 澳鹏入选亿欧大模型基础层图谱,以优质数据赋能AGI智能涌现
澳鹏入选亿欧大模型基础层图谱,以优质数据赋能AGI智能涌现
上海2024年5月27日/美通社/ -- 自ChatGPT的发布引发全球范围内对大模型的广泛关注以来,目前,国内公布的大模型数量已超过300个,行业呈现出"百模大战"的竞争格局。在此背景下,亿欧近日发布《2024中国"百模大战"竞争格局分析报告》,全方位呈现大模型产业现状。作为产业链上的重要一环,澳鹏Appen凭借高质量的大模型数据能力入选大模型基础层图谱。与此同时,作为大模型数据领域的代表案例,本次报告还分析了澳鹏如何成功助力全球15,000+个AI项目的研发及商业化,赋能AGI智能涌现。

澳鹏Appen凭借高质量的大模型数据能力入选大模型基础层图谱
随着"数据二十条"等一系列政策措施相继出台,数据要素市场的探索与发展已步入高速增长阶段。据亿欧预计,2025年数据要素市场规模可达1990亿元,年复合增长率可达25%。尤其是在人工智能快速迭代、大模型与数据相得益彰的发展态势中,数据要素的战略地位进一步凸显。
澳鹏(中国)自主研发的大模型智能开发平台集大模型数据准备、训练、推理、部署应用于一体,支持从数据集管理、数据标注、模型评估、模型调优、训练平台部署及标注工具部署等大模型定制开发的全流程需求,助力企业轻松拥抱大模型。
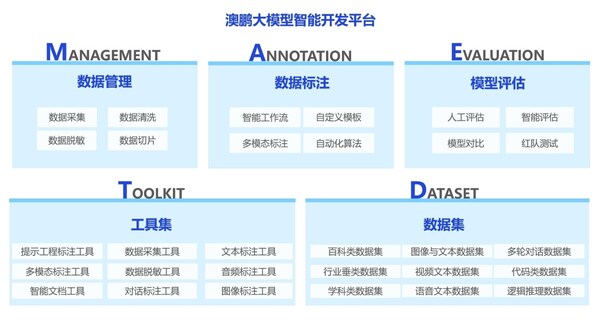
澳鹏(中国)自主研发的大模型智能开发平台
澳鹏大模型智能开发平台涵盖三大核心技术:自研的预标注模型、交互式分割模型及算法赋能的文档智能。首先,澳鹏通过海量图像、点云等数据,结合丰富的实际项目经验,预训练了车辆行驶、交通灯、停车位、人像识别等多场景预标注模型,可实现2D 3D联合拉框、视频连续帧mask追踪等全方位的预识别结果输出,大幅提高后续标注效率。
澳鹏自研预标注模型
为适应2D图像标注中多样化的物体类别分割与检测,澳鹏结合丰富的图像数据训练了交互式分割模型并内嵌于标注工具中。仅需通过点击的方式标记正确区域并纠正输出结果,即可完成物体识别;再结合连续帧信息引入,大幅提升2D图像标注效率。模型支持微调训练,可适应定制化的场景需求。

澳鹏交互式分割模型
为解决各类场景下的文档信息转化提取难题,澳鹏基于海量文档数据预训练了智能文档处理模型。支持输入图片或PDF格式文档,对带阴影图片、倾斜图片、手写表格、各类学科公式等多类信息进行识别,并转化成word文档输出,便于人工编辑校对。
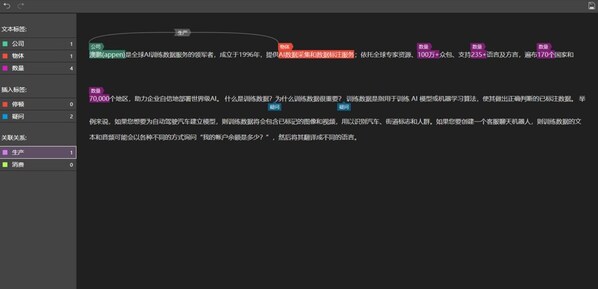
澳鹏Appen算法赋能的文档智能
随着大模型技术的演进,其赋能千行百业的能力不断提升。在数据集方面,澳鹏LLM数据库覆盖教育、法律、医疗、金融、百科等众多热门垂直领域,提供超过290种语言和方言的文本、语音数据库,并创建了一系列大模型专用数据集,如:百科类人工泛化文本问答数据集,知识类百科文本语料对数据库,58亿图文对数据库等等。澳鹏提供JSON格式的多学科题目,并拥有20万余条各种不同类型的高质量指令集文本及法律医疗百科类文本,通过多重质检环节严格把关数据质量,助力通用大模型和各种细分垂类大模型的训练和落地。
澳鹏Appen全球高级副总裁、大中华区及北亚区总经理田小鹏博士表示:"数据是决定机器学习模型性能的三大要素之一。随着各类大模型的智能涌现,数据,尤其是高质量的行业数据,正在成为决定大模型高速发展的关键因素。澳鹏自研的算法模型和核心技术,以及一系列大模型数据集,充分给予AI应用优质的数据养料,为大规模的大模型场景落地提供支持。"
审核编辑 黄宇
-
Agi
+关注
关注
0文章
80浏览量
10205 -
GPT
+关注
关注
0文章
354浏览量
15352 -
大模型
+关注
关注
2文章
2431浏览量
2651
发布评论请先 登录
相关推荐
云知声入选2024年度中关村科学城人工智能全景赋能典型案例
亿纬锂能荣获小鹏汽车“与鹏同行奖”

燧原科技入选先进计算赋能新质生产力典型应用案例
软通动力入选《人工智能数据标注产业图谱》
图为大模型一体机新探索,赋能智能家居行业
西井科技成功入选《2024大模型典型示范应用案例集》

AI模型在面对数据壁垒时的困境
知识图谱与大模型之间的关系
维智科技入选《2024中国数据智能产业图谱1.0》

大模型应用之路:从提示词到通用人工智能(AGI)
【大语言模型:原理与工程实践】揭开大语言模型的面纱
科大讯飞与华中师范大学合作 大模型赋能教育
亿纬动力凭借卓越的技术实力与赋能表现荣获“开发赋能奖”
普迪飞:人工智能时代,高质量大数据赋能芯片生产制造

数字化转型守护者丨芯盾时代入选“2023央国企数字化产业赋能图谱”多个领域






 工商网监
工商网监
评论