 K折交叉验证算法与训练集
K折交叉验证算法与训练集
K折交叉验证算法通常使用数据集中的大部分数据作为**训练集**。
K折交叉验证是一种评估模型性能的统计方法,它涉及将数据集分成K个子集,每个子集大致等大。在K折交叉验证过程中,其中一个子集被留作测试集,而其余的K-1个子集合并起来形成训练集。这个过程会重复K次,每次选择不同的子集作为测试集,以确保每个样本都有机会作为测试集和训练集的一部分。这种方法可以有效地评估模型对新数据的泛化能力,因为它考虑了数据集的多个子集。具体步骤如下:
1. 数据划分:原始数据集被平均分成K个子集。这些子集通常具有相似的数据分布,以确保训练过程的稳定性。
2. 模型训练:在每次迭代中,K-1个子集被合并用作训练集,剩下的一个子集用作验证集。模型在训练集上进行训练。
3. 模型验证:训练好的模型在保留的验证集上进行测试,以评估模型的性能。
4. 性能汇总:重复上述过程K次,每次都使用不同的子集作为验证集。最后,将所有迭代的结果平均,得到模型的整体性能估计。
5. 模型选择:如果有多个模型需要比较,可以根据K折交叉验证的结果选择表现最佳的模型。
6. 最终测试:一旦选择了最佳模型,可以在未参与交叉验证的独立测试集上进行最终测试,以验证模型的泛化能力。
总的来说,K折交叉验证的优势在于它能够更全面地利用数据集,每个数据点都有机会参与训练和测试,从而提高了评估的准确性。此外,它还可以减少由于数据划分方式不同而导致的评估结果波动。然而,这种方法的缺点是计算成本较高,因为需要多次训练模型。此外,如果数据集太小,K折交叉验证可能不够稳定,因为每次迭代的测试集只有总数据集的一小部分。
审核编辑 黄宇
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
算法
+关注
关注
23文章
4646浏览量
93717 -
数据集
+关注
关注
4文章
1212浏览量
24990
发布评论请先 登录
相关推荐
大模型训练:开源数据与算法的机遇与挑战分析
进行多方位的总结和梳理。 在第二章《TOP 101-2024 大模型观点》中,苏州盛派网络科技有限公司创始人兼首席架构师苏震巍分析了大模型训练过程中开源数据集和算法的重要性和影响,分析其在促进 AI 研究和应用中的机遇,并警示相
第三章:训练图像估计光照度算法模型
,我使用图片的 rgb 数值经过算法**r\*0.2126+g\*0.7152+b\*0.0722**计算亮度。这样就有了一定数量的数据集。也就有基础进行后续的训练和测试了。
【飞凌嵌入式OK3576-C开发板体验】RKNN神经网络算法开发环境搭建
download_model.sh 脚本,该脚本
将下载一个可用的 YOLOv5 ONNX 模型,并存放在当前 model 目录下,参考命令如下:
安装COCO数据集,在深度神经网络算法中,模型的训练离不开大量的数据
发表于 10-10 09:28
pycharm怎么训练数据集
在本文中,我们将介绍如何在PyCharm中训练数据集。PyCharm是一款流行的Python集成开发环境,提供了许多用于数据科学和机器学习的工具。 1. 安装PyCharm和相关库 首先,确保你已经
机器学习中的交叉验证方法
在机器学习中,交叉验证(Cross-Validation)是一种重要的评估方法,它通过将数据集分割成多个部分来评估模型的性能,从而避免过拟合或欠拟合问题,并帮助选择最优的超参数。本文将详细探讨几种
如何理解机器学习中的训练集、验证集和测试集
理解机器学习中的训练集、验证集和测试集,是掌握机器学习核心概念和流程的重要一步。这三者不仅构成了模型学习与评估的基础框架,还直接关系到模型性
神经网络如何用无监督算法训练
标记数据的处理尤为有效,能够充分利用互联网上的海量数据资源。以下将详细探讨神经网络如何用无监督算法进行训练,包括常见的无监督学习算法、训练过程、应用及挑战。
人脸识别模型训练失败原因有哪些
人脸识别模型训练失败的原因有很多,以下是一些常见的原因及其解决方案: 数据集质量问题 数据集是训练人脸识别模型的基础。如果数据集存在质量问题
人脸识别模型训练是什么意思
人脸识别模型训练是指通过大量的人脸数据,使用机器学习或深度学习算法,训练出一个能够识别和分类人脸的模型。这个模型可以应用于各种场景,如安防监控、身份认证、社交媒体等。下面将介绍人脸识别模型训练
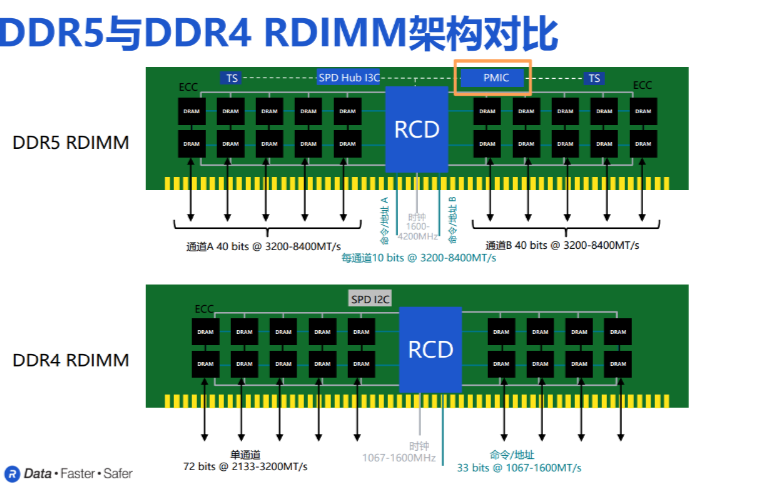
AI训练狂飙,DDR5集成PMIC护航,内存技术持续助力
电子发烧友网报道(文/黄晶晶)AI训练数据集正高速增长,与之相适应的不仅是HBM的迭代升级,还有用于处理这些海量数据的服务器内存技术的不断发展。 以经过简化的AI训练管道流程来看,在数据采集进来
PyTorch如何训练自己的数据集
PyTorch是一个广泛使用的深度学习框架,它以其灵活性、易用性和强大的动态图特性而闻名。在训练深度学习模型时,数据集是不可或缺的组成部分。然而,很多时候,我们可能需要使用自己的数据集而不是现成
【基于存内计算芯片开发板验证语音识别】训练手册
本教程展现语音识别算法在WTM2101开发板上从训练到部署的全流程,包括实验环境搭建,语音数据集以及算法模型转换烧录。





 工商网监
工商网监
评论