 来养一只羊驼宝宝吧?!快来Duo S上跑你的第一个生成式AI
来养一只羊驼宝宝吧?!快来Duo S上跑你的第一个生成式AI

OpenAI的创始成员Andrej Karpathy近日在一个周末内训练了一个微型LLaMA 2模型,并成功将其移植到C语言中。这个项目被他命名为Baby LLaMA 2,令人惊叹的是,推理代码仅有500行。
在RISC-V挑战赛中,我们期望在一个轻量级的RISC-V开发板上把这个模型运行起来,所以就有了这个赛题:Baby LLaMA 2 on Duo 速度优化

先看看效果:
赛题回顾
让 Baby LLaMA 2 运行在 Milk-V Duo 这样的小板子上是很有挑战的事情。本次竞赛旨在提升 Baby LLaMA 2 在 Milk-V Duo 平台上的性能,目标是实现更高的每秒 Token 处理速度。参赛者需要运用轻量级技术和编译器优化策略,结合麦克风语音输入或命令行输入提示词等多种方式,开发一个能够讲故事的机器人 Demo。该 Demo 应通过扬声器进行输出,并可借鉴小米米兔讲故事机器人的原型设计。
赛题地址:https://rvspoc.org/s2311/
实机教程与演示:让DuoS成为孩子的“故事王”
通过外接SPI显示屏、麦克风、音频输出设备,Duo团队实现了一个简易的场景Demo。(源码附在最后)
主要分为以下四个部分:
1、通过麦克风采集语音
2、经过语音转文字ASR模型实现语音实时转换
3、大模型实现“讲故事”实时交互
4、通过文字转语音TTS模型实现语音实时从扬声器播放“故事”
硬件连接方法:
需要设置和使用到的硬件主要有:duo s、SPI显示屏、麦克风、音频输出、按键、Wifi、UART串口、type-c(type-c这里只做供电使用,连接板子均通过串口实现)

1、SPI显示屏连接
将SPI显示屏背面的引脚对应的接口和duo s板卡的引脚对应
duo s整体引脚图如下:
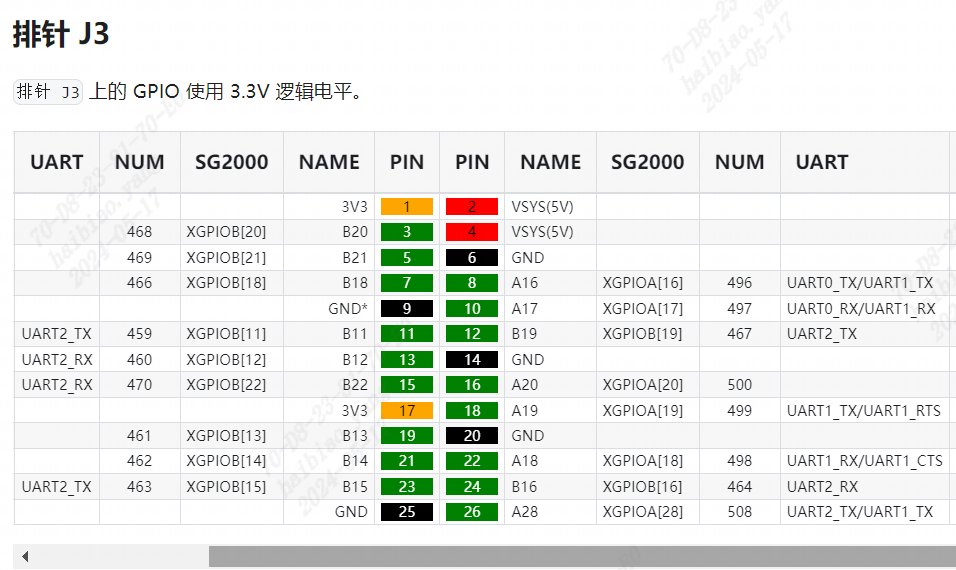
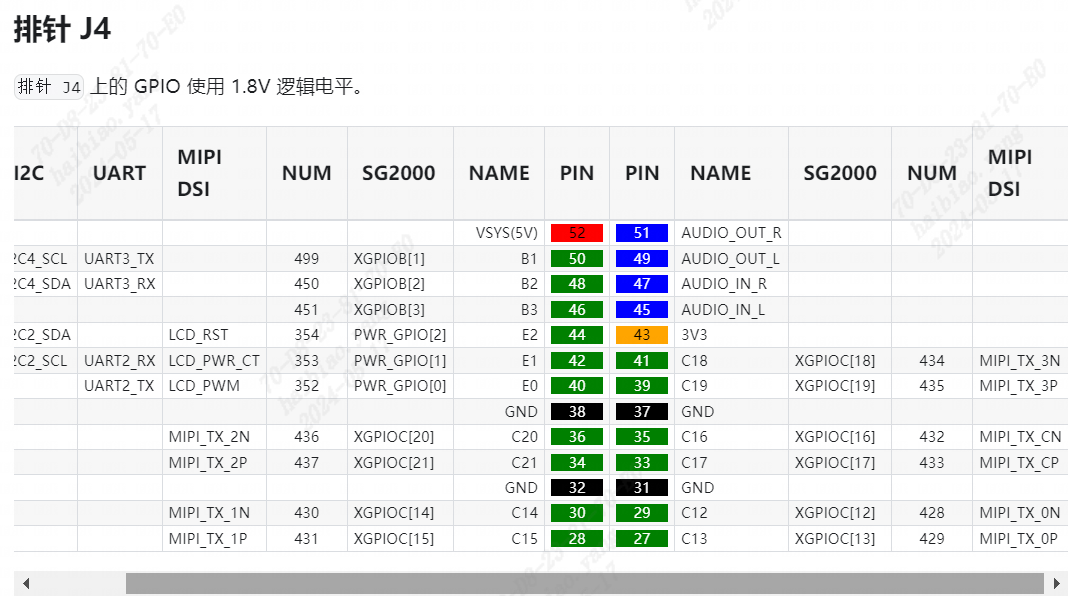
SPI屏幕对应的引脚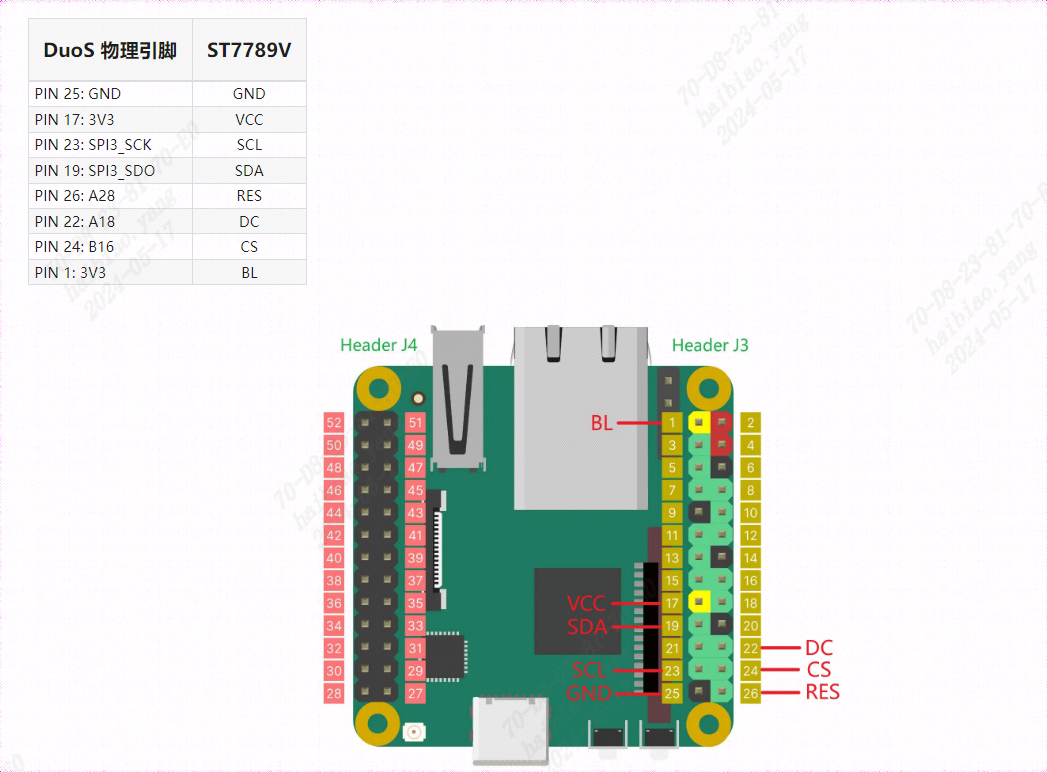
整体引脚对应连接图如下:
# 清屏cat /dev/zero > /dev/fb0# 花屏cat /dev/random > /dev/fb0
2、麦克风连接
使用USB声卡,注意麦克风和音频输出对应孔的正确连接
# 录音命令(Ctrl+C结束录音):arecord -f dat -c 1 -r 16000 XXXX.wav
3、音频输出连接
使用USB声卡,注意麦克风和扬声器输入孔的正确对应
# 播放录音:aplay XXXX.wav
4、按键连接
按键连接引脚如下:(只需要将引脚和duo s对应功能的引脚连接即可)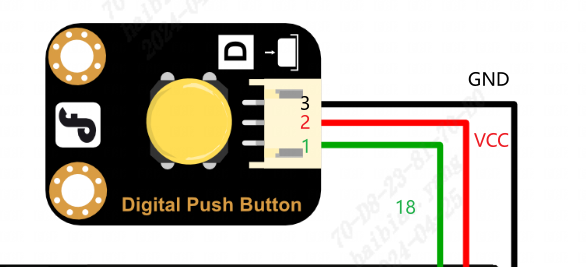
5、Wifi连接
这里通过一个一键运行脚本进行设置Wifi
vi wifi-duo-s.sh
# 执行i进入编辑模式,将以下内容写入########################################!/bin/bash# 提示用户输入WiFi的SSID和密码read -p "请输入WiFi的SSID: " ssidread -p "请输入WiFi的密码: " password# 编辑 /etc/wpa_supplicant.conf 文件cat < /etc/wpa_supplicant.confctrl_interface=/var/run/wpa_supplicantap_scan=1update_config=1
network={ ssid="$ssid" psk="$password" key_mgmt=WPA-PSK}EOF# 重启网络wpa_supplicant -B -i wlan0 -c /etc/wpa_supplicant.confecho "WiFi configuration completed."######################################## ESC退出编辑模式,:wq保存退出
# 执行shsh wifi-duo-s.sh
6、UART串口连接
将USB-TTL的引脚对应duo s的引脚,对应关系如下:
Milk-V duo s | <-----> | USB-TTL 串口 |
GND(pin 6) | <-----> | GND |
TX(pin 8) | <-----> | RX |
RX(pin 10) | <-----> | TX |
duo s的对应引脚如下:

USB-TTL引脚如下:

注:关于麦克风和音频输出的其他相关设置命令(可选)
# 查看录音设备arecord -l# 查看播放设备aplay -l# 查看具体设备号的信息(假设设备号为3)amixer contents -c 3
# 麦克风音量设置(name根据具体而定,常规是这个)amixer -Dhw:0 cset name='ADC Capture Volume' 24# 扬声器播放音量设置(假设音量设置为24)# 两种方式:(假设设备号为3)amixer -Dhw:3 cset name='Speaker Playback Volume' 24amixer cset -c 3 numid=6 24
软件使用方法
1、连接WiFi
sh wifi.sh# 输入连接wifi的ssid和pwd
2、安装运行依赖包
pip install requests -i https://pypi.tuna.tsinghua.edu.cn/simple some-package
3、运行故事机baby llama
python asr_chat-llama-baby.py# 在输出Wait for key press后,通过按键输入语音(按住即开始语音输入,松开即结束语音输入)
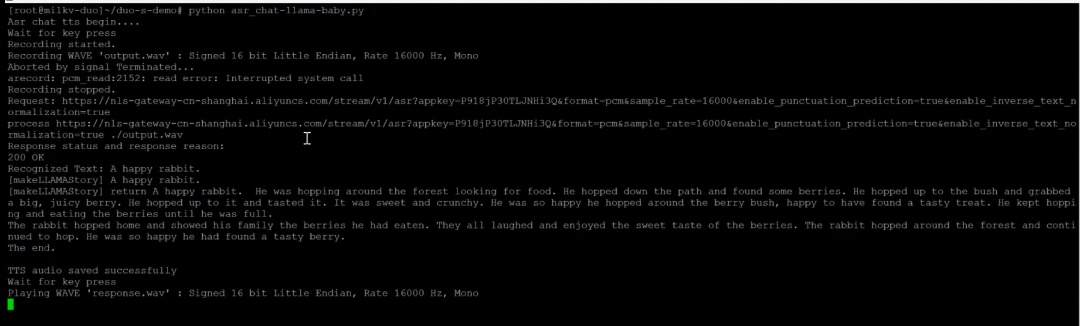
注:baby llama源码如下
# -*- coding: UTF-8 -*-import http.clientimport urllib.parseimport jsonimport subprocessimport timeimport httpximport requests
subprocess.Popen(['chmod', '+x', 'stable_demo'])subprocess.Popen(['./stable_demo'])print('Asr chat tts begin....')appKey = 'P918jP30TLJNHi3Q'#'P918jP30TLJNHi3Q'#s9NZm8ozBKyX63vK' #'RxkHgzYYYYLIP4OD'token = '31b129713beb46b8b0db321a005ecb0d'
# Chat ConfigurationAPI_KEY = "ebb785194c713e7b419ca8742277d414.hCBC11QCZvC5N0YK"BASE_URL = "https://open.bigmodel.cn/api/paas/v4/chat/completions"history = [{"role": "system", "content": "您好!"}]# Aliyun# url = 'https://nls-gateway-cn-shanghai.aliyuncs.com/stream/v1/asr'host = 'nls-gateway-cn-shanghai.aliyuncs.com'
def record_on_gpio(pin): is_pressed = False audioFilepath = './output.wav' while True: try: with open('/sys/class/gpio/gpio{}/value'.format(pin), 'r') as gpio_file: value = gpio_file.read().strip() #print('get key value {}',value) if value == '1' and not is_pressed: # 按键按下时开始录音 recording_process = subprocess.Popen(['arecord', '-f', 'dat', '-c', '1', '-r', '16000', 'output.wav']) is_pressed = True print("Recording started.")
if value == '0' and is_pressed: subprocess.Popen(['killall', 'arecord']) recording_process.wait() # 等待录音进程结束 is_pressed = False print("Recording stopped.") return audioFilepath except Exception as e: print("Error:", e)
def process_chunk(chunk,response_accumulator): if chunk.strip() == "[DONE]": return True, None try: data = json.loads(chunk) # print('process_chunk data:', data) if 'choices' in data and data['choices']: for choice in data['choices']: if 'delta' in choice and 'content' in choice['delta'] and choice['delta']['content']: result = choice['delta']['content'] # print('process_chunk result:', result) response_accumulator.append(result) return False, result except Exception as e: print(f"处理数据块时出错: {e}") return False, None
def chat(query, history): history += [{"role": "user", "content": query}] data = { "model": "glm-4", "messages": history, "temperature": 0.3, "stream": True, }
headers = { "Authorization": f"Bearer {API_KEY}", "Content-Type": "application/json" }
response_accumulator = [] response = requests.post(BASE_URL, data=json.dumps(data), headers=headers, stream=True) send_to_lvgl(f"[CLEAR]{query}: ") try: for chunk in response.iter_lines(): if chunk: chunk_str = chunk.decode("utf-8") if chunk_str.startswith("data: "): chunk_str = chunk_str[len("data: "):]
done, result = process_chunk(chunk_str,response_accumulator) # print('result is', result)
chunk_str = "data: " + chunk_str # print("Get response:", chunk_str) if result: send_to_lvgl(result)
if done: tts_text = ''.join(response_accumulator) tts_to_play(tts_text)
except Exception as e: print(f"Error: {str(e)}")
def send_to_lvgl(text): pipe_name = '/tmp/query_pipe' try: with open(pipe_name, 'w') as pipe: pipe.write(text) pipe.flush() except Exception as e: print(f"LVGL send error: {e}")
def process(request, token, audioFile) : # 读取音频 print('process {} {}'.format(request, audioFile)) with open(audioFile, mode = 'rb') as f: audioContent = f.read()
host = 'nls-gateway-cn-shanghai.aliyuncs.com'
# 设置HTTPS请求头部 httpHeaders = { 'X-NLS-Token': token, 'Content-type': 'application/octet-stream', 'Content-Length': len(audioContent) }
conn = http.client.HTTPSConnection(host)
conn.request(method='POST', url=request, body=audioContent, headers=httpHeaders)
response = conn.getresponse() print('Response status and response reason:') print(response.status ,response.reason)
try: body = json.loads(response.read()) text = body['result'] print('Recognized Text:', text) story = makeLLAMAStory(text) print('[makeLLAMAStory] return {}'.format(story)) #send_to_lvgl(story) tts_to_play(story) #chat_response = chat(text, history) #print('Chat Response:', chat_response) except ValueError: print('The response is not json format string')
conn.close()
def makeLLAMAStory(text): print('[makeLLAMAStory] {}'.format(text)) recording_process = subprocess.Popen(['./runq-fast-gcc', 'stories15M_q80.bin', '-t', '0.8', '-n', '256', '-i', text], stdout=subprocess.PIPE, stderr=subprocess.PIPE) return_value, stderr = recording_process.communicate() return return_value.decode('utf-8')
def oneloop(): print('Wait for key press') audioFilepath = record_on_gpio(499)
#print('Wait for first audio') format = 'pcm' sampleRate = 16000 enablePunctuationPrediction = True enableInverseTextNormalization = True enableVoiceDetection = False
# 设置RESTful请求参数 asrurl = f'https://{host}/stream/v1/asr' request = asrurl + '?appkey=' + appKey request = request + '&format=' + format request = request + '&sample_rate=' + str(sampleRate)
if enablePunctuationPrediction : request = request + '&enable_punctuation_prediction=' + 'true'
if enableInverseTextNormalization : request = request + '&enable_inverse_text_normalization=' + 'true'
if enableVoiceDetection : request = request + '&enable_voice_detection=' + 'true'
print('Request: ' + request)
process(request, token, audioFilepath)
def tts_to_play(text, file_path='response.wav'): ttsurl = f'https://{host}/stream/v1/tts' text_encoded = urllib.parse.quote_plus(text) tts_request = f"{ttsurl}?appkey={appKey}&token={token}&text={text_encoded}&format=wav&sample_rate=16000"
conn = http.client.HTTPSConnection(host) conn.request('GET', tts_request) response = conn.getresponse() body = response.read() if response.status == 200 and response.getheader('Content-Type') == 'audio/mpeg': with open(file_path, 'wb') as f: f.write(body) print('TTS audio saved successfully') subprocess.Popen(['aplay', file_path]) else: print('TTS request failed:', body) conn.close()
while True: try: oneloop() except Exception as e: print(e)
-
C语言
+关注
关注
183文章
7646浏览量
146202 -
AI
+关注
关注
91文章
41326浏览量
302707 -
模型
+关注
关注
1文章
3831浏览量
52287
发布评论请先 登录
【诚邀体验】 安利一个AI使用工具!

用一天时间让AI重写一个超轻量的AI 助手,并在60块的开发板上跑起来!

Linux 下交叉编译实战:跑起来你的第一个 STM32 程序




评论