 基于英特尔至强可扩展处理器的浪潮信息服务器AI训推一体化方案
基于英特尔至强可扩展处理器的浪潮信息服务器AI训推一体化方案

概 述
大模型已经成为新一轮数字化转型的重要驱动力,为了降低对算力与语料资源的要求,加快大模型在实际应用的部署,目前企业普遍在开源/商用大模型中,加入少量语料对模型进行预训练,以构建面向具体场景的微调版大模型,并在实际业务中进行模型推理,这种方式在经济性与灵活性方面通常更具优势。对于轻量级的人工智能 (AI) 场景而言,找到一个既经济又灵活的AI微调和推理解决方案显得尤为重要。
浪潮信息和英特尔紧密合作,结合在硬件和软件开发方面的技术优势,推出了基于英特尔至强可扩展处理器的浪潮信息服务器AI训推一体化方案。该AI训推一体化方案支持计算机视觉模型的推理工作,同时还支持大语言模型 (LLM) 的微调和推理工作,并可以用于支持其他通用业务。这一方案具备高性能、高性价比、高灵活性等优势,可以充分满足用户构建轻量级AI微调与推理系统的需求。
挑战
在AI模型尤其是大模型微调及推理过程中,用户普遍面临着以下性能挑战:
如何满足AI微调及推理对于算力的要求
在AI模型微调和推理过程中,特别是在大语言模型微调中,对算力的需求尤其突出。这既包括硬件提供的算力支持,也包括向量化指令集和矩阵计算指令集的支持。
如何满足模型微调对于内存规模的需求
在模型训练和微调中,需要存储中间激活值、梯度信息,以及用于优化器(如Adam、AdamW等)参数更新的信息,这就需要庞大的内存作为支撑。模型微调实践表明,Batch size设定不能太小(通常需要大于16),避免Batch size过小造成不稳定的优化器梯度下降。同时,训练过程中会产生大量的中间激活值,所需的内存远远超过模型本身的大小。但是,传统训练方案(双路服务器,一机两卡/一机四卡/一机八卡)由于显存数量有限,难以满足模型微调的显存需求。
如何提供充足的内存带宽
AI推理任务对内存带宽有着高度需求,因此,AI训推服务器需要提供足够大的内存带宽与内存访问速度,传统的双路服务器在内存带宽与访问速度方面难以支撑模型的高效推理。
如何实现便捷扩展
为了提升服务器的算力、内存规模和带宽,模型训练和推理通常需要将多个 CPU socket高效链接起来。而采用以太网作为连接方式将面临速度慢、不稳定、多颗CPU socket的扩展性能差等问题。 除了性能挑战之外,用户还希望能够尽可能地降低模型微调、推理平台的构建与运营成本,提升平台的灵活性,从而进一步推动AI任务的普及和发展。
基于英特尔至强可扩展处理器的浪潮信息服务器AI训推一体化方案
浪潮信息服务器AI训推一体化方案的硬件基础是基于第四代英特尔至强可扩展处理器的浪潮信息四路服务器。该服务器能够充分发挥第四代英特尔至强可扩展处理器强大的计算性能,并借助英特尔高级矩阵扩展(英特尔AMX)和 IntelExtension for PyTorch (IPEX) 进一步加速大模型微调和推理任务,帮助用户攻克AI应用中的各项挑战。

图1. 浪潮信息服务器AI训推一体化方案架构
浪潮信息四路服务器
为了支持在单台浪潮信息四路服务器上,实现复杂的计算机视觉模型和大语言模型的微调及推理任务,浪潮信息服务器AI训推一体化方案推荐采用英特尔至强金牌处理器或以上的型号。这不仅可以为高负荷情况下的任务提供额外的性能提升,还能支持在多线程处理能力上取得优秀表现。 该方案推荐搭配DDR5内存。DDR5内存提供了比前代更高的带宽,特别适合处理内存密集型的应用任务。当处理大规模数据和复杂的计算任务时,DDR5能确保系统运行的流畅性。同时,方案建议按照每个内存通道1个DIMM (1DPC) 的配置,将内存扩展至2TB以上,以满足同时对高带宽和高内存容量的需求。这一配置不仅可以优化系统的运行效率,还能在处理大型数据集时,提供足够的内存支持,从而确保微调任务以及推理任务的顺畅执行。

图2-1. NF8260M7(2U4路)服务器

图2-2. NF8480M7(4U4路)服务器
第四代英特尔至强可扩展处理器提供强大AI算力支持
第四代英特尔至强可扩展处理器通过创新架构增加了每个时钟周期的指令,每个插槽多达60个核心,支持8通道DDR5内存,有效提升了内存带宽与速度,并通过PCIe 5.0(80个通道)实现了更高的PCIe带宽提升。第四代英特尔至强可扩展处理器提供了出色性能和安全性,可根据用户的业务需求进行扩展。借助内置的加速器,用户可以在AI、分析、云和微服务、网络、数据库、存储等类型的工作负载中获得优化的性能。通过与强大的生态系统相结合,第四代英特尔至强可扩展处理器能够帮助用户构建更加高效、安全的基础设施。
第四代英特尔至强可扩展处理器内置了创新的英特尔AMX加速引擎。英特尔AMX针对广泛的硬件和软件优化,通过提供矩阵类型的运算,显著增加了人工智能应用程序的每时钟指令数 (IPC),可为AI工作负载中的训练和推理上提供显著的性能提升。在实际AI推理负载中,英特尔AMX能够加速模型微调、提升模型的首包推理速度并降低延迟。英特尔AVX-512指令集能够加速在KV Cache模式下的第二个及以上的token推理。
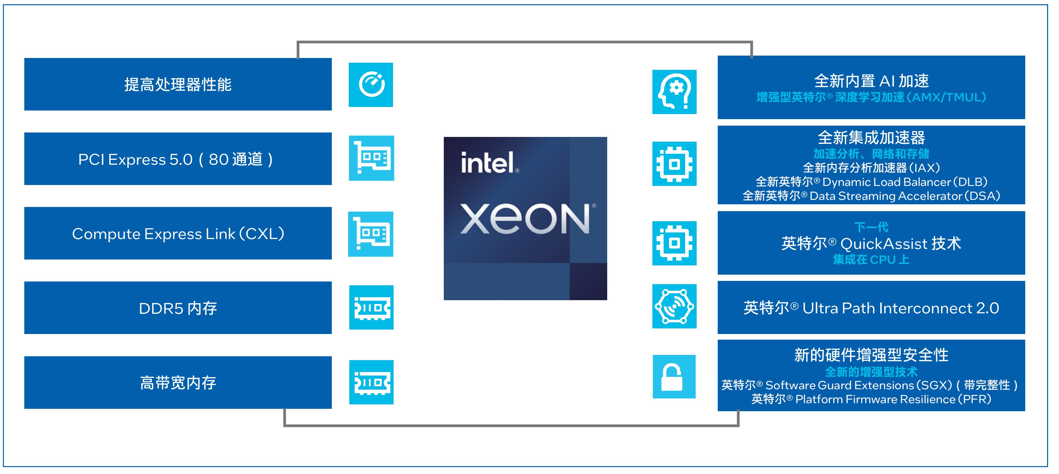
图3. 英特尔至强可扩展处理器为数据中心提供多种优势
英特尔丰富软件生态助力加速AI部署,释放算力潜能
除了在硬件领域取得显著进展之外,英特尔在人工智能领域亦构建了一个强大且全面的软件生态系统,提供了包含 IntelExtension for PyToch和英特尔oneDNN在内的丰富软件,能够帮助用户充分利用英特尔硬件的强大性能,提高计算效率和运行速度。
IntelExtension for PyTorch是一种开源扩展,可优化英特尔处理器上的深度学习性能。许多优化最终将包含在未来的PyTorch主线版本中,但该扩展允许PyTorch用户更快地获得最新功能和优化。IntelExtension for Pytorch充分利用了英特尔AVX- 512、矢量神经网络指令 (VNNI) 和英特尔AMX,将最新的性能优化应用于英特尔硬件平台。这些优化既包括对PyTorch操作符、Graph和Runtime的改进,也包括特定于使用场景的自定义操作符和优化器的添加。用户可以通过简易的Python API,只需对原始代码做出微小更改即可在英特尔硬件平台应用最新性能优化。
英特尔oneAPI Deep Neural Network Library (oneDNN) 是英特尔在软件优化领域的又一亮点。英特尔oneDNN是一个开源性能库,专为深度学习应用设计,支持广泛的深度学习框架和应用。该库提供了高级性能优化的深度学习原语,专门优化了用于英特尔架构的深度学习操作,包括英特尔至强处理器和 英特尔集成显卡。通过oneDNN,开发者可以轻松地在英特尔硬件上实现高效的深度学习模型推理和训练,而无需深入了解底层硬件细节。英特尔oneDNN已经被融合到多个开源平台中,包括PyTorch和TensorFlow等。
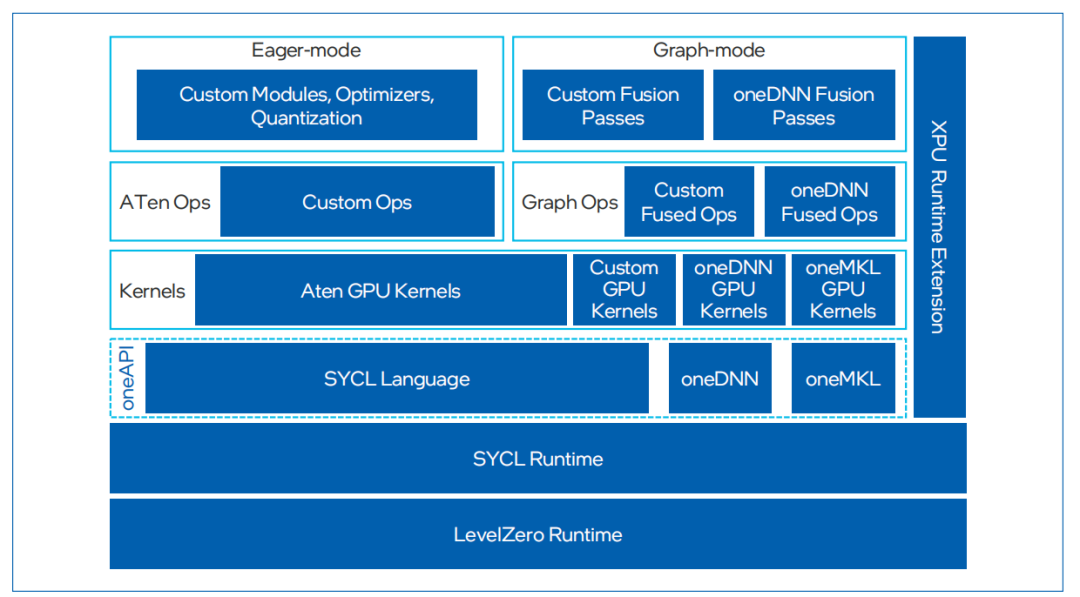
图4. IntelExtension for PyTorch框架 
测 试 验 证
在上述软硬件基础上,浪潮信息与英特尔合作,从多个方面入手,优化了AI模型微调及推理性能。
采用英特尔AMX加速器和IntelExtension for PyTorch加速模型微调
得益于对IntelExtension for PyTorch的支持,以及强大的运算能力和超大内存,浪潮信息四路服务器在微调方面表现出强大的性能。浪潮信息四路服务器采用分布式数据并行 + LoRA (Low-Rank Adaptation) 微调以减少通信开销,其具备的大内存有利于支持更大的batch size,从而提高训练的收敛效果,改善模型质量。目前,单台浪潮信息四路服务器能够支持高达30B模型的微调。
模型微调的测试数据如图5显示,当采用alpaca数据集(6.5M tokens,数据集大小24.2MB)时,单台四路服务器可以在72分钟的时间内完成Llama-2-7B微调 (batch size = 16);可以在362分钟的时间内完成Llama-30B模型的微调 (batch size = 16),稳定支持非梯度累积模式下高达64的batch size1。
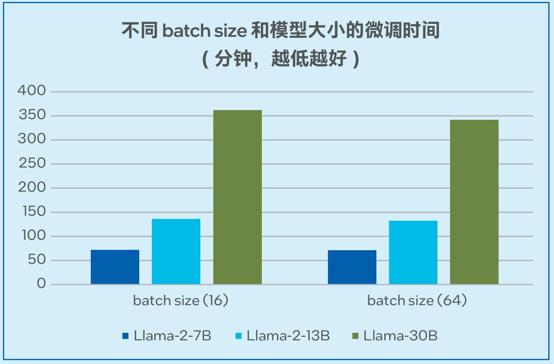
图5. Llama-2-7B/13B/30B模型的微调时间
采用英特尔AMX加速器和张量并行加速大语言模型推理
浪潮信息四路服务器采用了英特尔UPI全拓扑连接方式, 张量并行推理方案下等同于有效地扩展了内存带宽。这一优势与英特尔AMX加速器一起,使得服务器最终在推理7/13B参数级别的模型时表现出高度的可扩展性。
测试数据如图6-1和图6-2所示,在7B和13B规模的模型中,模型推理的延迟可以低至20毫秒左右2,能够满足实际业务对于推理性能的要求。
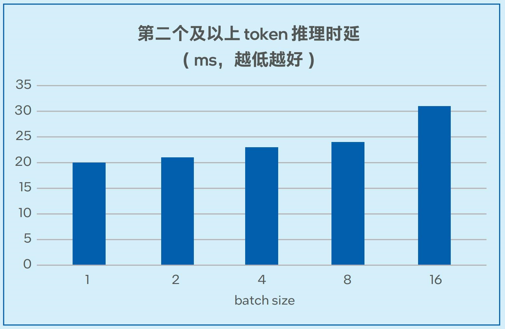
图6-1. 不同batch size下Llama-2-7B推理延迟测试
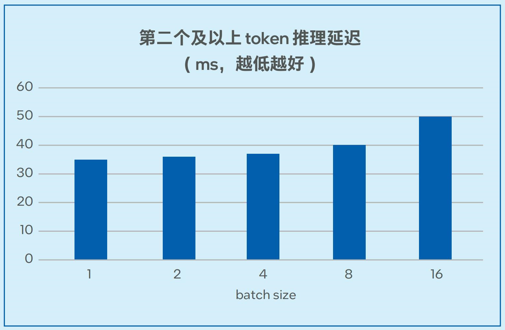
图6-2. 不同batch size下Llama-2-13B推理延迟测试
采用英特尔AMX加速器和IntelExtension for PyTorch提升视觉模型推理性能
在非大语言模型的通用AI负载中,一般矩阵乘法(General Matrix Multiplication, GEMM) 往往消耗最多时间,推理训练都受算力限制。浪潮信息四路服务器在为基于CNN的视觉模型推理带来更强算力的同时,利用英特尔高级矩阵扩展(AMX) 加速矩阵乘法运算。如图7所示,对于经典的视觉模型ResNet50,在推理阶段,单颗处理器吞吐量最高可以达到2942.57FPS。同时,该解决方案可以支持高并发,在单台四路配置时可以达到11322.08 FPS的吞吐量3。
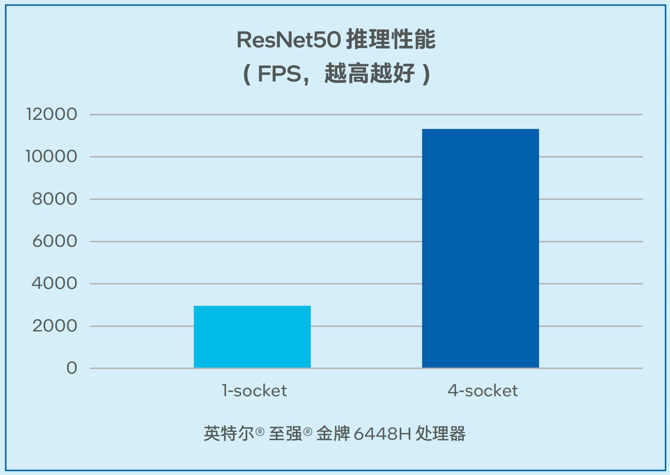
图7. 浪潮信息四路服务器 ResNet50推理性能
收 益
基于英特尔至强可扩展处理器的浪潮信息服务器AI训推一体化方案能够为用户AI任务带来以下收益:
满足中小规模的模型对于微调及推理的算力需求:通过硬件构建与软件优化,该AI训推一体化方案提供了强大的模型微调与推理算力支持,在7B和13B规模的模型中,模型推理的延迟可以低至20毫秒左右,在基于CNN的视觉模型推理中,单台四路服务器上可以达到11322.08FPS的吞吐量4。
更高的适用性、扩展性:该AI训推一体化方案可以灵活地支持计算机视觉模型推理、大语言模型的微调和推理,以及其它通用业务,并实现更高的扩展性。
更高的性价比与投资回报:对比专用的AI服务器方案,该AI训推一体化方案具备高性价比、高可及性等优势,可助力用户获得更高的投资回报。
展 望
在智能化成为业务关键驱动力的今天,用户急切希望搭建自己的AI训练与推理计算平台,以便能够跻身人工智能热潮之中,探索和扩展他们的AI业务领域。以英特尔至强可扩展处理器为基础的浪潮信息服务器AI训推一体化方案凭借在性价比与灵活性等方面的优势,有望成为推动AI微调与推理的关键基础设施。
展望AI技术的未来发展,其不仅将创造更多的业务形态,而且为企业创造了巨大的商业潜力和发展机遇。浪潮和英特尔双方将在技术探索、产品升级、应用推广等多个层面深度协作,推动AI在更多应用场景的创新以及普及,助力AI的应用与发展。
审核编辑:刘清
-
处理器
+关注
关注
68文章
20368浏览量
255530 -
以太网
+关注
关注
41文章
6268浏览量
181838 -
DDR5
+关注
关注
1文章
490浏览量
25850 -
pytorch
+关注
关注
2文章
813浏览量
14944 -
AI大模型
+关注
关注
0文章
415浏览量
1051
原文标题:浪潮信息基于至强® 可扩展处理器推出 AI 服务器训推一体化方案
文章出处:【微信号:英特尔中国,微信公众号:英特尔中国】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
AI工作站本地养龙虾!英特尔双芯混合算力,告别云端Token焦虑

英特尔发布至强600系列工作站处理器与锐炫Pro B70 GPU,双芯联动重塑AI工作站格局

英特尔至强6“芯”动GTC 2026,为英伟达DCG Rubin解锁系统级性能
润和软件AIRUNS训推一体化平台与昇腾910C芯片深度适配

全球首款落地!英特尔携手新华三等合作伙伴,重磅推出全域液冷服务器

打造智算基石:英特尔携手本土生态发布全域液冷服务器

英特尔携本地生态伙伴发布双路冷板式全域液冷服务器,引领数据中心散热与能效革新


从云到端:英特尔展示全栈AI能力,覆盖云、边、PC多场景

英特尔以通感智算一体化方案,驱动网络与边缘智能化升级

英特尔288核新至强处理器揭秘:Intel 18A制程,3D堆叠与键合,EMIB封装……
主控CPU全能选手,英特尔至强6助力AI系统高效运转

英特尔发布边缘AI控制器与边缘智算一体机,创造“AI新视界”

术业有专攻——AI系统主控CPU英特尔至强6新品处理器浅析




评论