 请问移动端生成式AI如何在Arm CPU上运行呢?
请问移动端生成式AI如何在Arm CPU上运行呢?

2023 年,生成式人工智能 (Generative AI) 领域涌现出诸多用例。这一突破性的人工智能 (AI) 技术是 OpenAI 的 ChatGPT 和 Google 的 Gemini AI 模型的核心,能够根据用户输入的文本提示生成文本、图像,甚至音频内容,其有望简化工作流程和推动教育发展。这是不是听起来相当震撼呢?
而随着生成式 AI 技术下沉到我们钟爱的消费电子设备上,其未来又将会如何发展?答案是,在边缘移动设备上部署生成式 AI。
在本文中,我们将展示大语言模型 (LLM) 作为一种生成式 AI 推理形式,如何在基于 Arm 技术的多数移动设备上运行。此外我们还将介绍,鉴于此类 AI 工作负载所需的典型批量处理大小以及计算和带宽的平衡,Arm CPU 如何适配此类用例。并进一步阐释 Arm CPU 的 AI 功能,展示其灵活性和可编程性如何巧妙地实现软件优化,从而为许多 LLM 用例带来巨大的性能优势和发展机会。
LLM 简介
生成式 AI 可采用的网络架构多种多样。LLM 以其无可比拟的大规模解释和生成文本的能力,迅速崭露头角。
顾名思义,大语言模型 (LLM) 比以往使用的模型要大得多。确切地说,其可训练参数达到一千亿到一万亿。如此规模的参数量,至少是 2018 年 Google 训练的最大型先进自然语言处理 (NLP) 模型之一的 BERT(基于 Transformer 的双向编码器表示技术)三倍以上的数量级。
那么,一个一千亿参数的模型如何转化为 RAM 呢?如果打算在使用 16 位浮点数加速的处理器上部署这一模型,那么至少需要 200 GB 的 RAM!
因此,这些大模型只能在云端运行。然而,这带来了三个根本性的挑战,并进而限制此项技术的普及:
高昂的基础设施成本
隐私问题(因为用户数据可能会泄漏)
可扩展性挑战
2023 年下半年,一些规模较小、效率更高的 LLM 逐渐涌现。这些模型将生成式 AI 扩展至移动端,让此项技术的应用变得更加普遍。
2023 年,Meta 的 Llama 2、Google 的 Gemini Nano 和微软的 Phi-2 开辟了移动端 LLM 的部署,以解决上述三大挑战。具体来说,这三个模型的可训练参数分别达到 70 亿、32.5 亿和 27 亿。
在移动端 CPU 上运行 LLM
基于 Arm 技术,当今的移动设备拥有强大的计算能力,能够实时运行复杂的 AI 算法。事实上,现有的旗舰和高端智能手机已经可以运行 LLM。
预计未来 LLM 在移动端的部署将会加速,并可能出现如下用例:
文本生成:举例而言,我们要求虚拟助理为我们撰写一封电子邮件。
智能回复:即时通讯应用自动提供针对某个问题的建议回复。
文本摘要:电子书阅读器提供章节摘要。
在上述的用例中,模型需要处理大量的用户数据。而在边缘侧运行的 LLM 则无需连接网络,用户数据便会保留在设备中,这将有助于保护个人隐私,同时降低延迟,改善响应速度和用户体验。这些都是在边缘侧移动设备上部署 LLM 所能带来的优势。
幸运的是,得益于 Arm CPU,全世界约 99% 的智能手机都具备在边缘侧处理 LLM 所需的技术。
在 2024 世界移动通信大会 (MWC 2024) 上 Arm 进行了相关演示,敬请观看以下视频:
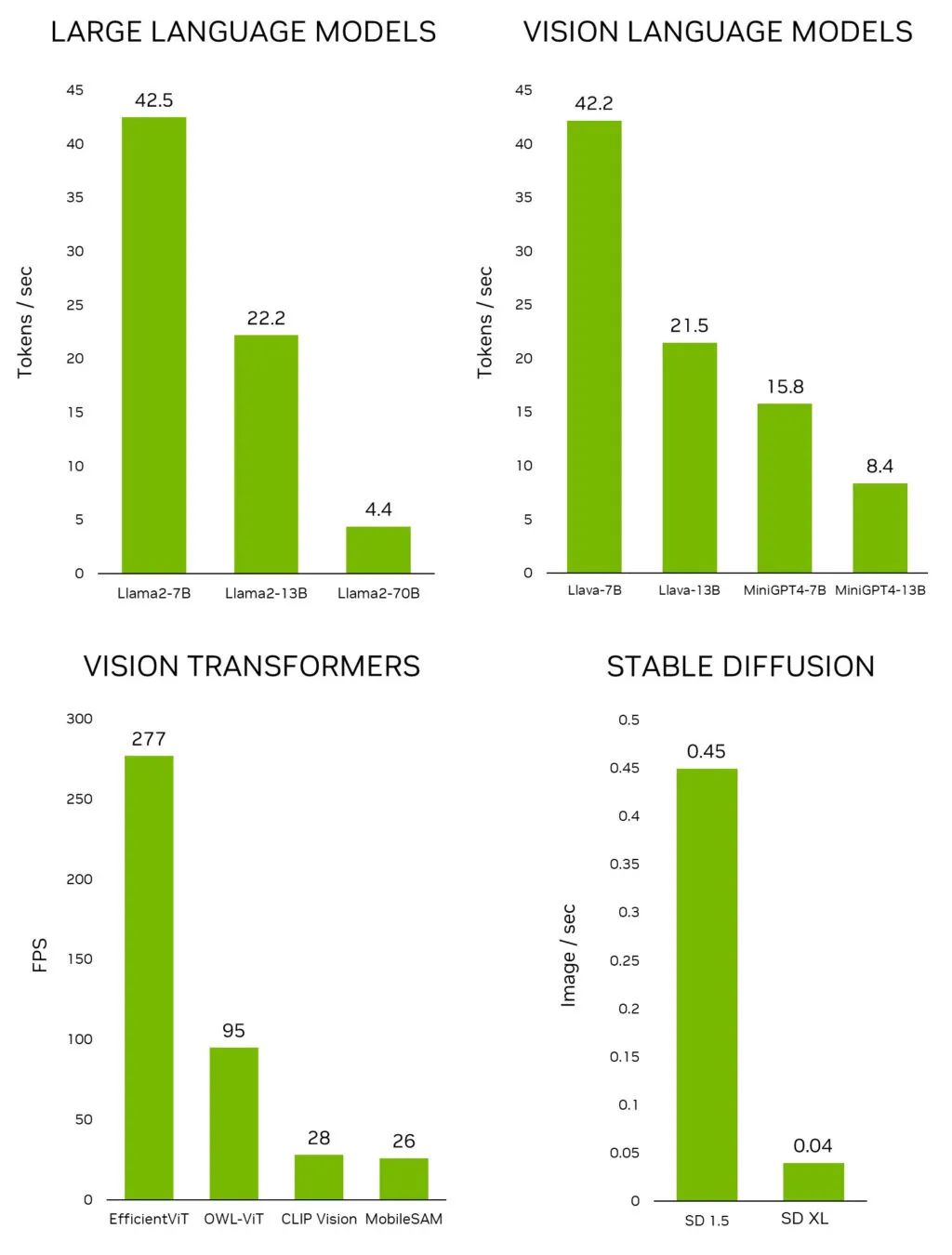
该视频演示了在搭载三核 Arm Cortex-A700 系列 CPU 核心的现有安卓手机上运行 Llama2-7B LLM 的性能表现。视频中展示的是实际运行速度,可以看到安卓应用里的虚拟助手反应非常灵敏,回复速度很快。词元 (Token) 首次响应时间表现惊人,文本生成速率达到每秒 9.6 个词元,高于人们的平均阅读速度。这得益于现有针对 AI 设计的 CPU 指令和专门为 LLM 进行的软件优化。更重要的是,所有处理都在边缘(即移动设备上)本地完成。
随着新模型的不断涌现,Arm 也在不断地改进 Arm 平台上的 LLM 体验。随着近期 Meta 推出了最新 Llama 3 模型,以及微软发布了 Phi-3-mini (Phi-3 3.8B) 模型,我们迅速地让它们得以在移动设备上的 Arm CPU 运行。Llama 3 和 Phi-3-mini 比它们的前代模型更大。从体量上来看,最小版本的 Llama 2 为 7B,而 Llama 3 达到了 8B;另外,Phi-2 为 2.7B,而 Phi-3-mini 达到了 3.8B。这些新的 AI 模型能力更强,可以回应更广泛的问题。
新的演示配备了一个经过专门训练的聊天机器人“Ada”,可以作为科学和编码的虚拟助教。在以下视频中运行的 Phi-3-mini 模型显示出同样令人印象深刻的词元首次响应时间性能,文本生成速率每秒超过 15 个词元。该演示基于我们为 Llama 2 和 Phi-2 开发的现有软件优化。尽管这些模型更大、更复杂,但这清楚地表明它们可以在当今由 Arm CPU 驱动的移动设备上良好运行。
那么这些演示是如何开发出来的呢?接下来,我将分享一些技巧,来帮助大家在搭载 Arm CPU 的安卓手机上部署 LLM。
在移动设备上部署 LLM
首先要强调的是,Arm CPU 为 AI 开发者提供了诸多便利。因此,如今第三方应用中有 70% 的 AI 应用均运行在 Arm CPU 上。由于其编程能力非常灵活,AI 开发者可以尝试应用创新的压缩和量化技术,让 LLM 更加小巧,并且在各种环境下运行得更快。实际上,我们之所以能运行一个具有 70 亿参数的模型,关键就在于整数量化技术,我们的演示中使用的是 int4。
int4 位量化
作为一项关键技术,量化可以将 AI 和机器学习 (ML) 模型压缩至足够小,以便能在 RAM 有限的设备上高效运行。因此,这项技术对于那些原生以浮点数据类型(如 32 位浮点 FP32 和 16 位浮点 FP16)存储数十亿可训练参数的 LLM 来说,是必不可少的。例如,采用 FP16 权重的 Llama2-7B 版本至少需要大约 14 GB 的 RAM,而这是许多移动设备无法满足的条件。
通过将 FP16 模型量化到四位,我们可以将其大小缩减至原来的四分之一,并将 RAM 使用量降低到大约 4 GB。得益于 Arm CPU 提供的巨大软件灵活性,开发者还可以通过减少参数值位数来获得更小的模型。但请注意,将位数减少至三位或两位可能会导致准确度明显降低。
在 CPU 上运行工作负载时,我们建议通过一个简单的技巧来提高其性能,即设置线程的 CPU 关联性。
采用线程关联性改善 LLM 的实时体验
一般来说,当部署 CPU 应用时,操作系统 (OS) 负责选择运行线程的核心。此决策并不总是以实现最佳性能为目标。
但是,对于非常看重性能表现的应用而言,开发者可以使用线程关联性,强制线程运行在特定核心上。这项技术帮助我们提升了 10% 以上的延迟速度。
您可以通过关联性掩码指定线程关联性,关联性掩码的每一位都代表系统中的一个 CPU 核心。假设有八核,其中四核是 Arm Cortex-A715 CPU,并被分配给位掩码的最高有效位 (0b1111 0000)。
为了在每个 Cortex-A715 CPU 核心上运行每个线程,我们应该在执行工作负载之前将线程关联性掩码传递给系统调度程序。在安卓设备中,此操作可通过以下系统调用函数完成:
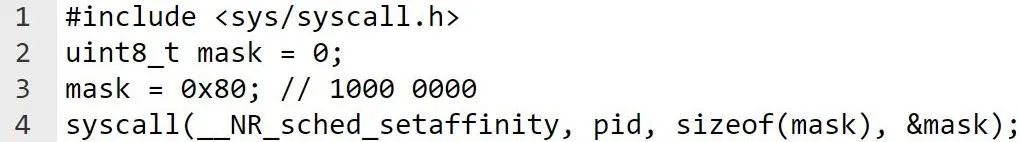
例如,假设有两个线程,我们可以为每个线程使用以下位掩码:
线程 1:位掩码 0b1000 0000
线程 2:位掩码 0b0100 0000
执行工作负载后,我们应将关联性掩码重置为默认状态,如下面的代码片段所示:

通过利用线程关联性,您可轻松提高各类 CPU 工作负载性能。然而,仅靠 int4 量化和线程关联性还不足以全方面发挥 LLM 的性能。我们知道,低延迟直接关系到用户的整体体验,对此类模型至关重要。
因此,Arm 开发了高度优化的 int4 矩阵乘向量和矩阵乘矩阵 CPU 例程,以显著提升性能表现。
Arm int4 优化矩阵乘矩阵和矩阵乘向量例程
矩阵乘矩阵和矩阵乘向量例程是对 LLM 性能至关重要的函数。这些例程已使用 SDOT 和 SMMLA 指令针对 Cortex-A700 系列 CPU 进行了优化。相较于 llama.cpp 中的原生实现,我们的例程(即将推出)将词元首次响应时间(编码器)缩短了 50% 以上,文本生成速率提升了 20%。
这仅仅只是开始......
出色的用户体验、优越的性能表现,而这仅仅只是开始......借助专用 AI 指令、CPU 线程关联性,以及经过软件优化的例程,这些演示展示了出色的交互式用例的整体使用体验。上文中的演示视频展示出,词元首次响应时间非常短,文本生成速率快于人们的平均阅读速度。更令人兴奋的是,所有搭载 Cortex-A700 的移动设备均能实现这样的性能表现。
我们也很高兴看到开发者开源社区参与到 Arm 平台上的模型工作。Arm CPU 为 AI 开发者社区提供了试炼自己技术的机会,以提供进一步的软件优化,使 LLM 得以更小、更快、更高效。开源社区中的开发者大约在 48 小时内就成功在 Arm 平台上启动并运行了新模型,这便是很好的例证。我们期待看到更多来自开源的力量参与到 Arm 平台上的生成式 AI 开发。
而这只是基于 Arm 技术的 LLM 体验的初期成果。随着 LLM 变得更加小巧而精密,它们在边缘移动设备上的表现也将稳步提升。此外,Arm 以及我们行业领先生态系统中的合作伙伴将继续推动硬件进步和软件优化,加速发展 CPU 指令集的 AI 功能,如针对 Armv9-A 架构的可伸缩矩阵扩展 (Scalable Matrix Extension, SME) 等。这些进展预示着在不久的未来,基于 Arm 架构的消费电子设备将迎来 LLM 用例的新时代。
审核编辑:刘清
-
RAM
+关注
关注
8文章
1403浏览量
121156 -
人工智能
+关注
关注
1821文章
50471浏览量
267610 -
LLM
+关注
关注
1文章
351浏览量
1402 -
生成式AI
+关注
关注
0文章
538浏览量
1141
原文标题:移动端生成式 AI 如何在 Arm CPU 上运行?
文章出处:【微信号:Arm社区,微信公众号:Arm社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何在裸机环境中运行KleidiAI微内核

新功能get√:AI大学移动端,来了!
如何在RK3399这一 Arm64平台上搭建Tengine AI推理框架呢
如何在RK3399上搭建Tengine AI推理框架呢
如何在基于Arm的设备上运行游戏AI呢
程序是如何在 CPU 中运行的(二)

利用 NVIDIA Jetson 实现生成式 AI
Arm平台赋能移动端生成式AI
如何在基于Arm Neoverse平台的CPU上构建分布式Kubernetes集群
Arm 公司面向移动端市场的 Arm Lumex 深度解读
全新Arm C1 CPU集群推动移动端侧AI转型



评论