 康谋分享|aiSim5基于生成式AI扩大仿真测试范围(终)
康谋分享|aiSim5基于生成式AI扩大仿真测试范围(终)
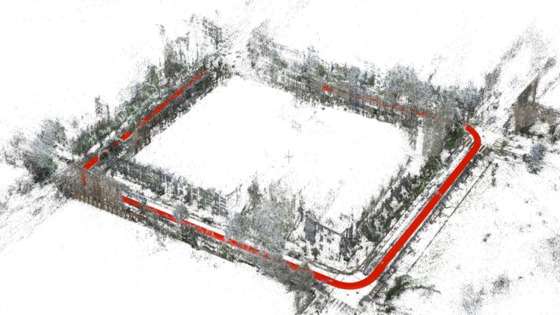
在前面的几章节中探讨了aiSim仿真合成数据的置信度,此外在场景重建和测试流程闭环的过程中,难免会面临3D场景制作重建耗时长、成本高、扩展性低以及交通状况复杂程度难以满意等问题,当前的主要挑战在于如何自动化生成3D静态场景并添加动态实例编辑,从而有效缩短测试流程,扩大仿真测试范围。
 图1:实际图像
图1:实际图像 图2:NeRF重建场景
图2:NeRF重建场景对于3D重建,目前主要的两种解决方案为NeRF和3DGS。
一、NeRF
1、神经辐射场(Neural Radiance Fields)
NeRF是将三维空间中的每个点的颜色和密度信息编码为一个连续的函数并由MLP参数化。给定一个视角和三维空间中的点,NeRF可以预测该点的颜色和沿视线方向的密度分布。通过对这些信息进行体积渲染,NeRF能够合成出新视角下的图像。

2、优势
高保真输出。
- 基于NerFStudio提供了较为友好地代码库。
- 相对较快的训练时间。
- 对于待重建区域具有可扩展性。
3、不足及主要挑战
渲染速度缓慢。NeRF需要沿着从相机到场景的每条光线进行大量的采样和计算,以准确估计场景的体积密度和颜色。这个过程计算密集,在NVIDIA A100上进行了测试,全HD分辨率下,渲染一张图像大约需要10s。
场景深度估计效果不理想。NeRF通过体积渲染隐式地学习了场景的深度信息,但这种深度信息通常是与场景的颜色和密度信息耦合在一起的。这意味着,如果场景中存在遮挡或非朗伯(non-Lambertian)反射等复杂情况,NeRF可能难以准确估计每个像素的深度。

近距离物体重建质量可能较低。这可能是由视角和分辨率不足、深度估计不够准确以及运动模糊遮挡等问题造成的。

高FOV相机校准不完善导致的重影伪影。

当然为了解决这些问题研究人员通过引入深度正则化来提升NeRF深度估计的准确性和稳定性,通过优化NeRF的结构和算法提升渲染速度。
二、3DGS
1、3D高斯泼溅(3D Gaussian Splatting)
3DGS采用三维高斯分布来表示场景中的点云数据,每个点用一个具有均值和协方差的高斯函数来描述。通过光栅化渲染高斯函数,从而生成逼真的3D场景图像。

2、优势
训练时间短。
近似于实时的渲染。
提供高保真的输出。
3、不足及主要挑战
代码库友好度较低。相比于NeRFStudio,文档的完善程度和易用性较低。
初始点云获取需求高,需要精确的传感器和复杂的数据处理流程,否则将会对3DGS的性能产生明显的影响。

深度估计同样不足,主要可能有几个原因:在优化过程中倾向于独立优化每个高斯点,导致在少量图像下出现过拟合;由于缺乏全局的几何信息,导致在大型场景下或复杂几何结构重建时深度估计不准确;初始点云的深度信息不够准确等。

相机模型支持受限。目前3DGS主要支持针孔相机模型,虽然理论上可以推导出其他相机模型的3DGS版本,但还需要后续的实验验证其有效性和准确性。
重建区域可扩展受限,主要是缺乏LiDAR覆盖区域之外的几何信息导致的不完整重建以及大型城市场景重建的大量计算。
集成和资源密集的挑战,目前3DGS集成通常依赖Python接口;3DGS在运行时可能会占用大量的VRAM。
通过优化超参数和采用新方法,如Scaffold-GS,可能有助于减少内存需求,提高在大型场景下的处理能力。
三、操作方法
1、训练流程
第一步:输入——相机视频数据;自车运动数据;校准数据;用于深度正则化的LiDAR点云数据;
第二步:移除动态对象:创建分割图来识别和遮罩图像中的不同对象和区域;对动态对象进行自动注释*(康谋aiData工具链);

第三步: 进行NeRF或Gaussian splatting。
NeRF:
可以使用任何摄像头模型,示例中使用的是MEI相机模型;
采用Block-NeRF进行大规模重建;
嵌入不同的气候条件。
Gaussian splatting:
将输入的相机转化为针孔相机模型;
可以从COLMAP或LiDAR中获得初始点云;
采用Block-Splatting进行大规模重建。
2、添加动态对象
在NeRF和3DGS生成静态场景后,aiSim5将基于外部渲染API进一步增加动态元素,不仅可以重建原始场景,也可以根据测试需求构建不同的交通状态。
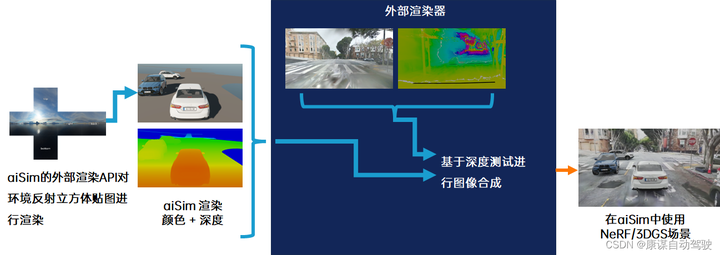
aiSim5中基于NeRF/3DGS场景细节。
 图13:网格投射阴影
图13:网格投射阴影 图14:车下环境遮蔽
图14:车下环境遮蔽3、效果展示
在aiSim5中完成动态对象的添加后,可以自由的在地图场景中更改交通状态,用于感知/规控等系统的SiL/HiL测试。
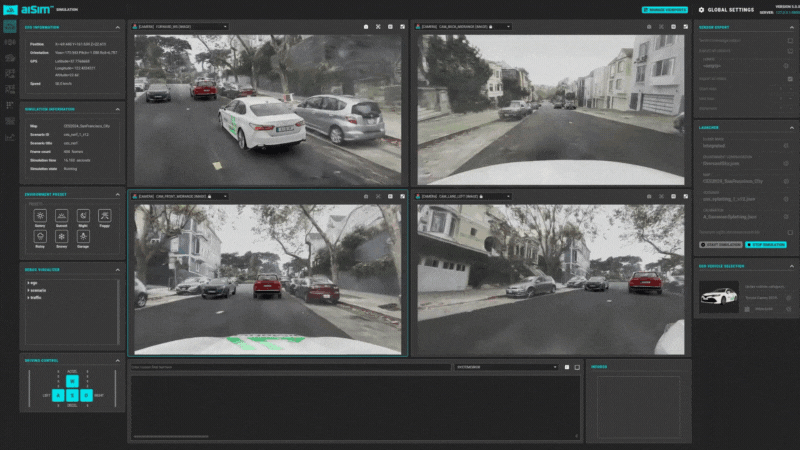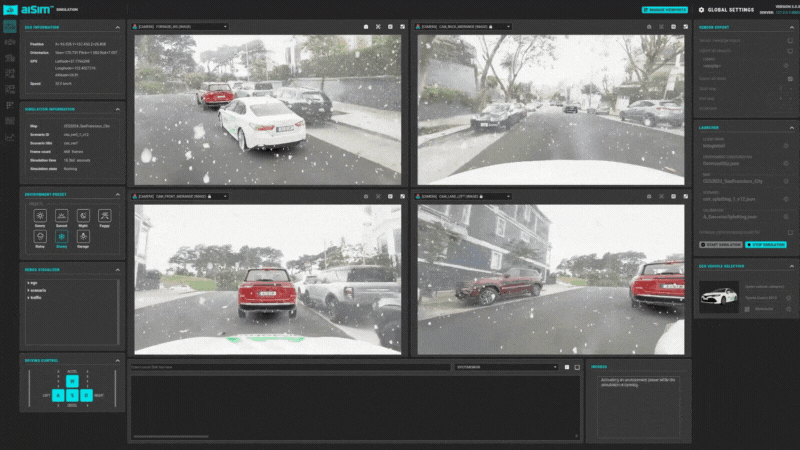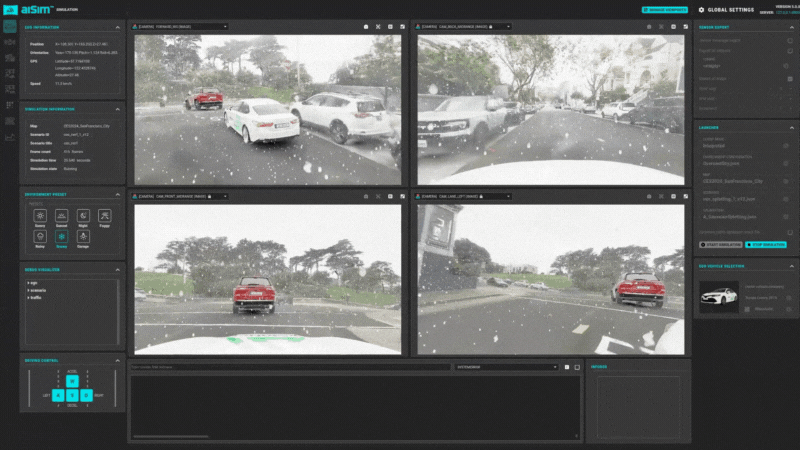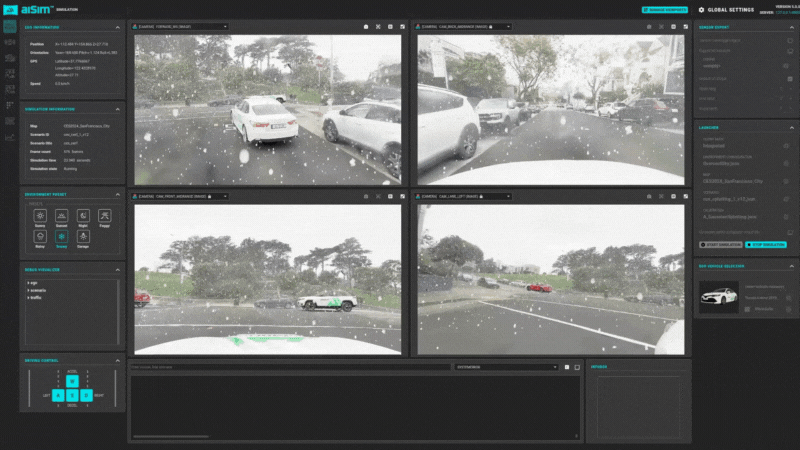 图15:aiSim5运行NeRF城市场景1
图15:aiSim5运行NeRF城市场景1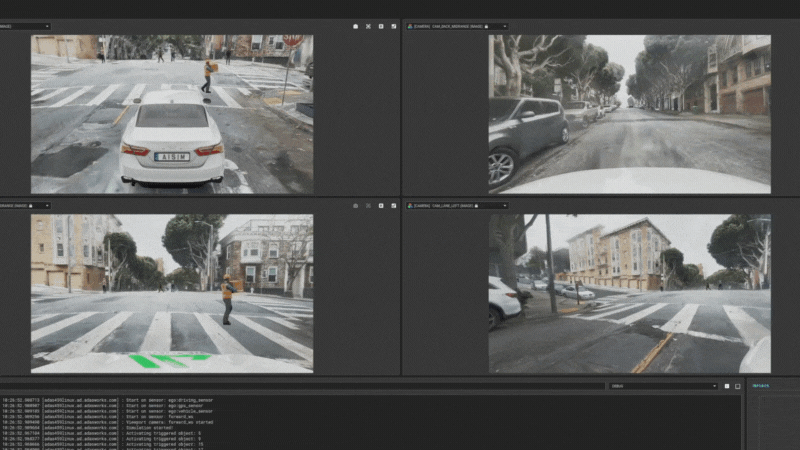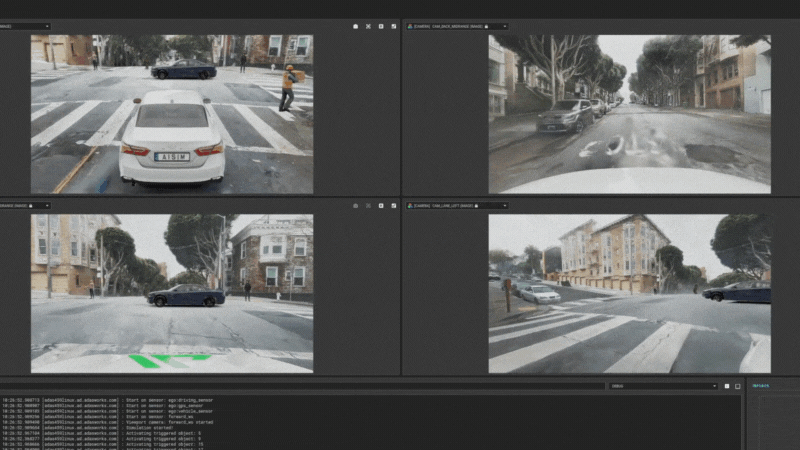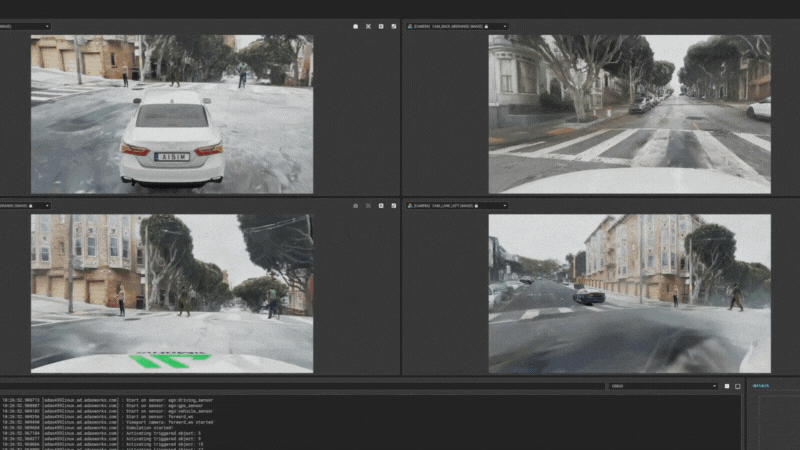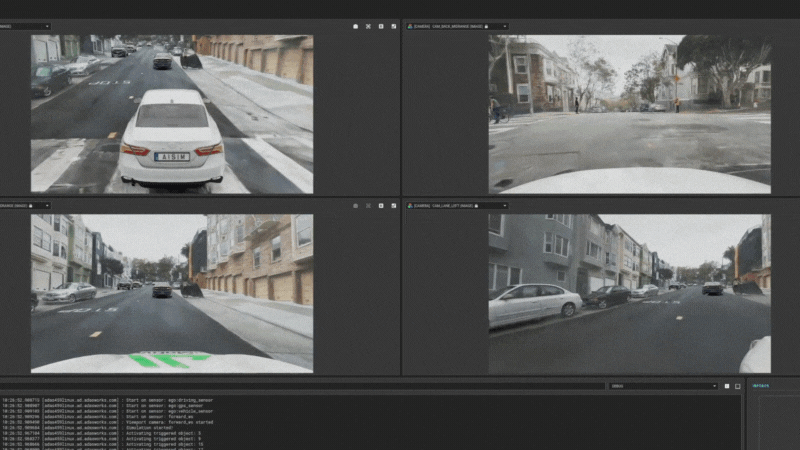 图16:aiSim5运行NeRF城市场景2
图16:aiSim5运行NeRF城市场景2作者介绍
崔工
康谋科技仿真测试业务技术主管,拥有超过5年的汽车仿真测试及自动驾驶技术研发经验,熟练掌握仿真测试工具和平台,如aiSim、HEEX等,能有效评估和优化自动驾驶系统的性能和安全性。拥有出色的跨文化沟通能力,成功带领团队完成多项海外技术合作项目,加速了公司在自动驾驶技术上的国际化进程。作为技术团队的核心,领导并实施过大规模的自动驾驶仿真测试项目,对于车辆行为建模、环境模拟以及故障诊断具有独到见解。擅长运用大数据分析和人工智能技术,优化仿真测试流程,提高测试效率和结果的准确性。
-
测试
+关注
关注
8文章
5460浏览量
127390 -
仿真测试
+关注
关注
0文章
92浏览量
11392 -
自动驾驶
+关注
关注
787文章
13992浏览量
167632
发布评论请先 登录
相关推荐
康谋分享 | 3DGS:革新自动驾驶仿真场景重建的关键技术

康谋方案 | 基于AI自适应迭代的边缘场景探索方案

聚云科技荣获亚马逊云科技生成式AI能力认证
聚云科技荣获亚马逊云科技生成式AI能力认证 助力企业加速生成式AI应用落地
康谋分享 | 汽车仿真与AI的结合应用

安谋科技异构算力组合,破局生成式AI算力挑战
自动驾驶联合仿真——功能模型接口FMI(终)

康谋分享 | 自动驾驶联合仿真——功能模型接口FMI(三)


IBM与SAP深化生成式AI领域合作
康谋分享 | aiSim5仿真场景重建感知置信度评估(三)

康谋分享|aiSim5激光雷达LiDAR模型验证方法(二)

康谋分享 | aiSim5 物理相机传感器模型验证方法(一)






 工商网监
工商网监
评论