系统,已经在全速商用运行中,没有必要花费时间来运行LINPACK测试。其实,从2017年起,除了最快的这一批TOP10系统每年都会有所更新外,TOP500每年的提交数量就一直在降低,这是因为新的超算部署成本越来越高,而且这两年不少HPC硬件资源被优先投入进AIGC相关应用的开发中去。
HPC技术发展趋势——AI与云化部署
现如今HPC面临着两大技术变革,AI与云化部署。AI增强了数据集分析,在相同准确度水平下可以更快地获取结果。从新部署的一批HPC系统硬件配置就可以看出,GPU提供的算力比重越来越高,所以也出现了HPC-MxP这样专门针对AI性能进行测试的榜单,从榜单上也可以看出,通用算力和AI算力并不是一回事。
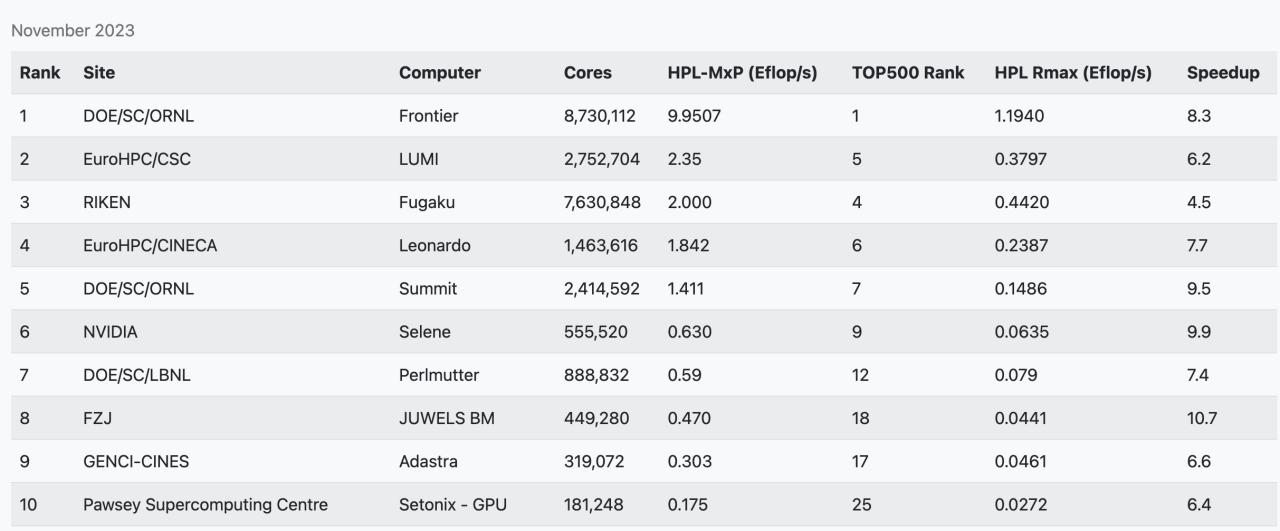
HPC-MxP 超算AI算力榜单
无论是在科学研究还是商业应用领域,都已经出现了对应的AI集成HPC软件,包括1.金融服务分析、物流和制造计算 2.流体力学、计算机辅助工程和辅助设计 3.高能物理的可视化和仿真 4.天气预报、气象学等。
出现这种趋势并不奇怪,近几年GPU演进速度和算力提升速度远远高于CPU,不过HPC系统与这些大火的GPT、LLM应用不一样的是,往往不会去追最新的GPU硬件,原因有二:
1.因为HPC集群规模较大,制造商下GPU订单后,也需要不短的交期才能交付,而目前最新的GPU往往都交付给了云服务厂商;2.如今的GPU在高精度算力上的提升并不如低精度算力,这是因为目前最火的还是各类大模型应用,他们处理的往往是更低精度的数据。
第二个趋势就是云化部署,传统的本地HPC应用往往采用封闭机型和专属架构,包括富岳、神威·太湖之光等,这类系统在计算密集类的应用上依然占据着很大的优势,在科学研究类工作中仍被广泛应用。然而在商业领域,云化部署的HPC运用受欢迎程度越来越高。
但正如上面提到的,新系统的成本越来越高,不仅是硬件成本,还有维护成本。再加上扩容困难、资源利用率较低等问题,把HPC系统转换为数字资源并采用云化部署成了新的趋势。
AWS、Azure、谷歌、阿里云和华为云等推出的HPC集群,为HPC云端部署提供了更加简单的方案。云化部署简化了HPC应用的部署和扩容过程,而且灵活的配置,和近乎无限的scale out拓展性,让其无论是成本还是性能来说,对不少HPC应用而言都是最优解。当然对于国家研究中心之类的单位而言,为了信息安全等考量,本地HPC系统依然是部署的首要选择。
HPC面临的挑战——成本与电力墙
尽管出现了各类创新,HPC市场依旧面临着不小的挑战。首先就是硬件成本的增加,AI的加入,使得HPC系统的总成本再度上了一个新台阶。为了在提高通用计算性能的同时,提高AI算力,大量使用GPU几乎是唯一的出路。而且在目前AI GPU产能有限的情况下,对于一些科研HPC单位而言,获取难度更大。
以H100 GPU为例,Meta、微软、谷歌、Oracle、特斯拉等私有云、公有云厂商的拥有量更大,而且这些厂商仍在持续投入。从前十的超算排名中就能看出,不少国家HPC要么用到AMD或英特尔的GPU,要么采用A100或GV100之类的前代产品比如,单单Meta一家,就需要借助近60万块H100 GPU打造下一代GenAI应用,相较之下排名第三的Eagle超算,只集成了14400块H100 GPU。
另一大挑战就是电力墙。随着计算能力的增加,硬件功耗也随之增加,这导致了热管理和电力供应方面的问题。对于大规模的HPC系统,比如数据中心计算集群和超算而言,电力和冷却成本都会变得非常高。
我们拿排名靠前的几大超算系统为例,其中富岳超级计算机的系统功耗在30到40MW之间,Frontier超级计算机的系统功耗22.7MW。为了推动HPC系统充分改善能效,减少碳足迹,Green500榜单被推出,以单位瓦数的峰值算力作为参考,为的就是促进设计厂商推出能效更高的硬件,以及应用开发商对HPC软件进行进一步优化。
-
AI
+关注
关注
87文章
30728浏览量
268885 -
HPC
+关注
关注
0文章
315浏览量
23753 -
高性能计算
+关注
关注
0文章
82浏览量
13385
发布评论请先 登录
相关推荐
“AI接吻”——AI技术的双刃剑
动态海外住宅IP:全球访问与数据安全的双刃剑
探索出口美国480V变120V UL认证变压器的新机遇

AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
存力与算力并重:数据时代的双刃剑
共话出海未来,共谋发展新篇—“生成式AI,解锁出海新机遇”沙龙成功举办

拉丁美洲与加勒比地区:人工智能浪潮下的就业市场双刃剑
平衡创新与伦理:AI时代的隐私保护和算法公平
苹果AI服务在华面临挑战,寻求本土合作新机遇
华为欧洲游戏沙龙聚焦土耳其,共探市场新机遇
中软国际携手华海智汇共同探索智慧ICT市场新机遇
敦泰:布局高端产品,抢抓柔性OLED市场新机遇






 工商网监
工商网监
评论