 截杀ChatGPT-4o,谷歌系AI产品迎来全面升级
截杀ChatGPT-4o,谷歌系AI产品迎来全面升级
电子发烧友报道(文/周凯扬)作为算法巨头的谷歌,在AI时代发布了一系列AI产品,比如Gemini、Bard等。在AI行业日新月异快速迭代的局面下,即便是谷歌也需要加快开发速度,不断更新其AI模型和应用。近日举办的谷歌I/O大会上,谷歌宣布全面进入Gemini时代,并发布了一系列与AI相关的更新。
对标ChatGPT-4o,谷歌发布Project Astra
相信本周ChatGPT-4o的演示,已经令不少人期待起这个支持视听输入的实时AI助手,谷歌也不甘示弱,发布了Project Astra的演示,展示了他们对于未来AI助手的构想。Project Astra基于Gemini模型打造,支持视频和语音的输入,通过连续的视频帧编码和先进的语音模型,谷歌得以更快地处理输入信息。
相较其ChatGPT-4o更先进的是,谷歌的Project Astra还支持实时交互,比如在手机上圈选出实时视频画面中的一部分,让AI助手提供描述等。不仅如此,Project Astra将视频与语音输入转换成一连串的时间线事件,并缓存这些信息用于未来的高效回溯。
谷歌也对该项目未来的应用场景进行了构想,这些功能不仅可以用于手机端,更是可以用于AR眼镜,为用户提供交互式的AI助手体验。谷歌在外媒的采访中也证实,他们正在考虑为Project Astra打造新的AR眼镜的构想。他们认为对于AR设备来说,Project Astra很有可能成为新一轮的杀手级应用。
安卓迎来新一轮AI功能更新
在这个AI重塑手机体验的世代,而安卓作为全球用户技术最大的智能手机系统,谷歌也希望能用AI带去全新的设备交互方式。
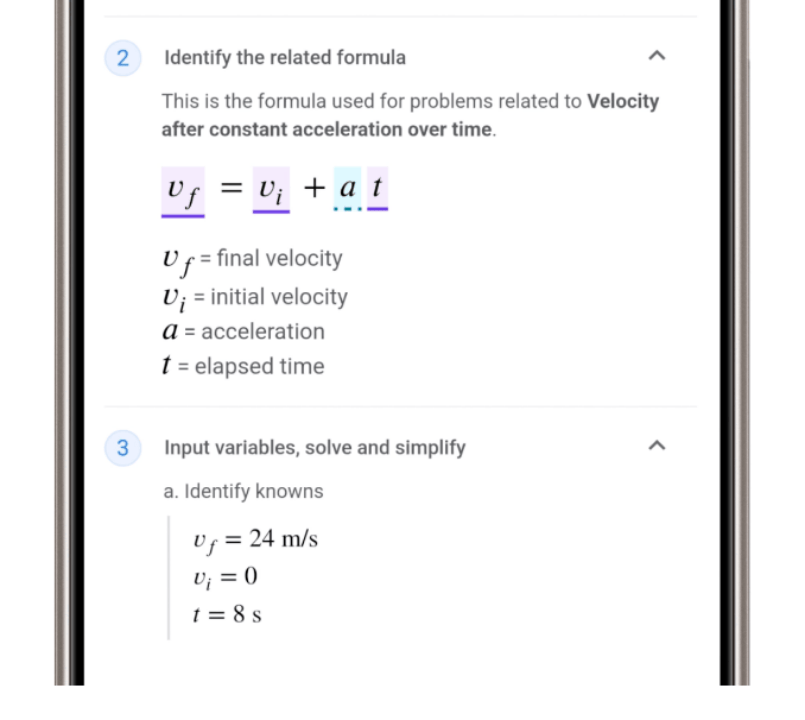
圈选搜索解题 / 谷歌
自从在三星Unpacked大会上公布圈选搜索功能,谷歌已经为更多Pixel和三星设备加入了全屏翻译等功能。在I/O大会上,谷歌宣布为圈选搜索加入作业辅助的功能,比如面对某些物理和数学应用题,圈选搜索不仅可以给出答案,还可以列出具体的解题过程。
安卓上的Gemini已经成为新一代的助手应用,借助生成式人工智能来提供创造力和效率,而未来几个月内,谷歌将为其推送更新,可以在使用中的应用程序中唤醒,并将生成的图片、文字等拖拽到其他应用上。

Gemini Nano / 谷歌
至于端侧的Gemini Nano,同样将在今年年末迎来升级,引入多模态支持。为了做到离线使用和保证用户隐私,谷歌于去年底推出了Gemini Nano,而多模态的加入将引入对文本之外的视觉声音支持。以语音反馈功能为例,对于盲人或弱视群体,在面对无标签的图片时,Gemini Nano赋能的语音反馈功能将提供更多细节的描述。
谷歌同样借助Gemini Nano对语音的支持,引入了可选的防诈骗功能。通过在通话过程中检测到与诈骗相关的对话模式,手机就会自动发出实时警报,比如要求紧急转账、提供银行卡密码等。因为这些保护措施都是在端侧完成的,所以此类对话都是完全保密的,用户无需担心隐私泄露问题。
第六代TPU Trillium,性能与能效双提升
在本届I/O大会上,谷歌也宣布了AI基础设施的升级,其TPU将迎来第六代产品,Trillium。相较TPU v5e,谷歌扩大了MXU(矩阵乘法单元)的大小,并提高了时钟速度,使得Trillium单芯片的峰值计算性能实现了4.7倍的提升,能效提升67%。
同时谷歌还加倍了HBM内存的容量和带宽,更大的内存容量和带宽允许Trillium可以跑更多权重、更大KV缓存和更大规模的模型。谷歌称下一代的HBM带来了带宽提升和能效提升,改善了大模型的训练时间以及服务时延。
同样加倍的还有片间互联带宽,这使得Trillium的扩展性大大加强,单个服务器Pod内可借助定制的光学ICI做到256个芯片互联,再借助谷歌的Jupiter网络扩展至数百个Pod互联。
从第一代TPU开始,谷歌已经将这一加速硬件集成到其提供的各种软件服务中,比如实时语音搜索、照片物体识别以及交互式语言翻译等等,当然也包括了最新的Gemini、Imagen和Gemma等模型。除此之外,一些行业模型也将从TPU中受益,比如自动驾驶模型、药物开发模型等。据谷歌预告,Trillium将于今年年末开放给谷歌云客户。
Gemini和Gemma迎来全面迭代升级
除了上面提到的安卓端Gemini新功能外,Gemini模型本身也将迎来新一轮升级。在Gemini 1.5 Pro发布后不到半年,谷歌就再次对其进行了升级,如今的Gemini 1.5 Pro将支持两百万Token的上下文窗口。
除此之外,谷歌还加强了Gemini 1.5 Pro的代码生成、逻辑推理和多轮对话交互能力。不仅音频和图像的理解能力也得到了进一步加强,不少特殊用例的模型响应控制也得到了提升,比如不同的对话角色和响应风格。无论是使用API的开发者还是谷歌云用户,现在都可以申请这一升级。
为了响应用户对低时延和低成本模型的要求,谷歌还推出了轻量版的Gemini 1.5 Pro:Gemini 1.5 Flash。Gemini 1.5 Flash专门针对高流量、高频率的任务进行了优化,支持100万的Token上下文窗口,而且支持文本、图片、语音和视频的混合输入。
开放模型Gemma同样迎来了升级,首先是新推出的视觉语言模型PaliGemma,其灵感来源自PaLI-3,支持图片和文本作为输入,可以回答有关图片的问题,并提供详细信息和上下文,可以用于对图片或短视频添加说明、对象检测等。其主要优势在于支持多模态理解,而且可以针对各种视觉语言任务进行微调,也有专门面向研究的版本PaliGemma-FT,可对特定的研究数据集进行微调。
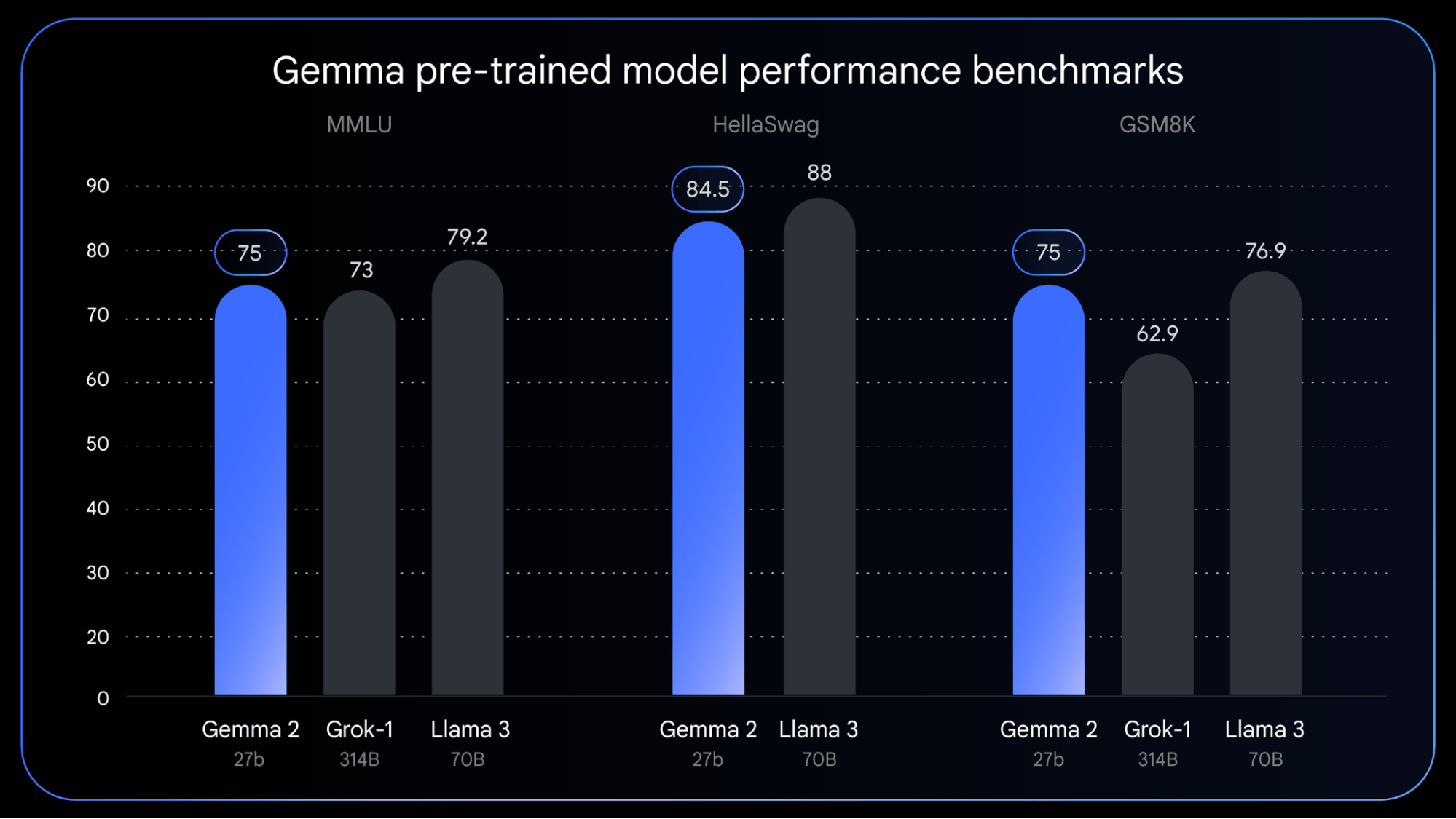
Gemma 2性能测试对比 / 谷歌
此外还有下一代Gemma模型的更新,Gemma 2。Gemma 2是一个270亿参数的大模型,得益于全新的架构,在性能和效率上均实现了突破。相较于Meta的Llama 3 70B模型,其规模只有一半不到,却可以实现与之相近的性能。从预训练阶段的测试成绩来看,Gemma 2仅仅略微逊色于Llama 3,快于Grok-1。除了针对英伟达GPU做了优化外,Gemma 2还可以高效地运行在单个TPU主机上,进一步降低了用户的部署成本。目前Gemma 2依然还在预训练阶段,预计将于今年六月推出。
写在最后
谷歌通常会将年度I/O开发者大会的舞台用于发布Android系统,以及Pixel智能手机的下一代更新。但从今年的发布内容来看,谷歌已经全面转向了AI产品的开发。无论是Android 15的下一个Beta版本,还是Pixel 8a,都只是被短短提及而已。由此可以看出,谷歌已经将下一轮软硬件的革新全面押注在了AI上,未来我们将见证一个围绕AI开发产品矩阵的新谷歌崛起。
-
谷歌
+关注
关注
27文章
6166浏览量
105352 -
AI
+关注
关注
87文章
30830浏览量
268996 -
ChatGPT
+关注
关注
29文章
1560浏览量
7625
发布评论请先 登录
相关推荐
AI眼镜形态席卷可穿戴市场!谷歌眼镜几次“流产”,将靠AI翻盘

解锁 GPT-4o!2024 ChatGPT Plus 代升级全攻略(附国内支付方法)
蚂蚁数科以AI全面升级云产品
华纳云:ChatGPT 登陆 Windows
启明智显:深度融合AI技术,引领硬件产品全面智能化升级
超ChatGPT-4o,国产大模型竟然更懂翻译,8款大模型深度测评|AI 横评

国内直联使用ChatGPT 4.0 API Key使用和多模态GPT4o API调用开发教程!

OpenAI 深夜抛出王炸 “ChatGPT- 4o”, “她” 来了
两小时“吼出”121次AI,谷歌背后埋伏着Open AI的幽灵
谷歌发布多模态AI新品,加剧AI巨头竞争
OpenAI推出面向所有用户的AI模型GPT-4o
新火种AI|挑战谷歌,OpenAI要推出搜索引擎?





 工商网监
工商网监
评论