 存内计算技术工具链——量化篇
存内计算技术工具链——量化篇
本篇文章将重点讲述存内计算技术工具链之“量化”,我们将从面向存内计算芯片的深度学习编译工具链、神经网络中的量化(包括训练后量化与量化感知训练)、基于存内计算芯片硬件特性的量化工具这三个方面来对存内计算技术工具链的量化进行阐述。
一.深度学习编译工具链
工具链,英文名称toolchain,通常是指在软件开发或硬件设计中使用的一系列工具和软件,用于完成特定任务或流程。这些工具一般接连地使用,从而完成一个个任务,这也是“工具链”名称的由来。一般工具链的研发,大致与通用应用程序生命周期一致,分为五个阶段,如图1所示,图中包括每个阶段对应的工具等[1]。
而在AI芯片领域,工具链特指连接模型算法到芯片部署的端到端系列工具。面向存算一体芯片的深度学习编译工具链包括深度学习的算法设计、前端网络的模型转换、后端配置空间映射、存算一体的电路设计及各步骤的中间优化等模块;如今,面向传统芯片的深度学习编译工具链发展健全,而面向存算一体芯片的深度学习编译工具链在前端优化策略、后端空间映射等方面都仍有欠缺,这使得深度学习部署在存算一体芯片上移植性低、成本高,因此需要我们设计出能实现端到端的存算一体工具链及软硬件系统,而本文所述的“量化”,便是工具链中的重要工具之一。
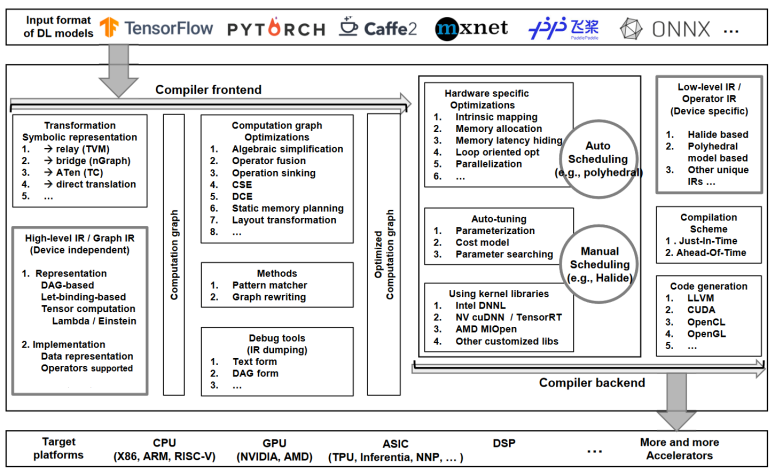 图2 深度学习编译器常用设计架构梳理
图2 深度学习编译器常用设计架构梳理
面向存内计算芯片的深度学习编译工具链通常包括量化、图优化、编译、调度、映射、模拟等工具:
(1)量化和优化工具:
在涉及到机器学习和深度学习模型的存内计算应用中,量化和优化工具变得尤为重要。这些工具可以帮助将模型减小到能够在内存中高效运行的大小,同时尽量保持模型的准确性。
TensorFlow Lite: 提供了一套工具,支持模型的量化,使其更适合在移动设备和边缘设备上运行。
PyTorch Mobile: 类似地,PyTorch提供了工具来优化和减小模型的大小,以便在资源受限的环境中运行。
(2)编译器与编程框架:
存内计算通常需要定制化的编译器,它能够理解特定存内计算硬件的特性,并将算法和程序转换为能在存储单元内执行的形式。
而编程模框架必须适应存内计算的特点,比如提供API或DSL(领域特定语言),允许开发者表达针对存内计算架构的并行性和数据局部性。
(3)映射与调度工具:
数据布局和计算任务在存储阵列中的映射至关重要,相应的工具应能智能地分配和管理数据在内存单元中的位置,优化计算效率和带宽使用。
调度工具则负责在不同时刻根据资源约束安排计算操作,确保有效利用存内计算硬件的并行性和容量。
(4)模拟与验证工具:
设计阶段需要用到高级和低级的模拟器来模拟存内计算芯片的行为,验证功能正确性以及性能预期。
验证工具帮助确保逻辑功能、功耗分析、时序收敛以及与主处理器或其他组件之间的交互都符合设计需求。
(5)开发和测试工具:
Jenkins, GitLab CI/CD: 这些持续集成和持续部署工具可以自动化存内计算应用的构建、测试和部署过程。
JUnit, PyTest: 提供了丰富的测试框架,帮助开发者编写和执行单元测试和集成测试。
二.神经网络中的量化
量化工具链可以推动工具链和存内计算技术的进一步发展,下面将介绍量化的基本知识,重点围绕神经网络量化进行讲解。
(1)量化的概念[3]
量化通常是指将连续值或较大范围的值简化为较小范围内的值的过程。在数字信号处理中,这通常指的是将模拟信号转换为数字信号的过程。在神经网络中,量化通常指的是将浮点数(如32位的Float)转换为低位数的表示(如8位或16位的Int)。
(2)量化的意义
近年来,深度学习技术在多个领域快速发展,特别是在计算机视觉领域,深度神经网络已在图像分类、目标检测等各种计算机视觉学习任务上展示了突破性结果。然而,这些方案通常是通过扩大神经网络规模来提高性能,需要花费更高的计算资源和内存需求。这导致大多数深度神经网络只能在图形处理器等高算力设备上运行推理,然而此类设备往往需要很大的功耗才能达到实时的推断效果。因此,开发轻量级的深度神经网络、进行模型量化对于计算资源有限的边缘设备来说至关重要。此外,深度学习技术的发展也带来了神经网络模型的快速发展,随之而来的就是模型参数的大幅度提升[4]。如图3所示,在Transformer架构兴起之后,模型规模呈指数级增长。神经网络的参数数量已经从Alexnet的6000万个增长到OpenAI GPT-3的1750亿个[5],对模型的存储空间和计算资源等提出了更高的需求。
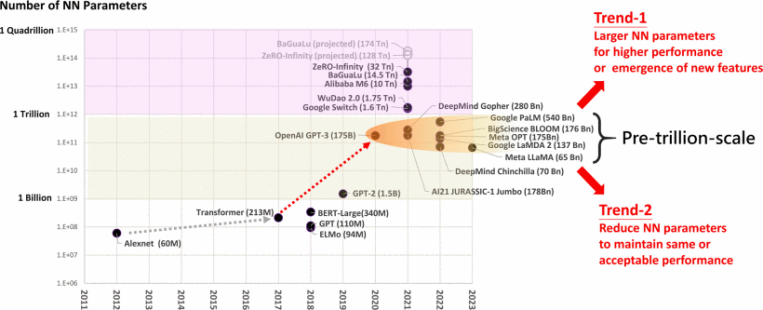 图3 神经网络模型参数随时间变化
图3 神经网络模型参数随时间变化模型量化技术可以在一定程度上缓解上述问题,即通过数据压缩,来降低模型的存储空间、内存占用和计算资源需求,从而提高模型的推理速度,丰富应用场景,量化已经成为深度神经网络优化的大方向之一。然而量化由于涉及到舍入或截断操作,会引入一定的误差。因此,量化技术的一个重要的挑战是在减少模型大小和保持模型精度之间进行折衷。
(3)模型量化的实例
TensorFlow[6]提供了两种量化方法,训练后量化(POT, Post Training Quantization)和量化感知训练(QAT, Quantization Aware Training)。
①训练后量化[7]
PTQ量化可以无需原始的训练过程就能将预训练的FP32网络直接转换为定点网络。这个方法通常不需要数据或者只需要很少的校准数据集,并且这部分数据通常可以非常容易的获得。量化过程中无需对原始模型进行任何训练,而只对几个超参数调整,从而以高效的方式去对预训练的神经网络模型进行量化。这使得神经网络的设计者不必成为量化方面的专家,从而让神经网络量化的应用变得更加广泛。
如图4所示,为标准的PTQ量化流程,包括跨层均衡(CLE)、添加量化器(Add Quantizers)、权重范围设置(Weight Range Setting)、自适应舍入(AdaRound)、偏差校正(Bias Correction)、激活范围设置(Activation Range Setting)等步骤,这个流程为许多计算机视觉以及自然语言处理模型及任务实现了有竞争力的PTQ结果。根据不同的模型,有些步骤可能是不需要的,或者其他的选择可能会导致相同或更好的性能。
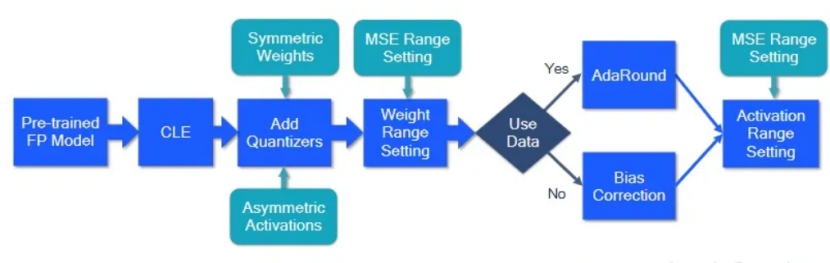 图5 标准PTQ量化流程
图5 标准PTQ量化流程
三.基于硬件特性的量化工具量化精度与硬件性能之间存在较强的耦合。当前的神经网络开发环境和深度学习算法已针对电脑端CPU、GPU、NPU、DSP等部分,以及传统意义上执行速度慢的浮点运算进行了广泛的优化,使得在电脑端设计神经网络变得更加简单,在电脑端训练、运行神经网络变得高效。但需要注意的是,PyTorch、TensorFlow等常用开发环境中默认的权重参数通常是Tensor Float 32格式,由于开发环境对该计算格式的优化,使得如果在电脑端训练BNN网络或整数类型网络,甚至需要额外编写加速整数运算的算法来加速整数运算[9]。而现有的量产存内计算芯片主要支持较低比特的整数形式数据计算和存储,因此为了保证网络和训练的高效,需要通过软件工具对训练得到的权重参数进行精度转换和调整,再部署到存内计算芯片中。
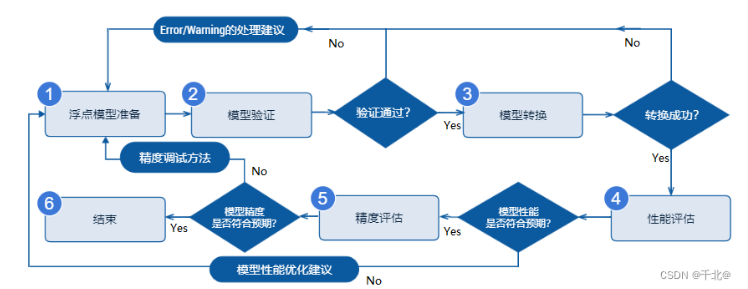 图6 量化工具链流程示意图
图6 量化工具链流程示意图神经网络依赖大量数据来发现规律,原则上可以容忍一定的计算误差。但是,由于神经网络的复杂性(例如深度网络),将权重参数量化为整数形式可能会导致推理结果与训练习到的规律显著不同。因此,在量化过程之后,通常需要对网络进行重新训练和权重参数的微调,以确保量化后网络的效果。
算法与硬件需要协同设计才能在不损失精度的情况下,充分发挥存内计算芯片的优势。存内计算芯片旨在突破计算和存储间的数据搬移瓶颈,加速神经网络中常见的乘累加运算,但神经网络中地其他运算则需要依靠外部电路进行处理。基于该特性,神经网络的设计需要在传统算法的基础上进行改进,例如通过重新设计数据结构和访问模式来减少不必要的数据移动,或者调整计算过程以适应芯片的特定能耗模式,最终实现量化感知的应用算法结构与训练框架,这一过程离不开量化工具链的支持。已有存内计算芯片厂商,如知存科技和后摩智能,建立了自己的开发者网站,并推出了开发者工具、量化工具链和开发板。例如知存科技的神经网络映射编译软件栈witin_mapper,后摩智能的后摩大道软件平台。这些工具的推出不仅为开发者提供便利,而且进一步促进了存内计算技术的发展。
[1] A glimpse into the exploding number of DevOps tools, which are filling the gap created by the waterfall model’s displacement.(Source:GrowthPoint Technology Partners)
[2] Li M, Liu Y, Liu X, et al. The deep learning compiler: A comprehensive survey[J]. IEEE Transactions on Parallel and Distributed Systems, 2020, 32(3): 708-727.
[3] 神经网络中的量化-简介 - 知乎 (zhihu.com).
[4] P. -Y. Chen, H. -C. Lin and J. -I. Guo, “Multi-Scale Dynamic Fixed-Point Quantization and Training for Deep Neural Networks,” 2023 IEEE International Symposium on Circuits and Systems (ISCAS), Monterey, CA, USA, 2023, pp. 1-5.
[5] B. -S. Liang, “AI Computing in Large-Scale Era: Pre-trillion-scale Neural Network Models and Exa-scale Supercomputing,” 2023 International VLSI Symposium on Technology, Systems and Applications (VLSI-TSA/VLSI-DAT), HsinChu, Taiwan, 2023, pp. 1-3.
[6] B. Jacob, S. Kligys, B. Chen, et al, “Quantization and training of neural networks for efficient integer-arithmetic-only inference,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 2704-2713.
[7] 再读《神经网络量化白皮书》- 0x03 训练后量化(PTQ) - 知乎 (zhihu.com).
[8] 再读《神经网络量化白皮书》- 0x04 训练时量化(QAT) - 知乎 (zhihu.com).
[9] Hubara I, Courbariaux M, Soudry D, et al. Binarized neural networks[J]. Advances in neural information processing systems, 2016, 29.
审核编辑 黄宇
-
神经网络
+关注
关注
42文章
4772浏览量
100798 -
机器学习
+关注
关注
66文章
8420浏览量
132680 -
深度学习
+关注
关注
73文章
5503浏览量
121187 -
量化
+关注
关注
0文章
34浏览量
2339 -
存内计算
+关注
关注
0文章
30浏览量
1381
发布评论请先 登录
相关推荐
探索存内计算—基于 SRAM 的存内计算与基于 MRAM 的存算一体的探究

论基于电压域的SRAM存内计算技术的崭新前景





 工商网监
工商网监
评论