 摩尔线程与无问芯穹宣布完成基于GPU千卡集群的3B规模大模型实训
摩尔线程与无问芯穹宣布完成基于GPU千卡集群的3B规模大模型实训

摩尔线程联合无问芯穹宣布,双方已在本周正式完成基于国产全功能GPU千卡集群的3B规模大模型实训。该模型名为“MT-infini-3B”,在摩尔线程夸娥(KUAE)千卡智算集群与无问芯穹AIStudio PaaS平台上完成了高效稳定的训练。
本次实训充分验证了夸娥千卡智算集群在大模型训练场景下的可靠性,同时也在行业内率先开启了国产大语言模型与国产GPU千卡智算集群深度合作的新范式。
MT-infini-3B模型训练总用时13.2天,经过精度调试,实现全程稳定训练不中断,集群训练稳定性达到100%,千卡训练和单机相比扩展效率超过90%。目前,实训出来的MT-infini-3B性能在同规模模型中跻身前列,相比在国际主流硬件上训练而成的其他模型,在C-Eval,MMLU,CMMLU等3个测试集上均实现性能领先。
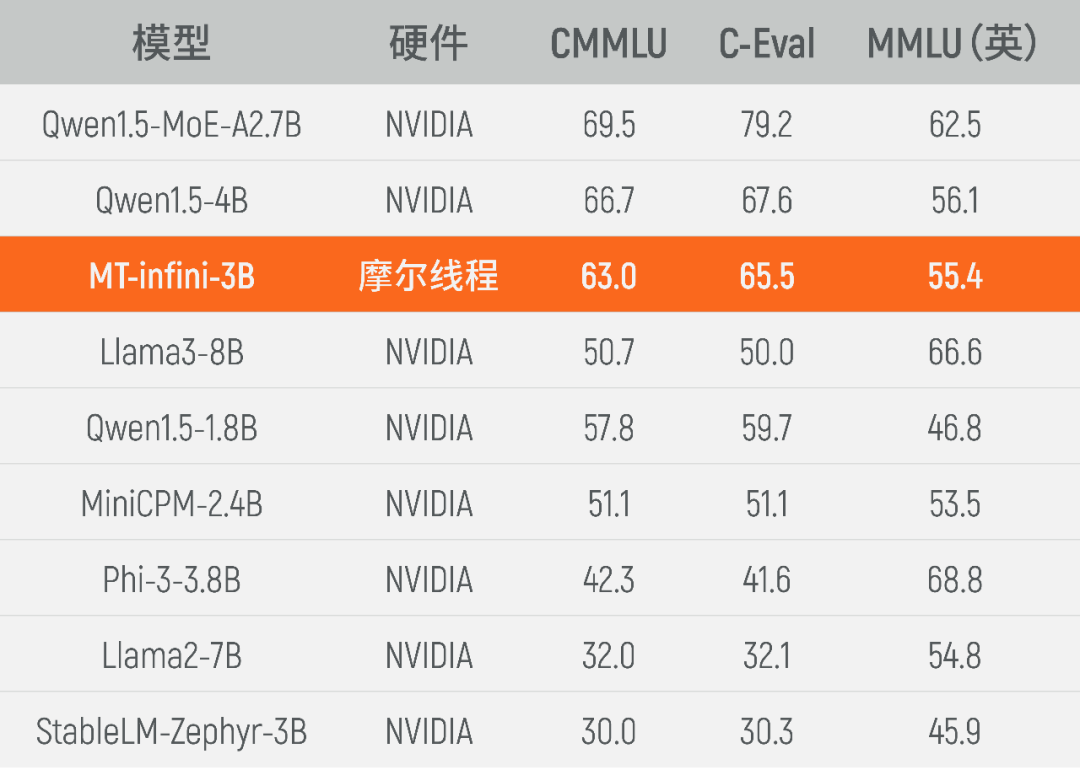
MT-infini-3B性能表现
无问芯穹联合创始人兼CEO夏立雪表示:“国内大模型与国产芯片的软硬件协同发展,最终目标是构建一个成熟的生态系统。无问芯穹正在打造‘M种模型’和‘N种芯片’间的‘M×N’中间层产品,实现多种大模型算法在多元芯片上的高效、统一部署。摩尔线程是第一家接入无问芯穹并进行千卡级别大模型训练的国产GPU公司,而‘MT-infini-3B’的训练是行业内首次实现基于国产GPU芯片从0到1的端到端大模型实训案例。”
摩尔线程创始人兼CEO张建中表示:“无问芯穹在夸娥千卡智算集群上实现的从零开始的大模型训练,不仅是对摩尔线程技术实力的有力认证,更是实现了国内大模型训练的国产化闭环。摩尔线程夸娥千卡智算集群以全功能GPU为底座,提供软硬一体化的全栈解决方案,具备高兼容性、高稳定性、高扩展性等综合优势,我们致力于成为AGI时代大模型训练坚实可靠的先进基础设施。”
此前,摩尔线程与无问芯穹已达成深度战略合作。无问芯穹大模型开发与服务平台“无穹Infini-AI”和摩尔线程大模型智算千卡集群夸娥已完成系统级融合适配,该平台可以灵活调用夸娥的集群能力以完成大模型的训练、微调与推理任务。未来,双方还将开展更多适配与测试,推动国产大模型技术的快速发展与应用普及,为中国人工智能产业的蓬勃发展贡献力量。
审核编辑:刘清
-
GPU芯片
+关注
关注
1文章
307浏览量
6554 -
摩尔线程
+关注
关注
2文章
285浏览量
6663 -
大模型
+关注
关注
2文章
3771浏览量
5273
原文标题:摩尔线程携手无问芯穹:基于夸娥千卡智算集群的“MT-infini-3B”大模型实训已完成
文章出处:【微信号:moorethreads,微信公众号:摩尔线程】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
沐曦股份Day 0适配阿里千问Qwen3.6-35B-A3B大模型

Day-0支持|摩尔线程率先完成MiniMax M2.7大模型适配

天数智芯完成阿里云通义千问Qwen3.5系列多模态模型全量适配
爱芯元智联合无问芯穹,即将上线AXClaw Box帝王虾盒

沐曦股份曦云C系列GPU全面适配通义千问Qwen3.5三款新模型

摩尔线程MTT S5000全面适配Qwen3.5三款新模型
沐曦股份曦云C系列GPU深度适配通义千问Qwen3.5模型

国产算力首证具身大脑模型训练实力:摩尔线程联合智源研究院完成RoboBrain 2.5全流程训练

墨芯人工智能千卡集群正式签约入驻新疆算力中心
摩尔线程携手生态合作伙伴打造的AI教育实训基地启用
阿里通义千问发布小尺寸模型Qwen3-4B,手机也能跑
摩尔线程吴庆详解 MUSA 软件栈:以技术创新释放 KUAE 集群潜能,引领 GPU 计算新高度




评论