 存内计算芯片研究进展以及应用-以基于Nor Flash的卷积神经网络量化以及部署
存内计算芯片研究进展以及应用-以基于Nor Flash的卷积神经网络量化以及部署

@[toc]
如果我能看得更远一点的话,那是因为我站在巨人的肩膀上。 —牛顿
存内计算的背景
存内计算是一种革新性的计算范式,旨在克服传统冯·诺依曼架构的局限性。随着大数据时代的到来,传统的冯·诺依曼架构由于处理单元和存储器互相分离,带来了巨大的延时和能耗,承受着高昂的数据传输成本,即所谓的“冯·诺依曼瓶颈”。为了解决这个问题,存内计算应运而生。
存内计算架构在功能和物理上合并了数据处理和存储单元,在数据存储的位置即处理数据,在器件层面以原位的方式执行计算。这种方式可以避免频繁的数据通信,从而减少相应的延时和能耗。存储器是存内计算的核心器件,这种架构的需求同时也促进了新型非易失性存储器(NVM)的发展。
早期,由于大数据、人工智能、云计算等需要大量数据处理的应用还没展开,存内计算仅仅停留在理论研究阶段,并未实现实际的应用。然而,近年来随着这些应用的兴起,人们再次关注存内计算的研究。世界知名的IC企业和高校都推出了存内计算的架构。
存内计算的研究还涉及模拟式忆阻器等重要器件,这些器件可以支持各种模拟计算应用,包括人工神经网络(ANN)、机器学习、科学计算和数字图像处理等,展现出了突出的潜力。
首个存内计算开发者社区-CSDN存内计算
全球首个存内计算社区创立,涵盖最丰富的存内计算内容,以存内计算技术为核心,绝无仅有存内技术开源内容,囊括云/边/端侧商业化应用解析以及新技术趋势洞察等, 邀请业内大咖定期举办线下存内workshop,实战演练体验前沿架构;从理论到实践,做为最佳窗口,存内计算让你触手可及。
传送门:[https://bbs.csdn.net/forums/computinginmemory?category=10003]
社区最新活动存内计算大使招募中,享受社区资源倾斜,打造属于你的个人品牌,点击下方一键加入。
[https://bbs.csdn.net/topics/617915760]
首个存内计算开发者社区,0门槛新人加入,发文享积分兑超值礼品;
成为存内计算大使,享受资源支持与激励,打造亮眼个人品牌,共同引流存内计算潮流。
存算一体技术发展历程
存算一体技术,也称为近存计算与存内计算,其概念最早在1969年被提出。这种技术旨在克服传统冯·诺依曼架构的局限性,通过在存储器中直接进行计算,减少数据传输的开销。然而,早期由于缺乏大数据处理的应用需求以及芯片制造成本高昂,存算一体技术主要停留在研究阶段。
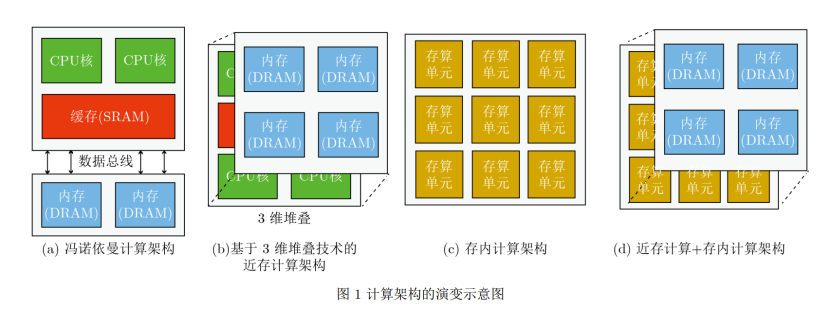
计算架构的演变示意图如下: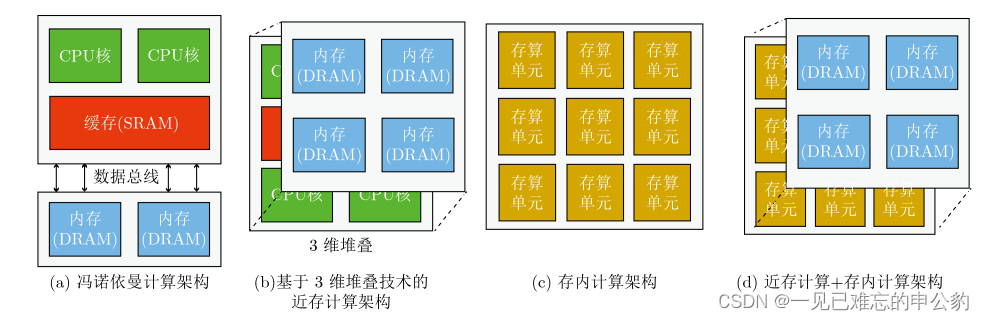
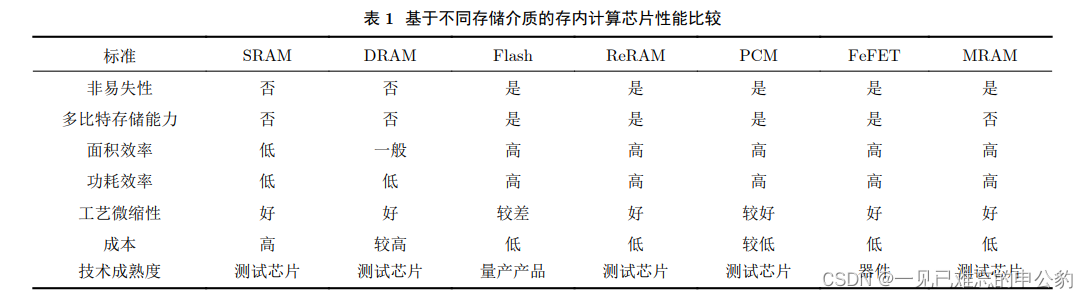
随着技术的发展,尤其是摩尔定律的逐渐失效和大数据应用的驱动,存算一体技术重新受到关注。2015年以来,这一领域的研究取得了显著进展,涌现出了一系列相关研究工作,包括基于SRAM、DRAM、Flash、ReRAM、PCM、FeFET、MRAM等各种存储介质的研究。
存内计算芯片8 bit精度运算测试结果如下图: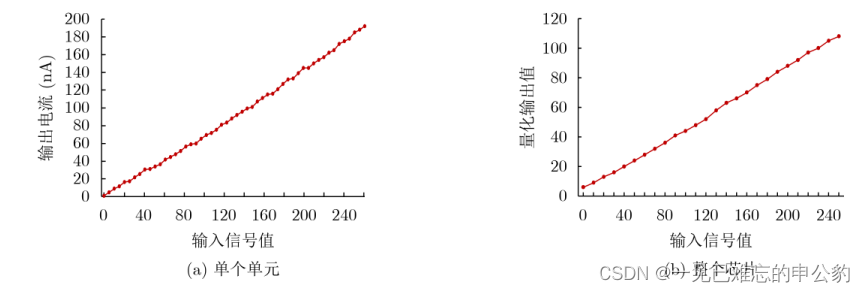
存算一体技术被认为是先进算力的代表性技术之一。在学术界和工业界,许多知名机构都在积极开展存算一体芯片或系统原型的研究,如苏黎世联邦理工学院、加利福尼亚大学圣巴巴拉分校、英伟达、英特尔、微软、三星等。这些研究工作不仅在学术期刊上发表了一系列研究成果,也在国际会议上得到了广泛关注。
基于不同存储介质的计算架构演变图如下: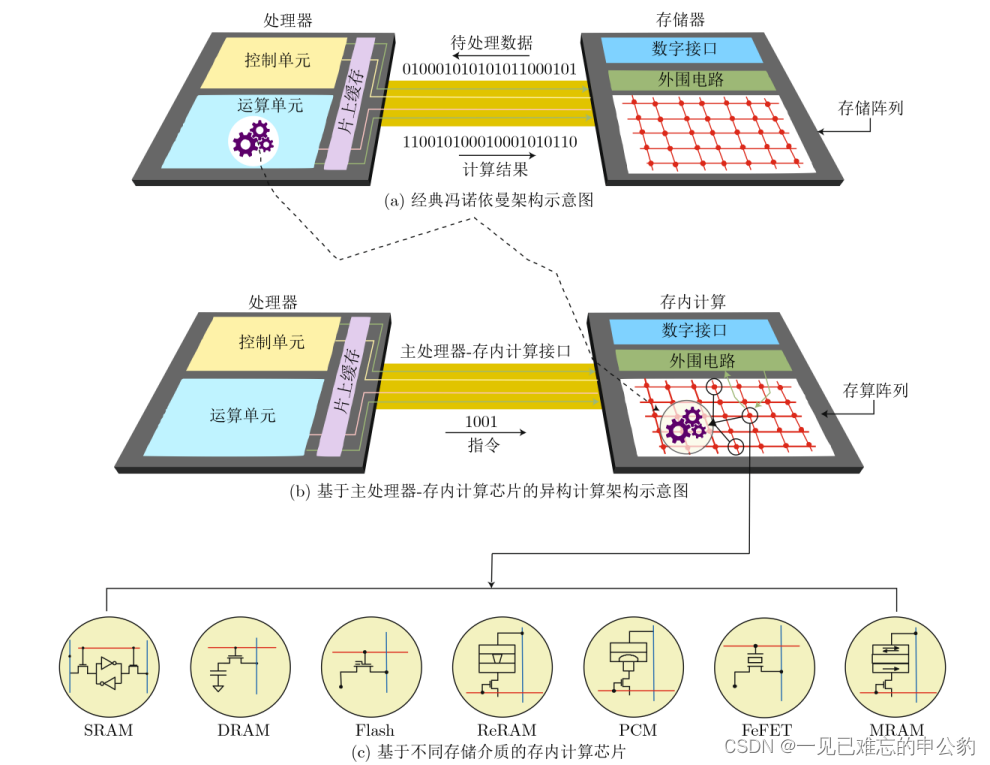
存算一体技术的发展历程表明,尽管早期受到技术和成本等方面的限制,但随着大数据和人工智能等应用的兴起,这一领域的研究已经取得了显著进展,并被认为是未来计算架构的重要方向之一。
存内计算芯片研究现状
存内计算芯片可以根据计算范式和存储介质的不同进行分类。主要分为模拟式和数字式两种,根据存储介质的不同又可分为基于传统存储器和基于新型非易失性存储器两种。
- 计算范式分类:
- 存储介质分类:
在当前的研究工作中,许多存内计算芯片综合了模拟和数字两种运算方式,并且在存储介质的选择上也有很多不同的组合。其中,基于NOR Flash和基于SRAM的存内计算芯片距离产业化较近,已经在一些应用中取得了一定的进展。
SRAM存内计算
基于SRAM的存内计算芯片通常以典型的6T(6-Transistor)基本单元为基础。由于SRAM是二值存储器,它可以用于二值乘累加运算,这等效于同或累加运算。这使得它适用于二值神经网络运算。核心思想是将网络权重存储于SRAM单元中,激励信号从字线给入,最终利用外围电路实现同或累加运算。结果可以通过计数器或模拟电流/电压输出。
如果要实现多比特精度运算,通常需要多个单元进行拼接,这不可避免地会带来面积开销。对6T基本单元的一个简单修改是将字线进行拆分。此外,为了解决读写干扰问题,可以采用8T基本单元,但这明显增加了布局面积,如图所示。
基于SRAM的存内计算技术由于其工艺成熟度与微缩性良好,受到业界的高度关注。在近几年的ISSCC(国际固态电路大会)上,连续报道了多篇相关论文。例如,2021年,存内计算共有两个分论坛,共收录8篇论文,其中5篇是关于SRAM存内计算芯片的。在2022年的ISSCC中,北京大学提出了一种基于动态逻辑且无模数转换器的SRAM存内计算芯片[42]。SRAM存内计算技术的主要应用难点在于在保证运算精度的前提下,实现高算力和小面积。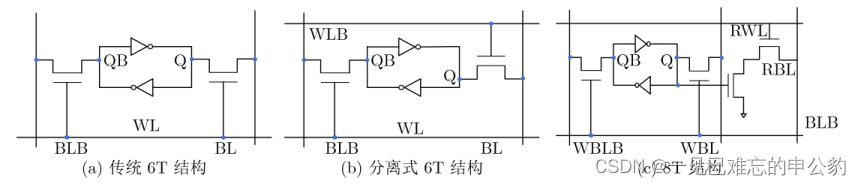
DRAM存内计算
基于DRAM的存内计算芯片的层次结构通常分为阵列、子阵列和单元。一组阵列由若干子阵列和用于读写操作的相关外围电路组成,而子阵列则包含若干行1T1C(1-Transistor-1-Capacitor)单元、感知放大器和本地解码器。其基本原理是利用DRAM单元之间的电荷共享机制。图4展示了一种典型的实现方案,当多行单元同时被选通时,不同单元之间因为存储数据的不同会产生电荷交换共享,从而实现逻辑运算。
然而,DRAM存内计算方案面临两个主要难点。首先,由于DRAM本身为易失性存储器,计算操作会破坏数据,因此需要在每次运算后进行刷新,这会带来额外的功耗问题。其次,在实现大阵列运算时,难以保证运算精度,这可能在一定程度上影响其应用的可靠性。
尽管存在这些难点,基于DRAM的存内计算方案仍然具有潜在的优势,包括其相对较低的成本和高度集成的能力。不断的研究和创新可能有助于解决这些难题,使其更加适用于特定的应用场景。
ReRAM/PCM存内计算
ReRAM(电阻随机存储器)/PCM(相变存储器)存内计算的基本原理是利用存储单元的模拟多比特特性,通过基于电流/电压的欧姆定律与基尔霍夫定律进行矩阵乘加运算。主要有两种实现方案,分别是1T1R(1-transistor-1-resistance)结构和交叉阵列结构,如图所示。
- 1T1R结构: 使用1T1R结构,即一个晶体管和一个电阻组成一个存储单元。这种结构通过控制电流或电压,可以实现对存储单元的状态调控,进而进行计算操作。
- 交叉阵列结构: 利用ReRAM能够实现大规模交叉点阵列,将存储单元排列成交叉的结构。这样的阵列结构可以进行并行计算,提高计算效率。
自2008年ReRAM首次实验发现以来,基于ReRAM的存内计算研究不断涌现。特别是在2020年,清华大学研发了基于多个ReRAM阵列的存内计算系统,该系统在手写数字集上的识别准确率达到96.19%,与软件的识别准确率相当,证明了存内计算架构全硬件实现的可行性。测试芯片如图所示。
尽管ReRAM存内计算技术具有广阔的应用潜力,但目前仍面临一些挑战。其中主要难点包括工艺尚不够成熟、多比特精度实现较为困难以及一致性和鲁棒性较差。随着技术的不断发展,这些问题有望在未来得到解决,推动ReRAM存内计算技术的进一步应用和成熟。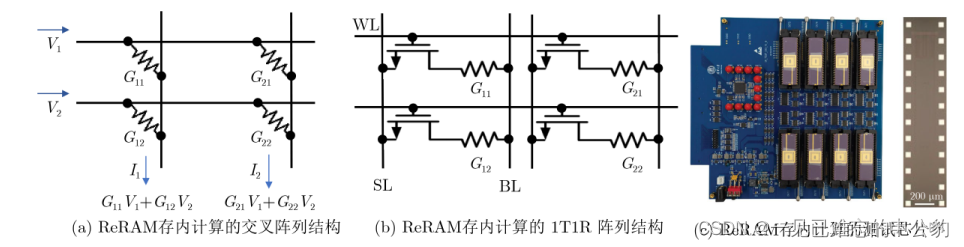
MRAM存内计算
MRAM(磁性随机存储器)存内计算主要有两种技术方案:
- 基于读/写操作的数字式存内计算: 早期的MRAM存内计算多采用数字式方案。例如,在2015年,日本东北大学提出了一种基于读操作实现多种布尔逻辑的方案,并通过实验验证获得了48.3%的能效提升。此外,在2019年,北京航空航天大学提出了基于单次写操作的数字式MRAM存内计算方案,实现计算结果原位存储的同时降低了延时和功耗。
- 基于基尔霍夫电流定律和欧姆定律的模拟式存内计算: 近年来,随着计算范式、器件和电路的创新,MRAM模拟存内计算得到了迅速发展。在2021年,美国普林斯顿大学通过电路级优化,实现了第一款基于STT-MRAM的模拟存内计算硬核。而在2022年,韩国三星公司在Nature期刊上发表了基于电阻累加方案的MRAM模拟存内计算芯片原型,并取得了最高405 TOPS/W的能效比。该芯片的阵列布局图、显微图和结构如图所示。
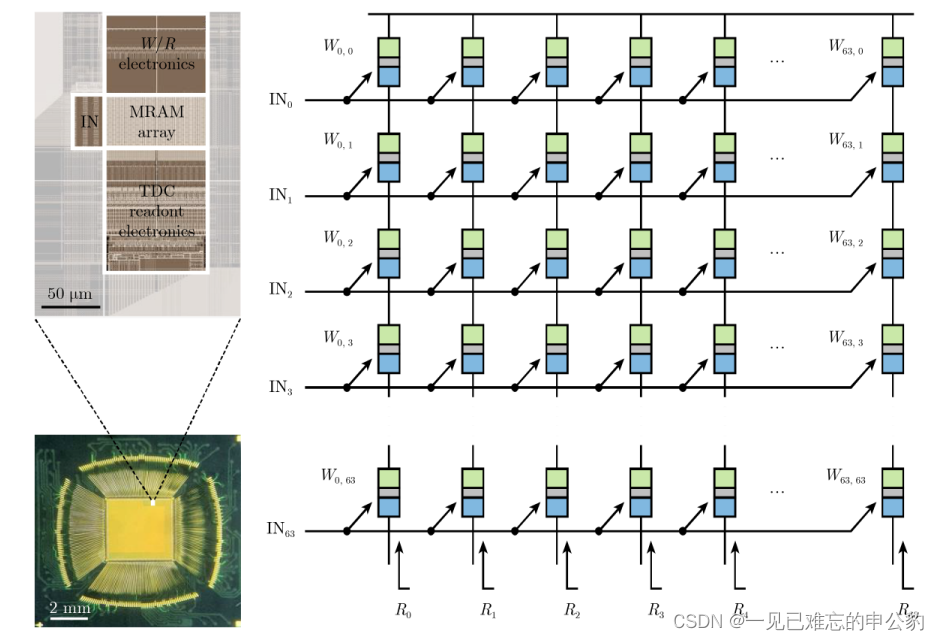

模拟式存内计算在MRAM中的难点主要体现在器件的阻值相对较小(约几千欧姆)以及高低阻值比率相对较小(约250%),这使得实现多比特精度较为困难。然而,通过多层次的创新突破,MRAM模拟存内计算技术在最近取得了显著的进展。
NOR Flash存内计算
基于NOR Flash的存内计算技术原理与ReRAM相似,如图所示。目前,NOR Flash存内计算芯片技术相对较成熟,并已于2021年实现量产。美国的Mythic和国内的知存科技都推出了基于NOR Flash的存内计算芯片产品。
- Mythic M1076芯片: Mythic推出了M1076芯片,如图所示。这款芯片采用NOR Flash存内计算技术,具有嵌入式AI推理能力,适用于各种端侧设备,如摄像头、传感器和边缘计算设备等。
- 知存科技WTM2101芯片: 知存科技推出了WTM2101量产SoC芯片,如图所示。该芯片基于NOR Flash存内计算技术,具有边缘AI计算能力,适用于智能摄像头、智能家居等场景,实现了高效的本地AI处理。
这些NOR Flash存内计算芯片的推出表明该技术已经进入商业化阶段,成为实际应用的一部分。这种技术的优势在于其相对成熟的制造工艺和较低的成本,使其成为在端侧设备中进行AI计算的有力选择。
基于 NOR Flash 的卷积神经网络量化
基于 NOR Flash 阵列实现模拟乘法的原理结合浮栅单元的存储特点,以实现 4 位(即网络正向传播时只存在精度为 4 位的计算)的卷积神经网络模型,采用基于动态阈值调整的量化方法。这个方法主要涉及神经网络量化时的参数(权值 w 和偏置 b)以及激活函数的不同量化方案。
- 参数量化: 在训练过程中,采样浮点参数的阈值多次,以改变缩放因子,使得量化的映射更加精确。通过动态调整阈值,可以更好地适应不同参数的取值范围,提高量化的准确性。
- 激活函数的量化: 针对激活函数,引入可学习的参数,在 ReLU(Rectified Linear Unit)激活函数中,使激活的量化可以根据实际情况在反向传播过程中不断更新,以提高量化精度。这样的调整可以根据网络的训练过程中动态变化的激活值来调整量化的参数,以适应不同的输入情况。
这种基于 NOR Flash 阵列和浮栅单元的量化方法可以在训练过程中动态地调整阈值和参数,以适应不同的神经网络结构和输入数据的变化,提高量化的精度,同时降低模型的计算和存储开销。这种动态的量化方法有望在实际的卷积神经网络模型中取得更好的性能。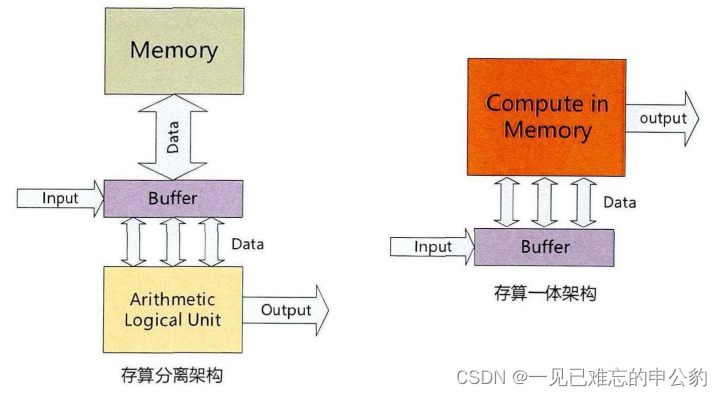
卷积神经网络基本结构
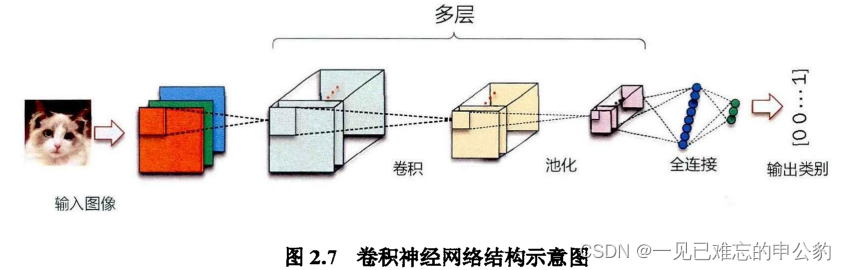
卷积神经网络(Convolutional Neural Network,CNN)是一类专门用于处理具有类似网格结构的数据的深度学习模型,特别适用于图像和视频的处理。以下是卷积神经网络的基本结构:
- 输入层(Input Layer): 输入层负责接收原始数据,通常是图像的像素值。每个输入节点对应图像中的一个像素或一组像素。
- 卷积层(Convolutional Layer): 卷积层是卷积神经网络的核心部分。它通过使用卷积操作从输入数据中提取特征。卷积操作是通过滤波器(也称为卷积核)在输入数据上滑动并执行元素乘法和求和来实现的。这有助于捕捉输入中的局部特征,同时减少网络参数的数量。
- 激活函数层(Activation Layer): 卷积操作的结果通常通过一个激活函数进行非线性变换,以引入网络的非线性特性。常见的激活函数包括ReLU(Rectified Linear Unit)和Sigmoid等。
- 池化层(Pooling Layer): 池化层用于减小特征图的空间维度,减少计算复杂度并使网络对平移更加不变。常见的池化操作包括最大池化和平均池化。
- 全连接层(Fully Connected Layer): 全连接层负责整合之前层的信息,并将其映射到输出层。每个节点与前一层的所有节点相连,引入了全局信息。
- 输出层(Output Layer): 输出层负责生成网络的最终输出,通常对应于问题的类别数。对于分类问题,输出层通常使用softmax激活函数,对每个类别产生一个概率分布。
上述结构构成了一个基本的卷积神经网络的层次结构。在实际应用中,人们通常会堆叠多个这样的层次,形成深层的网络结构,以提高模型的学习能力和表示能力。深层卷积神经网络已经在图像识别、目标检测、语音识别等领域取得了显著的成果。
一维卷积: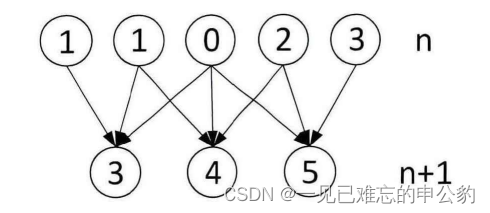
二维卷积: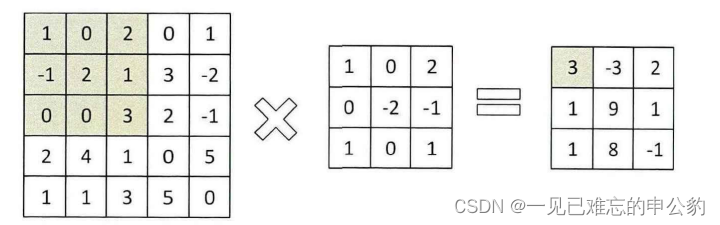
三维卷积: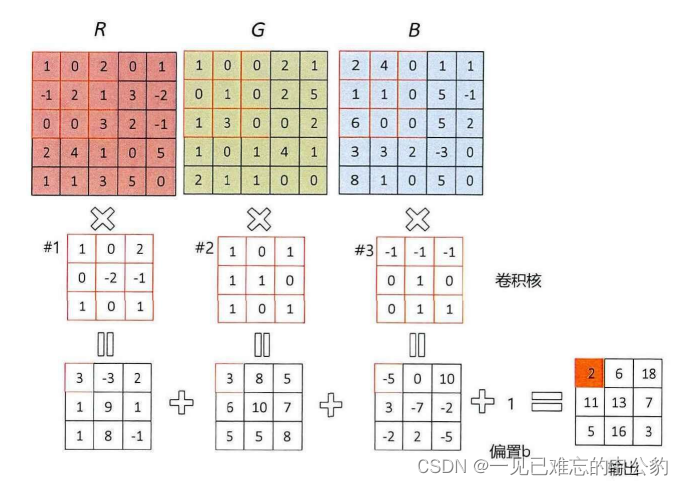
卷积神经网络量化方法研究
基于动态阈值调整的量化方法,主要针对神经网络中的参数和激活值的量化。以下是该方法的主要步骤:
- 参数量化: 针对模型的权重(参数),不断采样浮点参数,并在反向传播过程中更新浮点参数的阈值范围。通过这种方式,动态地调整映射系数,使得参数的量化能够更好地适应模型的变化。
- 激活量化: 针对激活值,引入可学习的截断参数。在激活函数中,通过学习可调整的截断参数,使激活函数能够在训练过程中不断学习,并确定最佳的截断位置。这有助于提高激活值的量化精度。
- BN层处理: 针对批量归一化(Batch Normalization,BN)层的浮点计算过程,提供相应的处理方案。BN层通常用于神经网络的训练,而在量化神经网络中,需要特殊的处理方式来实现全整数计算。
该方法通过动态调整参数的映射系数和引入可学习的截断参数,实现了对神经网络的全整数计算的量化。这有助于减小神经网络在推理阶段的计算复杂度,适应特定硬件或嵌入式设备的需求。
这些措施的目标是在神经网络的训练过程中,通过动态调整阈值和引入可学习的参数,优化量化的精度,提高在反向传播中的更新效果。文本还提到了对BN层和其他激活函数的相应处理,以确保整个神经网络在量化过程中能够保持良好的性能。
实验及结果分析
在CIFAR-10数据集上评估动态阈值调整算法的性能。
- 数据集选择理由: 选择CIFAR-10数据集的原因有三点:首先,相对于MNIST数据集,CIFAR-10包含RGB三通道彩色图像,更符合当今卷积神经网络的应用场景;其次,相对于ImageNet数据集,CIFAR-10训练可以使用十几层的神经网络,这提高了在边缘设备上部署这些模型的可行性;最后,尽管CIFAR-10只有10个类别,但由于数据集本身的训练难度,通过更改Softmax输出层来实现迁移学习,从而完成更多物品的分类识别。
- CIFAR-10数据集描述: CIFAR-10数据集包括60000张大小为32x32的彩色图像,分为10个类别,每个类别有6000张图像。
- 训练集和测试集划分: 数据集中的50000张图像用于训练,10000张用于测试。
对于训练难度和迁移学习的考虑使得CIFAR-10数据集成为评估动态阈值调整算法性能的有力选择。
Res18模型精度如下图: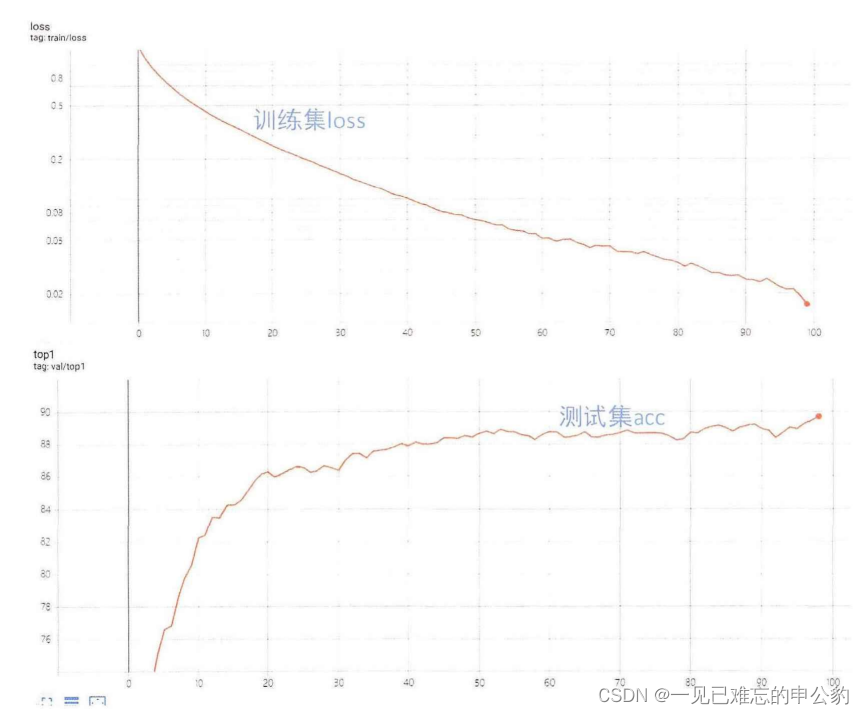
使用CIFAR-10数据集训练的全精度AlexNet、VGG16和ResNet-18模型在测试集上的分类准确率。
- 训练结果: 本文使用CIFAR-10数据集训练了AlexNet、VGG16和ResNet-18模型,它们在测试集上的分类准确率分别为90.07%,91.65%,93.23%。
- 与其他工作的对比: 文中对比了其他相关工作的结果。其中,引用的文献1使用AlexNet网络在CIFAR-10数据集上训练,最终分类准确率为89%。文献2使用VGG16网络和ResNet-18网络在CIFAR-10数据集上分别达到90.92%和92.32%的准确率。文献3使用ResNet-110在CIFAR-10数据集上训练,最终分类准确率为93.57%。本文的结果与这些工作相似,但文献3中的模型深度明显大于本文的模型。
本文的模型在CIFAR-10数据集上达到了竞争性的分类准确率。
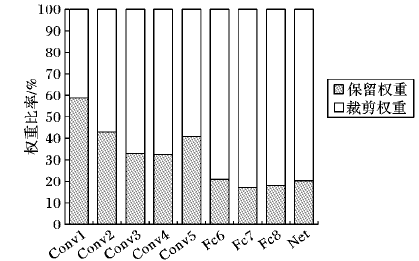
数据结果对比: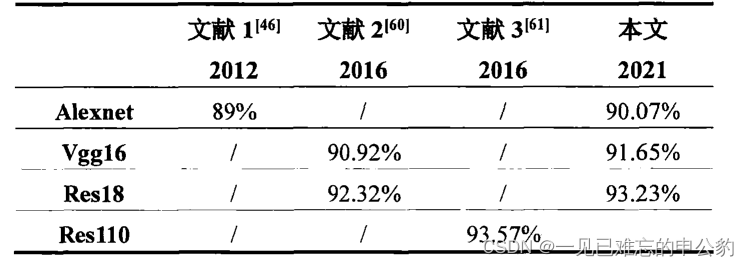
量化结果对比: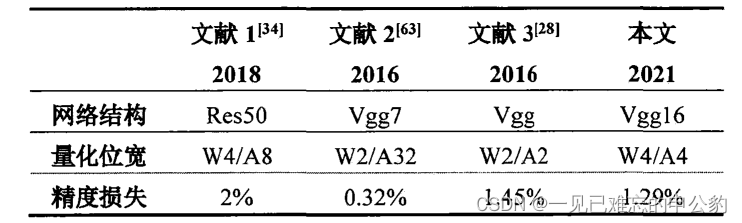
心得
经过对动态阈值量化算法的实验验证,包括实验平台及相关设置、在CIFAR-10数据集上对参数和激活层进行的验证以及对AlexNet、VGG16和ResNet-18这三种卷积神经网络进行4位量化的结果。
在CIFAR-10数据集上,对动态阈值量化算法进行了验证,分别针对模型参数和激活层。实验结果表明,该算法在减小量化模型精度损失方面取得了成功,将损失控制在1.5%以内。
对AlexNet、VGG16和ResNet-18这三种卷积神经网络进行了4位量化的实验。结果表明,动态阈值量化算法在这些网络上能够将量化模型的精度损失有效地降低到1.5%以内。
参考文献
1.知存科技
2.中国移动研究院
3.电子与信息学报—存内计算芯片研究进展及应用
4.中科院—基于NorFlash的表积神经网络量化
文献内容极多,本文基于众多文献经过仔细仔细分析总结而来。支持存内计算发展。
审核编辑 黄宇
-
数据集
+关注
关注
4文章
1242浏览量
26286 -
卷积神经网络
+关注
关注
4文章
375浏览量
12962 -
存算一体
+关注
关注
1文章
122浏览量
5254 -
存内计算
+关注
关注
0文章
35浏览量
1679
发布评论请先 登录
卷积神经网络如何使用
轻量化神经网络的相关资料下载
卷积神经网络一维卷积的处理过程
卷积神经网络模型发展及应用
面向“边缘”应用的卷积神经网络如何进行量化与压缩详细方法



评论