 基于英特尔至强可扩展处理器的H3C UniServer R6900 G6服务器解决方案
基于英特尔至强可扩展处理器的H3C UniServer R6900 G6服务器解决方案
概 述
近年来人工智能 (AI) 技术突飞猛进的一个重要标志是大语言模型 (LLM) 的重要突破。大语言模型是基于自然语言处理 (NLP) 技术的transformer机制,目标在于理解、生成自然语言文本,以及处理人机对话等逻辑性创造性语义理解要求更高的自然语言任务。与传统NLP模型不同,大语言模型具备参数规模巨大、训练数据量大等特点,在模型训练、模型微调、模型推理等阶段均需要庞大的算力资源。在大模型应用 “百花齐放” 的今天,AI算力的供需缺口已经成为一个不争的事实,如何快速构建高性能、低成本的算力平台成为企业普遍关心的问题。
面向希望经济、高效进行大语言模型落地场景的中小企业用户,新华三 (H3C) 提供了基于英特尔至强可扩展处理器的H3C UniServer R6900 G6服务器解决方案。该服务器能够借助英特尔至强可扩展处理器内置的强大AI加速能力,满足常见大语言模型微调和推理算力需求。同时,该服务器还具备交付与部署便捷、性价比高等优势,能够帮助更多中小企业挖掘大语言模型的应用潜力,赋能企业的智能化转型。
背景:大语言模型突飞猛进中小企业迎来转型契机
大语言模型是当前大模型最具应用潜力的领域之一,由大语言模型赋能的AI应用已经在搜索增强、代码生成、问答系统、智能语音助手、知识图谱构建、专业文档生成、智能翻译等任务中展现出巨大的价值。赛迪研究院的数据显示,截止2023年 12月,中国已有多家语言大模型研发厂商,2023年市场规模约为132.3亿元,增长率达到110%;预测到2027年,中国语言大模型市场规模有望达到600亿元1。对于中小企业而言,积极迎接大语言模型带来的产业发展浪潮,将有助于跟上AI发展趋势,提升企业的竞争力,助力降本增效。
大语言模型落地链路主要分为模型预训练、模型微调 (Fine Tuning)、模型推理等阶段,对于中小企业而言,由于投入规模限制和特定应用场景的需求,其落地的工程化路径更倾向于使用已经初步完成大规模预训练的开源/通用大模型(30B及以下),并采用特定领域的数据集对模型进行微调,通过检索增强生成 (RAG) 等相关技术,同样达到与通用大模型接近的理想效果,以使其更好地适应特定的任务或应用场景。
综上所述,在大语言模型的实际部署阶段,中小企业需要解决大语言模型微调与推理问题,这会在性能、算力成本、效率等方面遇到相应的挑战。
在满足微调和推理两大场景需求的同时降低成本
在大语言模型微调方面,性能与成本通常是呈现正比关系,采用专用的AI服务器能够提供强大的算力,但是会消耗高额的成本,这对于中小企业而言是一项巨大的支出。
快速迎上大语言模型的发展浪潮
大语言模型发展的日新月异意味着,中小企业必须快速行动起来,投身到大语言模型的发展浪潮中。但同时,专用的AI服务器面临着供货紧张、部署繁琐、上线时间周期长等客观现状,难以快速提供AI算力支持,反观不少企业都拥有大量的通用服务器资源,若能高效利用这些资源,将有助于大幅缩短大模型应用上线周期。
解决方案:基于英特尔至强可扩展处理器的H3C UniServer R6900 G6服务器
针对中小企业在中小规模的模型微调与推理上的挑战,H3C推出了H3C UniServer R6900 G6服务器单一节点解决方案,成功地展示了基于中等规模大语言模型的微调和推理能力。
作为该解决方案的核心,H3C UniServer R6900 G6服务器是H3C基于第四代英特尔至强可扩展处理器自主研发的新一代4U四路机架式服务器。整机设计在上一代产品的基础上进行了全面优化,无论在计算效率、扩展能力还是低碳节能等方面都达到了全新的高度,是继G5产品之后的又一标杆四路服务器产品,是大规模虚拟化、数据库、内存计算、数据分析、数据仓库、商业智能、ERP等数据密集型应用关键业务的理想选择。

图 1. H3C UniServer R6900 G6服务器
H3C UniServer R6900 G6服务器搭载的第四代英特尔至强可扩展处理器通过创新架构增加了每个处理器核心每个时钟周期的可执行指令数量,每个插槽多达60个核心,支持8通道DDR5内存,有效提升了内存带宽与速度,并通过PCIe 5.0(80个通道)实现了更高的PCIe带宽提升。第四代英特尔至强可扩展处理器提供了出色性能和安全性,可根据用户的业务需求进行扩展。借助内置的加速器,用户可以在AI、分析、云和微服务、网络、数据库、存储等类型的工作负载中获得优化的性能。
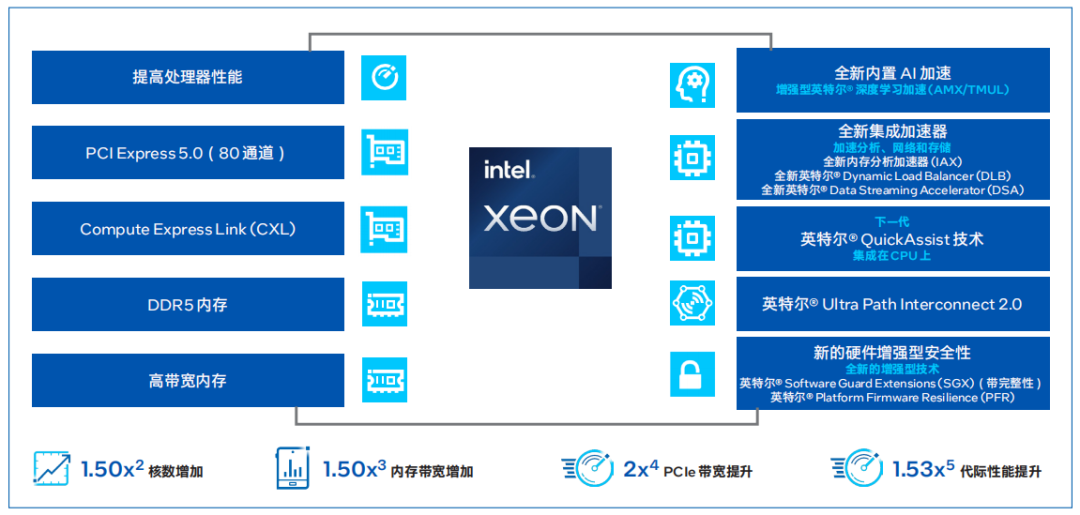
图 2. 第四代英特尔至强可扩展处理器为数据中心提供多种优势
H3C UniServer R6900 G6服务器单一节点解决方案在大语言模型微调及推理上的能力,源于以下三大技术突破:
单CPU算力突破
在大模型微调和推理任务中,涉及大规模矩阵运算。随着模型尺寸的扩大,矩阵的大小也相应增加,这对处理器的算力有着极高的要求。
第四代英特尔至强可扩展处理器提供了增强的AI算力支持。与此前的英特尔至强可扩展处理器中提供的英特尔AVX-512不同,英特尔 AMX采用了全新的指令集与电路设计,通过提供矩阵类型的运算,显著增加了人工智能应用程序的每时钟指令数 (IPC),可为AI工作负载中的训练和推理带来大幅的性能提升。
单机算力突破
在大语言模型的训练和微调过程中,为提供充足的算力,通常采用多机多卡的分布式训练方式,但这种方式会带来额外的系统互联开销,同时也可能导致训练性能的损耗。
H3C结合英特尔平台的特有的UPI (Ultra Path Interconnect) 多CPU组合技术,推出了H3C UniServer R6900 G6四路服务器。这种服务器突破了传统双路服务器的算力限制,能够提供单机更高的算力密度。方案采用了高带宽低延迟的UPI互联方案,能够实现CPU算力的高速横向倍增。这意味着,用户可以在一台节点上完成所有的计算任务,从而避免了分布式训练可能带来的各种问题。
内存限制突破
大语言模型的训练和推理对于内存容量有着较高需求,这种需求源于AI 模型训练过程中的两个关键步骤:一是加载模型的权重,二是存储用于反向传播的梯度信息以及执行参数更新的优化器参数。此外,选择适当的训练批量大小也至关重要,因为较大的批量有助于模型更快地收敛,从而提升微调后模型的性能。然而,较大的批量会使得中间激活值的存储也占据了大量的内存空间。以Llama 30B模型为例,在进行16位浮点数训练时,如果训练批量大小被设定为16并且使用Adam优化器,估算需要600GB左右的内存才能成功完成30B模型的LoRA微调。虽然目前 涌现了非常多的技术手段来解决内存限制的问题,但是会引入复杂的技术栈和额外复杂度。
针对上述问题,H3C UniServer R6900 G6服务器可支持64根4800MT/s DDR5 ECC内存,能够提供高达16TB的内存容量,从而打破了内存限制。相比于使用GPU的方案,这种方案能够减少内存压缩和多卡间数据通信的开销,从而更有效地完成微调训练任务。
除了上面三方面的技术突破,在实现算力突破的同时,英特尔还针对大型语言模型的推理和训练过程,提供了一系列基于PyTorch框架的软件优化措施。这些优化被集成在IntelExtension for PyTorch开源软件库中,旨在进一步提升模型的性能和效率。
IntelExtension for PyTorch是英特尔发起的一个开源扩展项目,它基于 PyTorch的扩展机制实现,旨在通过提供额外的软件优化充分发挥硬件特性,帮助用户在原生PyTorch的基础上显著提升英特尔硬件(如CPU和GPU)上的深度学习推理计算和训练性能。通过扩展,PyTorch用户将能更加及时地受益于英特尔硬件的最新功能,并在第一时间体验软件优化带来的卓越性能和部署便捷性。
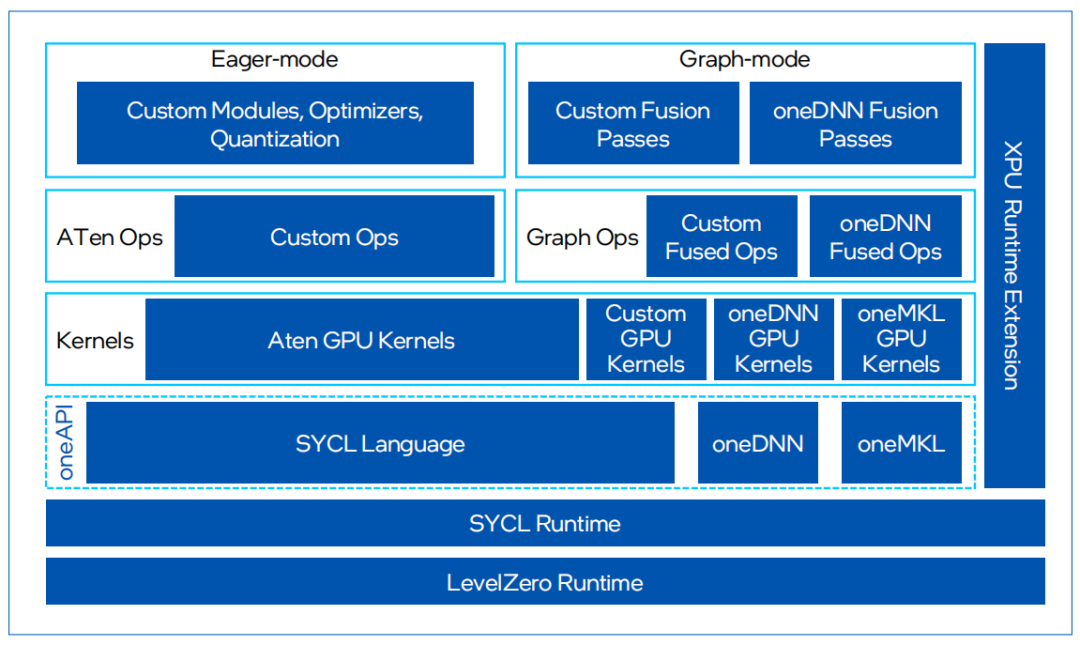
图 3.IntelExtension for PyTorch框架
目前,IntelExtension for PyTorch配合PyTorch,可支持PyTorch框架下大部分主流模型,其中深度优化模型有50+以上。用户只需要从Hugging Face拉取模型,加载到PyTorch框架中,通过简单几步完成BF16混合精度转换,模型就可以在CPU上高效部署。同时,Intel Extension for PyTorch面向transformer运算对相关计算进行了深入优化,实现了融合的ROPE (Fused Rotary Positional Embeddings) 操作,可以减少计算的复杂性并提高模型的运行效率。
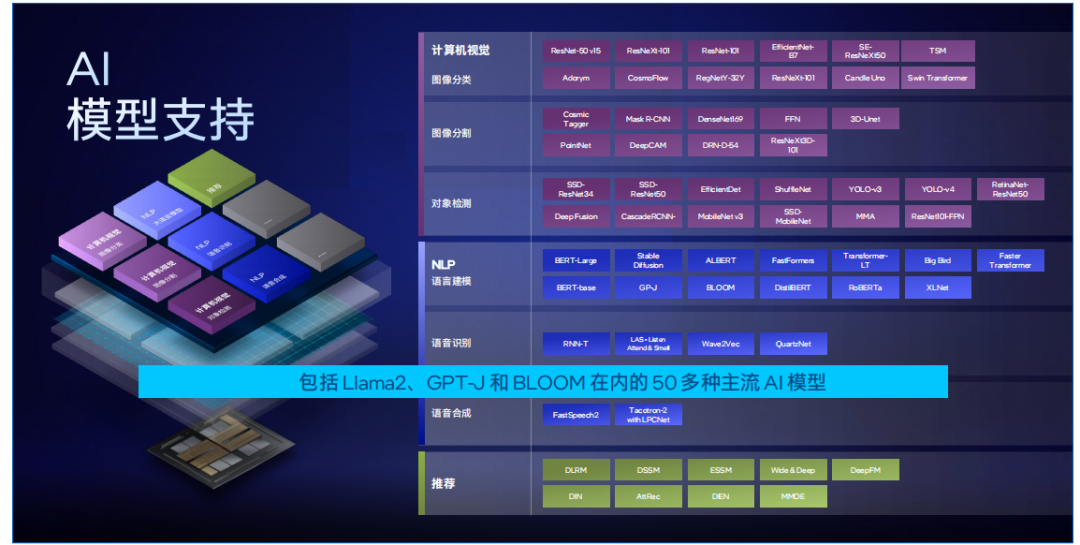
图 4.IntelExtension for PyTorch 支持50多种主流AI模型
性能验证:充分满足中等规模大模型微调
与推理的算力要求
为验证基于英特尔至强可扩展处理器的H3C UniServer R6900 G6服务器在大语言模型推理和微调两大场景的服务能力,H3C选择了英特尔至强金牌 6448H处理器+2TB内存的配置,并进行了测试。
微调场景
H3C对Llama2-7B和Llama2-13B模型,以及Llama1-30B模型进行了微调测试。这些测试在业界通用的Alpaca数据集(6.5M token,数据集大小 20MBytes)上进行,旨在评估在禁用梯度累积(Gradient Accumulation) 的情况下,四路服务器能支持的batch size,训练过程中的峰值内存占用,以及训练完成所需的时间。
测试数据如表1所示,对于7B、13B和30B大小的Llama模型,四路H3C UniServer R6900 G6服务器可以满足实用训练时长的要求。
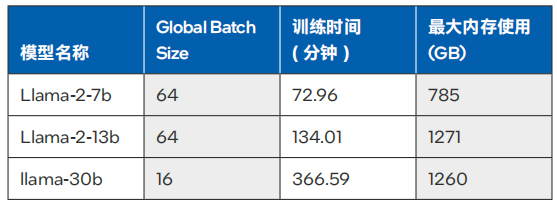
表 1. 不同模型在微调中的训练时间与最大内存使用6
推理场景
H3C对Llama2的7B和13B模型,以及Code Llama的34B模型进行了深入测试,以充分挖掘基于英特尔至强可扩展处理器的H3C UniServer R6900 G6服务器的性能极限。本测试专注于评估这些硬件配置在不同的 input/output token latency、 batch size,以及多实例运行情况下的表现。
首token延迟、总吞吐与并发数的测试结果分别如图5、图6所示,对于 7B、13B大小的Llama模型,四路H3C UniServer R6900 G6服务器可以满足多实例运行的要求。
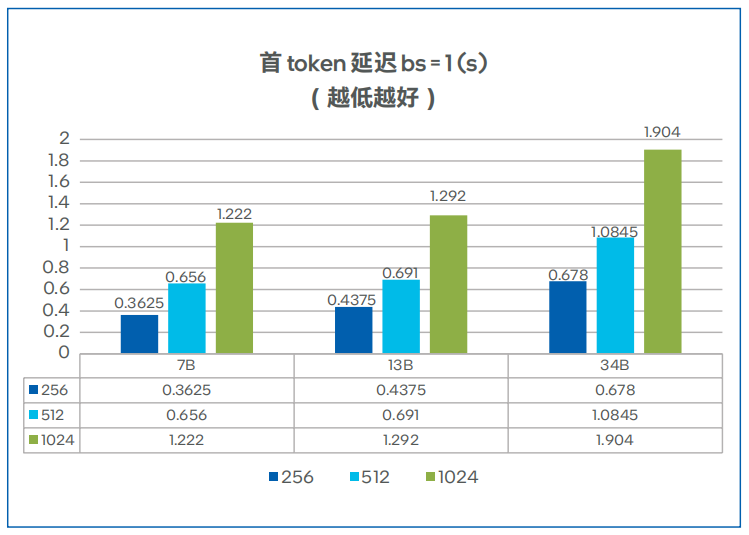
图 5. 不同模型的首token延迟7
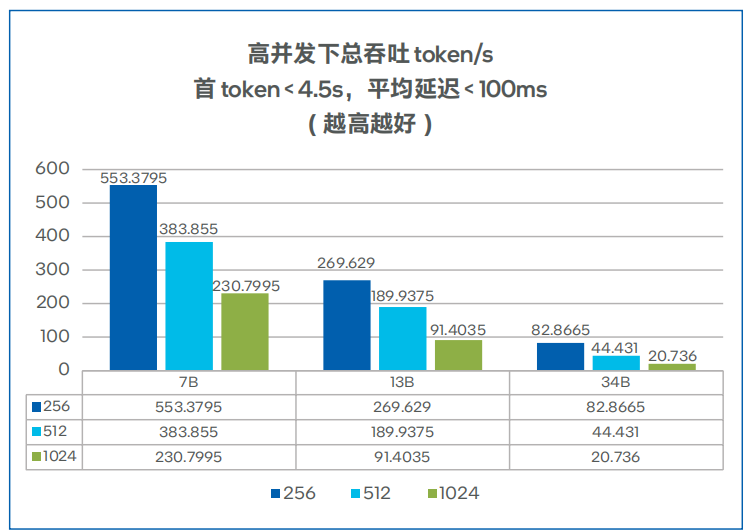
图 6. 不同模型的总吞吐性能测试8
收 益
基于英特尔至强可扩展处理器的H3C UniServer R6900 G6服务器提供了大语言模型微调推理一体方案,为中小企业提供了一种更高效、更经济的解决方案,实现了以下价值:
可以更加快速的推动以大语言模型为代表的AGI的部署:该方案能够在单一服务器上覆盖微调和推理,不仅简化了操作流程,也提高了算力平台的交付效率。同时,方案基于Pytorch,TensorFlow,OpenVINO等流行的开源框架,使得中小企业能够在CPU平台上方便快捷地搭建最新的模型服务,更快地将AGI应用到业务流程中。
有助于企业搭建更具性价比的大语言模型算力平台:该方案不依赖于昂贵的GPU服务器,而是可以采用更具经济性的通用CPU服务器,同时达到理想的性能表现,可以助力用户降低大语言模型算力平台的总体拥有成本 (TCO)。
实现出色的灵活性与扩展性:解决方案具有极高的适应性和灵活性,可以广泛应用于通用计算和AI专用场景。用户可以灵活地调整和优化系统资源的使用,从而实现最优的性能和效果。
展 望
大语言模型已经彻底改变了智能化应用的生态,大语言模型带来的涌现能力赋予了其巨大的应用前景,成为足以改变商业竞争态势的重要能力。基于英特尔至强可扩展处理器的H3C UniServer R6900 G6服务器在当前算力稀缺、资源不足的情况下,为中小企业提供了经济、高效、灵活的AI算力平台选项,可以助力用户投入到AI竞赛中,为业务带来切实的收益。
除了用于大语言模型的微调和推理之外,基于英特尔至强可扩展处理器的H3C UniServer R6900 G6服务器具备的强大通用性意味着,其能够在更多领域发挥价值,而对于有更高性能需求的场景,该方案也能够通过服务器节点扩展来提供更高的算力。面向未来,英特尔与H3C还将进一步合作,包括采用新一代硬件平台,通过软件工具套件进行性能优化,携手拓展AI生态等,助力用户在AI时代获得成功。
审核编辑:刘清
-
处理器
+关注
关注
68文章
19286浏览量
229832 -
英特尔
+关注
关注
61文章
9964浏览量
171771 -
PCIe
+关注
关注
15文章
1239浏览量
82652 -
人工智能
+关注
关注
1791文章
47274浏览量
238484
原文标题:基于英特尔® 至强® 可扩展处理器的H3C UniServer R6900 G6服务器加速大语言模型微调及推理
文章出处:【微信号:英特尔中国,微信公众号:英特尔中国】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
英特尔发布至强6性能核处理器
英特尔®至强®可扩展处理器助力智慧医疗的数字化转型

128核性能猛兽,剑指云数据中心算力升级!英特尔发布至强6性能核处理器

开箱即用,AISBench测试展示英特尔至强处理器的卓越推理性能

采用144核,能效提升66%!英特尔至强6处理器震撼上市,加速数据中心升级

英特尔发布至强6能效核处理器

重磅!英特尔发布intel3制程至强6能效核处理器,赋能数据中心能效升级


全新 µATX 服务器载板为英特尔 Ice Lake D 处理器系列产品提供更多可扩展性

第五代英特尔至强处理器,AI特化的通用服务器CPU

英特尔至强处理器优化升级,助力打造未来高能效数据中心
H3C UIS超融合方案采用第五代英特尔至强可扩展处理器





 工商网监
工商网监
评论