 深度学习编译工具链中的核心——图优化
深度学习编译工具链中的核心——图优化
图优化
图优化的概念:
深度神经网络模型可以看做由多个算子连接而成的有向无环图,图中每个算子代表一类操作(如乘法、卷积),连接各个算子的边表示数据流动。在部署深度神经网络的过程中,为了适应硬件平台的优化、硬件本身支持的算子等,需要调整优化网络中使用的算子或算子组合,这就是深度学习编译工具链中的核心——图优化。
图优化是指对深度学习模型的计算图进行分析和优化的过程,通过替换子图(算子)为在推理平台上性能更佳的另一个等价子图、或优化数据流动,来提高模型推理的性能。图优化的出现很大程度上是因为算法开发人员不熟悉硬件,在算法层面上可以灵活表达的一种计算方式,在硬件底层和推理方式上可能存在显著的性能差异[1]。
为了更好的理解图优化,我们需要先了解几个图相关的基本概念。
(1)节点(Vertex):图的重要概念,也是图的基本单位,可以代表网络中的一个实体;
(2)边(Edge):图的重要概念,是连接两个节点的线,可以是有向的(箭头指向一个方向)或无向的。边可以表示顶点之间的关系,如距离、相似性等;
(3)权重(Weights):边的属性,表示从一个节点到另一个节点的“成本”(如距离、时间或其他资源消耗);
(4)路径(Path):节点的序列,其中任意相邻的节点都通过图中的边相连。
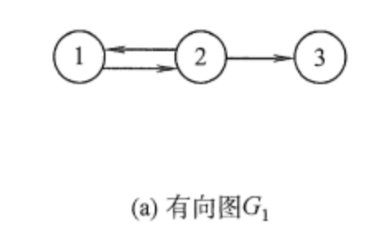
图 1 图的基本概念
基于这些基本的概念,我们可以将优化问题引入到图中来,比如最短路径问题、最小生成树问题、网络流问题、匹配问题等等;为了解决这些优化问题,我们也提出了一系列优化算法,比如Dijkstra算法、Kruskal算法、Ford-Fulkerson算法等等。
图优化的分类:
图优化问题通常根据解空间的连续性可分为“组合优化问题”和“连续优化问题”,其中前者的解空间是离散的,后者的解空间是连续的。
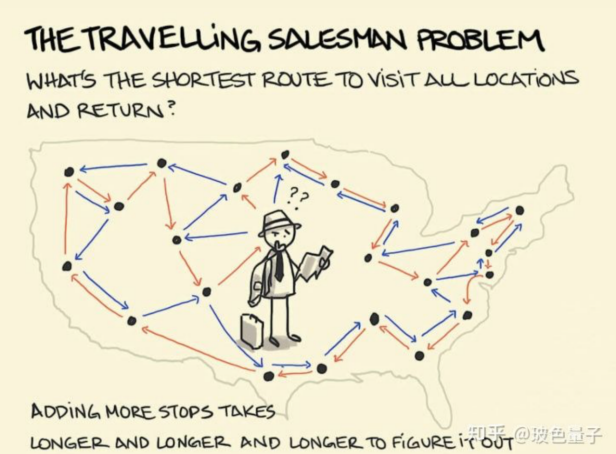
图 2 组合优化问题之“旅行商问题”[2]
(1)组合优化问题
组合优化问题涉及到在一个有限的、离散的可能解集合中寻找最优解的问题。这类问题的特点是解空间通常由一组离散的选择构成,解决问题的关键在于如何从这些离散的选择中找到满足约束条件的最优组合。
i.旅行商问题(TSP):旅行商问题要求找到一条经过图中每个顶点恰好一次并返回起点的最短可能路径。这是组合优化中的一个典型问题。
ii.图着色问题:给定一个图,目标是使用最少的颜色给图中的每个顶点着色,使得任何两个相邻的顶点颜色不同。这是一个经典的NP难(NP-hard)问题。
(2)连续优化问题
与组合优化不同,连续优化问题的解空间是连续的。这意味着问题的变量可以在某个连续的范围内取值。连续优化问题在工程、经济学、物理学等多个领域都有广泛应用。
i.最小二乘问题:在统计学和数据分析中,最小二乘问题是一种常见的连续优化问题,目标是找到一组参数,使得模型预测值和实际观测值之间的误差平方和最小。
ii.线性规划问题:虽然线性规划问题的解可能是离散的,但大多数情况下它被视为连续优化问题,因为问题的变量可以在连续范围内取值。线性规划问题的目标是在满足一组线性约束的条件下,最大化或最小化一个线性目标函数。
综上所述,在图优化的背景下,组合优化问题通常涉及到图的结构和图上的离散决策,例如路径选择、网络设计、资源分配等。而连续优化问题可能涉及到图的边权重的连续调整,或者在图表示的某种物理系统中寻找最优的连续状态。
图优化的策略:
传统意义上,图优化包含的具体策略有:
算子融合,将多个操作融合为一个复合操作,减少内存访问次数和中间数据的存储需求;
常量折叠,在编译时期预先确定结果的表达式,减少运行时的计算量;
内存复用,识别和优化计算图中的内存使用,减少内存分配和释放操作;
数据布局转换,根据硬件特性调整数据的存储格式,提高内存访问效率;
算子集并行化,识别可以并行执行的操作,利用硬件处理单元的并行计算能力;
子图替换/合并,如图3所示,将计算图中的某些算子替换为在转为硬件优化的版本或效率更高的实现方式。
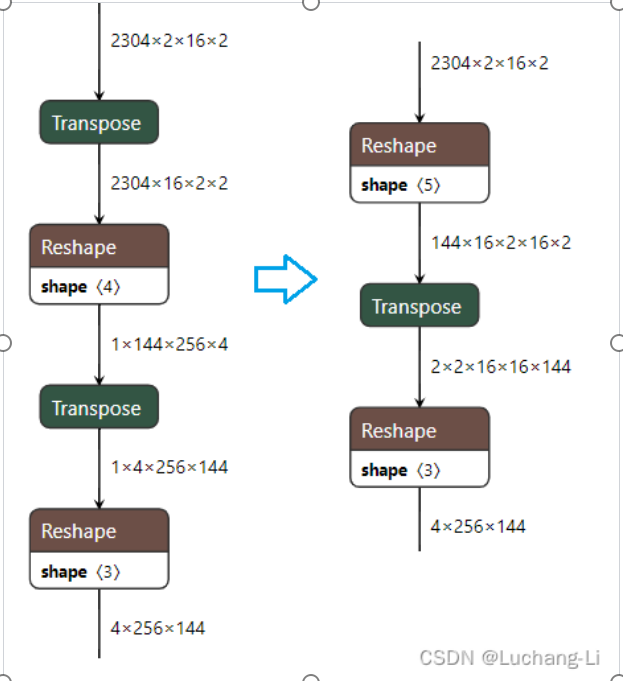
图3 深度神经网络模型中的子图合并示意图
对于采用存算一体架构设计的硬件而言,图优化需要特别考虑减少数据移动。具体到图优化策略中,考虑到存算一体加速乘累加的特点及硬件资源,主要考虑的图优化策略有:
(1)子图替换/合并,由于存算一体架构芯片支持的加速算子类型有限,如果深度学习模型中使用了不受支持的算子,则必须被替换;
(2)数据局部性优化,确保负责计算卷积的存算一体核心所存储的权重在一次计算中不需要重新写入,依靠数据流动到存储不同权重的核心进行计算,同时确立统一的数据存储格式,避免计算过程中为对其存储数据付出额外的时间。
图优化的应用场景:
图优化的应用场景主要体现在优化神经网络以匹配硬件或适应需求。图优化针对特定硬件优化神经网络,减少模型的硬件需求、使用针对硬件优化的算子,以在终端设备部署神经网络模型;针对CPU、GPU、FPGA等不同平台进行特定优化,保证模型的可移植性。图优化针对特定需求,优化模型吞吐量,提升云端模型服务单位时间可处理的访问次数;降低模型处理的延时,以更快速地处理高分辨率视频、满足音频处理的实时性需求。
工具链的图优化
图优化和其他网络优化方法共同支持深度学习模型的开发、训练、优化、部署和执行过程,是深度学习工具链的重要组成部分。下面我们将从文献研究和企业产品两个方面介绍工具链图优化的发展现状。
1.文献研究相关:
图优化有许多经典算法,以下列举了几个经典算法及其参考文献,这些图优化经典算法为工具链的图优化提供了具体的思路与方案。
(1)Dijkstra算法(最短路径问题):用于寻找图中某一节点到其他所有节点的最短路径,特别适用于带权重的有向图和无向图[3]。
(2)Kruskal算法(最小生成树问题):该算法用于在一个加权连通无向图中寻找最小生成树,即找到一个边的子集,使得这些边构成的树包括图中的所有节点,并且树的总权值尽可能小[4]。
(3)Ford-Fulkerson算法(最大流问题):该算法用于计算网络流中的最大流,通过不断寻找增广路径来增加从源点到汇点的流量,直到无法再增加为止[5]。
(4)Hungarian算法(二分图最大匹配问题):该算法用于解决二分图的最大匹配问题,特别是在工作分配等应用中,寻找最优匹配方式,使总成本最低[6]。
2.企业产品相关:
(1)英伟达(NVIDIA)[7]
i.产品与技术:
英伟达是全球领先的 GPU 龙头厂商,所生产的GPU被广泛应用于图计算,尤其是在需要大量并行处理的场景中。CUDA(Compute Unified Device Architecture)是NVIDIA推出的一个并行计算平台和编程模型,它允许软件开发者和软件工程师使用C语言等高级编程语言来编写程序。
ii.图优化工具链:
NVIDIA提供了CUDA图分析库(cuGraph),这是一个基于GPU加速的图分析算法库,旨在处理大规模图形数据。cuGraph提供了一系列优化的图算法,包括最短路径、PageRank、个性化PageRank、最大流和最小割等,为工具链的图优化提供新的思路。通过利用GPU的并行处理能力,cuGraph能够显著加速图计算任务。
(2)谷歌(Google)
i.产品与技术:
谷歌开发了TPU(Tensor Processing Unit),专门为深度学习应用设计,其高效的矩阵运算能力也可以被应用于图计算场景,尤其是在图神经网络(GNN)等领域。
ii.图优化工具链:
TensorFlow是Google开发的一个开源机器学习框架,它支持广泛的机器学习任务,包括图计算。TensorFlow可以利用TPU进行加速,从而提高图计算的效率。此外,Google也在研究如何优化图算法的执行,如图4所示,为GraphX的架构图,通过GraphX在图顶点信息和边信息存储上进行优化,使得图计算框架性能得到较大提升,接近或到达 GraphLab 等专业图计算平台的性能,可以在其大数据处理工具Apache Spark上进行图处理[8]。
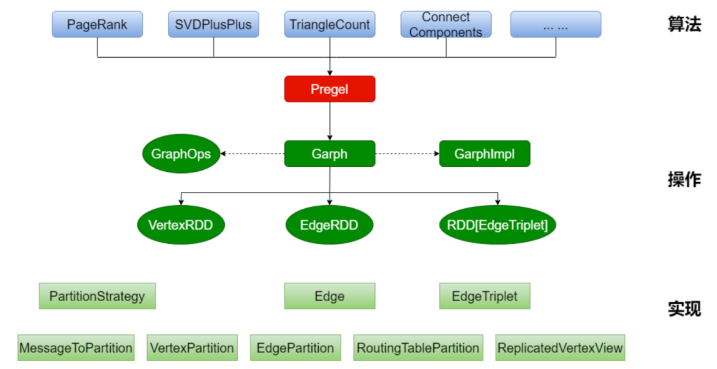
图 4 GraphX架构图[8]
(3)Graphcore[9]
i.产品与技术:
Graphcore公司专注于为机器学习和AI应用开发创新的处理器,称为智能处理单元(IPU)。IPU设计目标是提高图计算的效率,其架构优化了复杂的数据结构处理,特别是图形数据结构,这使得其非常适合执行图神经网络和其他图计算任务。
ii.图优化工具链:
Graphcore提供了Poplar软件开发工具链,这是一个专为IPU设计的软件堆栈。Poplar包含了一系列图计算库和工具,支持开发者高效地在IPU上实现和运行图计算任务,从而充分发挥IPU在图处理上的优势,专门针对AI和图计算任务提供了优化的解决方案,为工具链的图优化提供了新的思路。
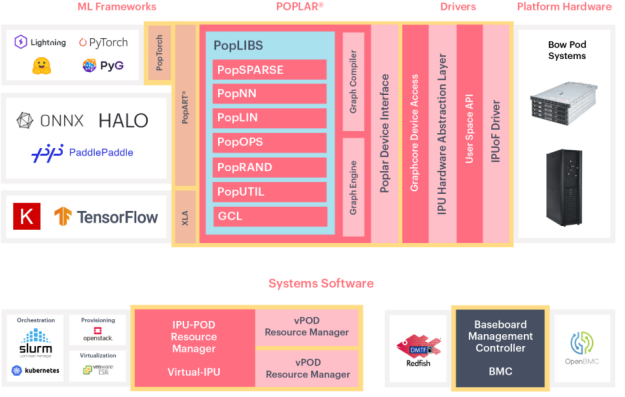
图 5 Poplar整体架构示意图[9]
知存科技[10]
i.产品与技术:
知存科技是全球领先的存内计算芯片企业。公司针对AI应用场景,在全球率先商业化量产基于存内计算技术的神经网络芯片,已有WTM1001、WTM2101、WTM-8等存算一体芯片。
ii.图优化工具链:
如图6所示,WITIN_MAPPER是知存科技自研的用于神经网络映射的编译软件栈,可以将量化后的神经网络模型映射到WTM2101 MPU加速器上,是一种包括RISC-V和MPU的完整解决方案。WITIN_MAPPER工具链可以完成算子和图级别的转换和优化,将预训练权重编排到存算阵列中,并针对网络结构和算子给出存算优化方案,同时将不适合MPU运算的算子调度到CPU上运算,实现整网的调度,让神经网络开发⼈员高效快捷的将训练好的算法运行在WTM2101芯片上,极大缩短模型移植的开发周期并提高算法开发的效率。
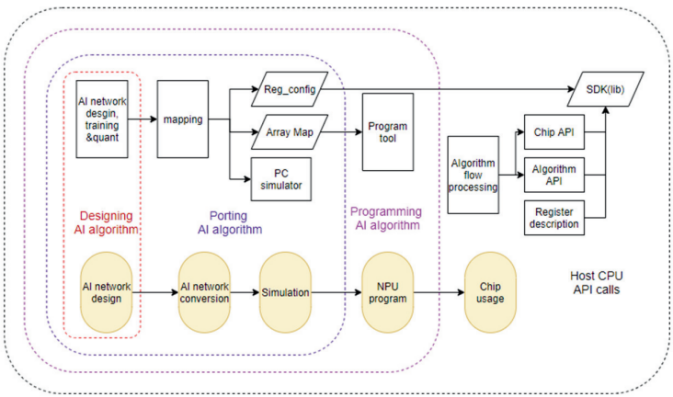
图 6 WITIN_MAPPER工具链软件架构图[10]
三.未来展望
当前工具链的图优化研究相对较多,然而存算一体编译工具链的图优化仍处于起步阶段,面临着许多科学与技术问题。此外,由于存算一体架构规模有限,目前存算一体编译工具链的图优化主要是针对硬件的适配,通过层间的调度优化,提高硬件的利用率等。为了解决以上问题,科研工作者仍需进行不断的探索。
同时,随着人工智能技术的持续发展,神经网络的参数数量已经从Alexnet的6000万个增长到OpenAI GPT-3的1750亿个,参数量以指数级别增长,人工智能已进入大模型时代,存算一体编译工具链技术的研究也逐渐增多。在大模型时代,存算一体工具链的图优化将会更多地涉及整网的优化调度,从而极大地加快模型的部署与开发,相信更加成熟全面的存算一体工具链图优化技术指日可待!
参考文献:
[1] Luchang-Li:深度学习性能优化之图优化(blog.csdn.net).
[2] 知乎@玻色量子.
[3] E. W. (1959). A note on two problems in connexion with graphs. Numerische Mathematik, 1(1), 269-271.
[4]J. B. (1956). On the shortest spanning subtree of a graph and the traveling salesman problem. Proceedings of the American Mathematical Society, 7(1), 48-50.
[5]L. R., & Fulkerson, D. R. (1956). Maximal flow through a network. Canadian Journal of Mathematics, 8, 399-404.
[6]H. W. (1955). The Hungarian method for the assignment problem. Naval Research Logistics Quarterly, 2(1-2), 83-97.
[7]机器学习和分析 | NVIDIA 开发者.
[8]Spark GraphX_存储-CSDN博客.
[9]Poplar® 软件 (graphcore.ai).
[10]WITMEM 2023.ALL RIGHTS,知存科技.
审核编辑 黄宇
-
神经网络模型
+关注
关注
0文章
24浏览量
5666 -
编译
+关注
关注
0文章
666浏览量
33213 -
深度学习
+关注
关注
73文章
5527浏览量
121878
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论