 无监督深度学习实现单次非相干全息3D成像
无监督深度学习实现单次非相干全息3D成像
论文信息

背景引入
数字全息术因其能够从单一视点对3D场景进行成像而备受关注。与直接成像相比,数字全息是一种间接的多步骤成像过程,包括光学记录全息图和数值计算重建,为包括深度学习在内的计算成像方法提供了广泛的应用场景。近年来,非相干数字全息术因其成像分辨率高,无散斑噪声和边缘效应,低成本等优点而备受关注。目前,非相干全息术已被应用于孔径成像、超分辨成像、大景深成像和晶格光片显微成像。
近年来,深度学习已被应用于非相干数字全息术。然而,目前所有的报告都是基于数据驱动的监督学习方法,这些方法需要大量的配对标记数据,并且存在泛化不足等问题。为了解决上述挑战,本文提出了一种无训练神经网络先验的单次非相干全息自校准3D重建方法,称为SC-RUN。SC-RUN可以提高点扩散函数(PSF)的保真度和信噪比,只需单个全息图就可以实现3D对象的高保真度和无伪影重建。本文以无干涉编码孔径相关全息术(I-COACH)成像为例,清楚地展示了SC-RUN的效果。
方法原理
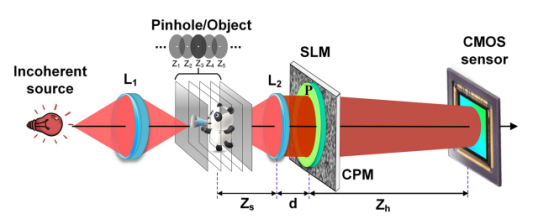
图1 非干涉编码孔径关联全息术装置
非相干光源的光被透镜L1聚焦以照射物体。物体位于透镜L2的前焦平面Z3附近,使得物体可以被认为位于CPM的远场中。加载了编码相位的SLM位于透镜L2距离d处,SLM前加偏振片P。由于I-COACH的成像模型在强度上是线性空间不变,因此传感器记录的物体全息图可以被视为无数个物点全息图的非相干强度叠加,因此,可以先对一个物点的光场进行理论分析,然后通过卷积或叠加得到多物点物体的成像模型。
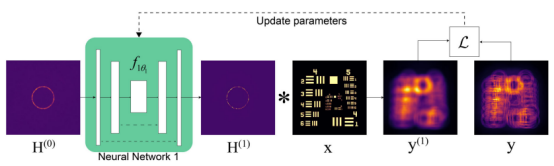
图2 SC-RUN—校准点扩散函数结构
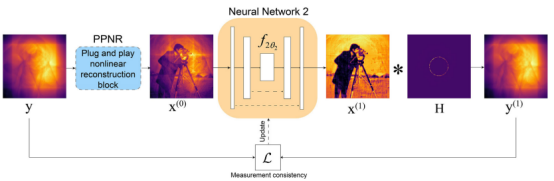
图3 SC-RUN—基于无训练神经网络先验的单次成像结构
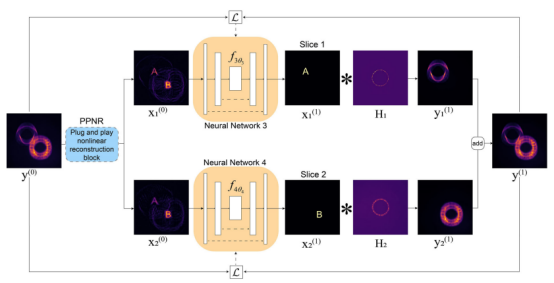
图4 SC-RUN—基于无训练神经网络先验的单次3D成像结构
系统光路
多通道I-COACH实验系统如图5所示,其中振幅型空间光调制器的产品参数如下表所示。
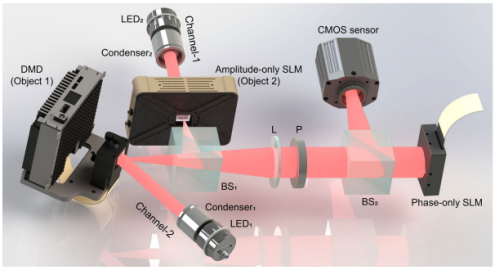
图5 I-COACH实验装置
本实验所采用的空间光调制器为我司的TSLM07U-A,其参数规格如下:
|
型号 |
TSLM07U-A |
调制类型 |
振幅型 |
|
液晶类型 |
透射式 | 灰度等级 |
8位,256阶 |
|
像素数 |
1920×1080 |
像元大小 | 8.5μm |
|
有效区域 |
0.74" 16.3mm×9.18mm |
对比度 | 600:1 |
| 响应时间 | 上升7ms,下降20ms |
开口率 |
57% |
|
刷新频率 |
60Hz | 光学利用率 |
20%@633nm |
|
电源输入 |
24V 1A&5V 1A |
光谱范围 |
380nm-1200nm |
|
损伤阈值 |
2W/cm² |
数据接口 |
DVI |
系统由不同轴向平面中的两个目标通道组成,其中数字微镜器件(DMD)用作通道1中的目标1,而振幅型空间光调制器用作通道2中的目标2。来自空间非相干发光二极管(LED)的光通过聚光器收集以照射物体,然后两个通道内衍射的物体光通过分束棱镜(BS1)组合并通过透镜L进行准直。偏振片P使物光的偏振方向与纯相位SLM的调制轴方向一致。最后,通过CMOS传感器记录由纯相位SLM调制的光波。纯相位SLM加载由GSA算法合成的全息图。
实验结果
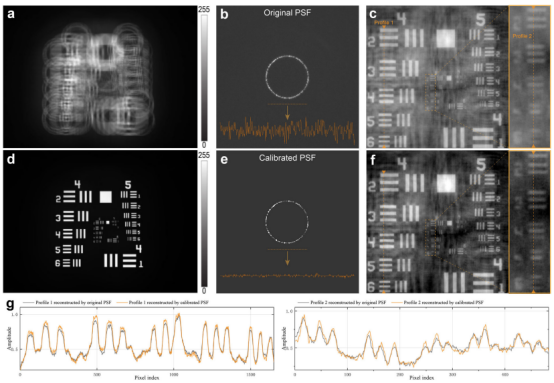
图6 SC-RUN对PSF的校准结果。a) 全息图,b) 原始PSF,c) 使用原始PSF进行非线性重建的结果,d) 已知对象,e) 校准后的PSF,f) 使用校准的PSF进行非线性重建的结果。

图7 SC-RUN和非线性重建的2D实验结果
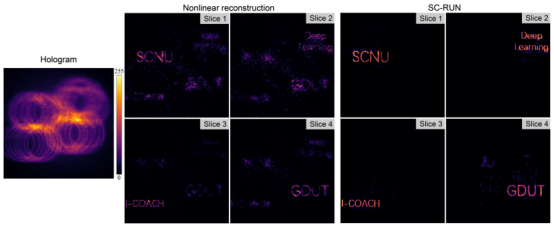
图8 SC-RUN和非线性重建的3D实验结果
以上实验结果表明,SC-RUN在I-COACH上表现良好,从而说明预先校准PSF,然后通过神经网络重建对象的这一策略具有很大的潜力。目前,许多光学成像技术都是通过设计专门的PSF来实现的。例如,通过波前编码生成亚衍射极限点PSF,以实现超分辨率成像。类似地,通过使用波前编码使PSF对错误聚焦不敏感,可以扩展成像深度。对于其他信息,如物体的深度、光谱和偏振,可以编码到PSF中来增加成像维度。上述计算成像技术在很大程度上依赖于PSF的先验信息,并且SC-RUN允许获得高保真度、高信噪比的PSF。因此,当已知前向算子时,可以获得极好的重建结果。此外,由于SC-RUN在不需要数据集和标签的情况下强制测量一致性,并且考虑到大多数成像任务涉及具有已知正向算子的一个或多个逆求解模型,SC-RUN可以容易地应用于各种其他成像任务。
论文总结
本文提出了一种通用的无监督的非相干全息3D重建框架SC-RUN,它结合了非线性重建方法的物理知识和前向成像模型,通过具有额外物理约束的神经网络执行重建任务。SC-RUN同时考虑了时间分辨率和保真度,具有良好的鲁棒性,并且不需要太多标记的数据驱动信息。此外,实验结果表明,首次在非相干全息术中实现了具有强度变化的复杂物体的高保真度重建。SC-RUN通常适用于各种光学配置,并易于适应其他成像任务。此外,SC-RUN对超分辨率成像、孔径成像、景深扩展成像和多维信息复用等领域具有广泛潜力,为获得动态光场的多维信息铺平了道路。
文章链接:https://doi.org/10.1002/lpor.202301091
审核编辑 黄宇
-
3D
+关注
关注
9文章
2926浏览量
108363 -
成像
+关注
关注
2文章
248浏览量
30618 -
3D成像
+关注
关注
0文章
98浏览量
16215 -
深度学习
+关注
关注
73文章
5527浏览量
121833
发布评论请先 登录
相关推荐
对于结构光测量、3D视觉的应用,使用100%offset的lightcrafter是否能用于点云生成的应用?
超景深3D检测显微镜技术解析
多维精密测量:半导体微型器件的2D&3D视觉方案
3D深度感测的原理和使用二极管激光来实现深度感测的优势
光纤端面3D干涉仪的单色光移相干涉测量法

傅里叶光场显微成像技术—2D显微镜实现3D成像

欢创播报 腾讯元宝首发3D生成应用

全息投影空中成像原理是什么
机载单光子激光雷达系统用于实现高分辨率3D成像
奥比中光携多款3D相机深度参与国内3D视觉最高规格会议

NVIDIA生成式AI研究实现在1秒内生成3D形状







 工商网监
工商网监
评论