 摩尔线程、无问芯穹合作完成国产全功能GPU千卡集群
摩尔线程、无问芯穹合作完成国产全功能GPU千卡集群
近日,摩尔线程与无问芯穹共同披露,他们成功地完成了由国产全功能GPU——摩尔线程MTT S4000所构成的千卡集群驱动的大规模AI模型“MT-infini-3B”的训练工作,并使用无问芯穹的AI Studio PaaS平台进行构建。
据介绍,此项训练历时13.2天,过程稳定而有序,集群整体运行稳定性达到了100%。相较于单机训练,千卡集群的扩展效率提升了超过90%。
此次实训被誉为“充分证明了夸娥千卡智算集群在大模型训练中的可靠性,同时开创了国产大语言模型与国产GPU千卡智算集群深度合作的新模式”。
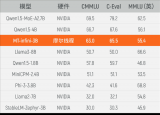
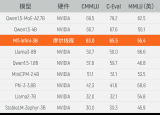
值得注意的是,经过此次实训,MT-infini-3B模型的性能在同类模型中名列前茅。在C-Eval、MMLU、CMMLU三个测试集中,其表现均优于其他在国际主流硬件上训练的模型。
无问芯穹的联合创始人兼CEO夏立雪表示,公司正致力于开发“M种模型”和“N种芯片”间的“MxN”中间层产品,以实现多种大模型算法在多元化芯片上的高效、统一部署。
他还透露,无问芯穹已与摩尔线程建立了深度战略合作关系,而本次“MT-infini-3B”的训练成果则是业内首例基于国产GPU芯片的从零开始到全面大模型实训的成功案例。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
gpu
+关注
关注
28文章
4850浏览量
130005 -
语言模型
+关注
关注
0文章
551浏览量
10498 -
摩尔线程
+关注
关注
2文章
216浏览量
4871
发布评论请先 登录
相关推荐
国产千卡GPU集群完成大模型训练测试,极具高兼容性和稳定性
卡集群的方式成为了必然的选择。 2023年底,摩尔线程推出首个全国产千卡千亿模型训练平台“

无问芯穹实现七家国产芯片DeepSeek适配
近日,无问芯穹宣布了一个重大进展:其DeepSeek-R1、V3系列模型已成功适配并优化至壁仞、海光、摩尔
性能提升近一倍!壁仞科技携手无问芯穹,在千卡训练集群等领域取得技术新突破
随着智能算力需求的倍增,到2024年,千卡算力集群已成为国内大模型训练的必备场景。壁仞科技,作为国内少数拥有原创训推一体架构的高端算力芯片厂商之一,与在AI算力市场具有重要影响力的无问
发表于 11-05 18:45
•1266次阅读

摩尔线程与羽人科技完成大语言模型训练测试
近日,摩尔线程与羽人科技携手宣布,双方已成功实现夸娥(KUAE)千卡智算集群与羽人系列模型解决方案的训练兼容适配。在本次测试中,羽人科技通过摩尔
摩尔线程和乐创能源签署战略合作协议
近日,摩尔线程和乐创能源签署了战略合作协议,双方将聚焦能源大模型的创新与应用,围绕新能源领域的电池、新能源发电、负荷管理、需求侧响应等产品技术方向,共同研发能源大模型。依托摩尔
摩尔线程与智谱AI完成大模型性能测试与适配
近日,摩尔线程与智谱AI在人工智能领域开展了一轮深入的合作,共同对GPU大模型进行了适配及性能测试。此次测试不仅涵盖了大模型的推理能力,还涉及了基于
摩尔线程千卡智算集群与滴普企业大模型已完成训练及推理适配
近日,摩尔线程与国内领先的数据智能服务商滴普科技共同宣布,摩尔线程夸娥(KUAE)千卡智算集群与

摩尔线程助力AI大模型训练与计算升级,共建美好数字化未来
此外,在中关村国际技术交易大会高精尖技术产品首发会上,摩尔线程与无问芯穹联合宣布,双方正致力于开


燧原科技与无问芯穹签约宣布共同打造千卡集群案例
3月31日,在无问芯穹举办的以“多元计算·泛在链接”为主题的AI算力优化论坛暨产品发布会上,燧原科技与无





 工商网监
工商网监
评论