 日本超算富岳助力构建大规模语言模型Fugaku-LLM
日本超算富岳助力构建大规模语言模型Fugaku-LLM
日本多企业联合科研组于昨日宣布推出Fugaku-LLM大模型,此模型基于Arm架构的“富岳”超级计算机进行培训,呈现出显著特性。
Fugaku-LLM模型项目自2023年5月起启动,初始参加方包括富士通、东京工业大学、日本东北大学及日本理化学研究所(简称理研)。至同年8月,又有三家合作伙伴——名古屋大学、CyberAgent(Cygames母公司)以及HPC-AI领域创新企业Kotoba Technologies加入。
在昨日公布的新闻稿中,研究团队表示他们成功发掘了富岳超级计算机的潜能,使矩阵乘法运算速度提升六倍,通信速度提高三倍,从而证实大型纯CPU超级计算机同样适用于大模型训练。
Fugaku-LLM模型参数规模达13B,成为日本国内最大的大型语言模型。该模型利用13824个富岳超级计算机节点,在3800亿个Token上进行训练,其中60%为日语数据,其余40%涵盖英语、数学、代码等内容。
研究团队表示,Fugaku-LLM模型能够在交流过程中自然运用日语敬语等特殊表达方式。
在测试结果方面,该模型在日语MT-Bench模型基准测试中的平均得分高达5.5,位列基于日本语料资源的开放模型之首;同时,在人文社科类别的测试中获得9.18的高分。
目前,Fugaku-LLM模型已在GitHub和Hugging Face平台公开发布,外部研究人员和工程师可以在遵循许可协议的前提下,将该模型应用于学术和商业领域。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
cpu
+关注
关注
68文章
10922浏览量
213280 -
超级计算机
+关注
关注
2文章
464浏览量
42046 -
大模型
+关注
关注
2文章
2652浏览量
3267
发布评论请先 登录
相关推荐
新品| LLM630 Compute Kit,AI 大语言模型推理开发平台
处理器,集成了3.2TOPs@INT8算力的高能效NPU,提供强大的AI推理能力,能够高效执行复杂的视觉(CV)及大语言模型(LLM)任务,满足各类智能应用场景的需求

什么是LLM?LLM在自然语言处理中的应用
所未有的精度和效率处理和生成自然语言。 LLM的基本原理 LLM基于深度学习技术,尤其是变换器(Transformer)架构。变换器模型因其自注意力(Self-Attention)机制
LLM和传统机器学习的区别
和训练方法 LLM: 预训练和微调: LLM通常采用预训练(Pre-training)和微调(Fine-tuning)的方法。预训练阶段,模型在大规模的文本数据上学习
新品|LLM Module,离线大语言模型模块
LLM,全称大语言模型(LargeLanguageModel)。是一种基于深度学习的人工智能模型。它通过大量文本数据进行训练,从而能够进行对话、回答问题、撰写文本等其他任务
llm模型和chatGPT的区别
LLM(Large Language Model)是指大型语言模型,它们是一类使用深度学习技术构建的自然语言处理(NLP)
LLM模型的应用领域
在本文中,我们将深入探讨LLM(Large Language Model,大型语言模型)的应用领域。LLM是一种基于深度学习的人工智能技术,它能够理解和生成自然
预定下代超算第一?富士通144核Arm处理器公开
设计A64FX SoC,整个超算集群的峰值性能可以达到537.21PFlop/s。如此强大的性能,甚至于日本东京工业大学、日本东北大学等都宣布将借助
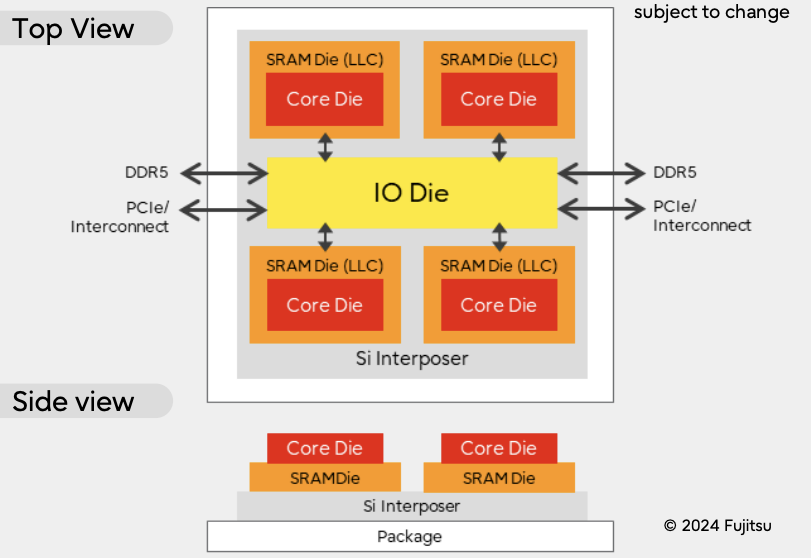
大语言模型(LLM)快速理解
自2022年,ChatGPT发布之后,大语言模型(LargeLanguageModel),简称LLM掀起了一波狂潮。作为学习理解LLM的开始,先来整体理解一下大

LLM之外的性价比之选,小语言模型
。然而在一些对实时性要求较高的应用中,比如AI客服、实时数据分析等,大语言模型并没有太大的优势。 在动辄万亿参数的LLM下,硬件需求已经遭受了不小的挑战。所以面对一些相对简单的任务,规模
超算训练大模型,不浪费一丁点计算资源
政府也投入到LLM的计算资源整合中来,从而不至于落后这轮新的全球技术军备战。同样的计算资源竞争也发生在超算领域,而两者的计算资源存在一定的重合,不少人开始借助超算来进行
日本团队发布在富岳超算上训练的Fugaku-LLM大模型
自2023年5月起,Fugaku-LLM模型的开发工作开始展开,最初参与团队包括富士通、东京工业大学、日本东北大学以及日本理化学研究所(简称理研)。
【大语言模型:原理与工程实践】揭开大语言模型的面纱
用于文本生成,根据提示或上下文生成连贯、富有创造性的文本,为故事创作等提供无限可能。大语言模型也面临挑战。一方面,其计算资源需求巨大,训练和推理耗时;另一方面,模型高度依赖数据,需要大规模
发表于 05-04 23:55
名单公布!【书籍评测活动NO.30】大规模语言模型:从理论到实践
,在大模型实践和理论研究的过程中,历时8个月完成 《大规模语言模型:从理论到实践》 一书的撰写。希望这本书能够帮助读者快速入门大模型的研究和
发表于 03-11 15:16





 工商网监
工商网监
评论