 微软发布PhI-3-Vision模型,提升视觉AI效率
微软发布PhI-3-Vision模型,提升视觉AI效率
5 月 28 日,微软在 Build 2024 大会上推出了最新的 Phi-3 系列成员——Phi-3-vision。这一工具主打视觉应用,能有效处理图片文字信息,且在移动设备上也能运行自如。
Phi-3-vision 是一种小型多模式语言模型(SLM),主要适用于本地人工智能场景。其模型参数高达 42 亿,上下文序列包含 128k 个符号,可满足各种视觉推理和其他任务需求。
Microsoft 通过一篇新发表的论文[PDF]展示了 Phi-3-vision 的强大实力。与其他模型如 Claude 3-haiku、Gemini 1.0 Pro 相比,Phi-3-vision 毫不逊色。
此外,Microsoft 还对 Phi-3-vision 进行了多项测试,并将其与其他竞品模型进行了比较,包括字节跳动的 Llama3-Llava-Next(8B)、微软研究院与威斯康星大学、哥伦比亚大学联合开发的 LlaVA-1.6(7B)以及阿里巴巴通义千问 QWEN-VL-Chat 模型等。结果表明,Phi-3-vision 在多个项目中的表现均十分出色。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
微软
+关注
关注
4文章
6642浏览量
104804 -
人工智能
+关注
关注
1800文章
48062浏览量
242004 -
语言模型
+关注
关注
0文章
550浏览量
10410
发布评论请先 登录
相关推荐
字节跳动发布豆包大模型1.5 Pro
3.5 Sonnet等模型。 该模型采用大规模稀疏MoE架构,使用较小的激活参数进行预训练,却能等效7倍激活参数的Dense模型性能,远超业内MoE架构约3倍杠杆的常规
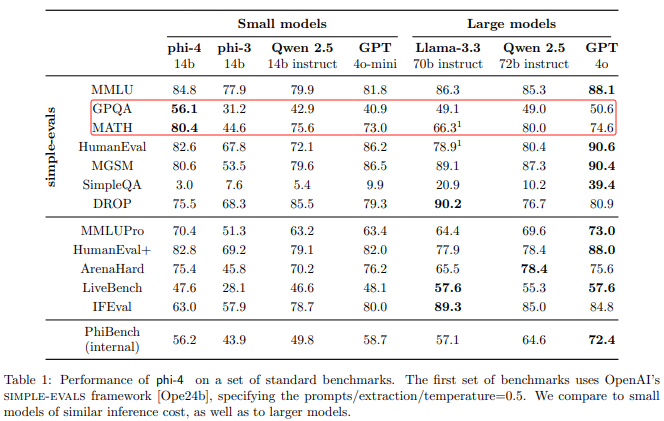
在算力魔方上本地部署Phi-4模型
智能水平上的一大飞跃。它不仅达到了之前只有Llama 3.1 405B模型才具备的智能水平,而且还超越了11月发布的GPT-4o模型。 本文我们将分享微软刚刚
虹软AI视觉赋能雷鸟V3 AI拍摄眼镜发布
近日,雷鸟创新正式发布全新一代AI拍摄眼镜——雷鸟V3。该产品搭载多项创新技术,包括融合虹软AI视觉算法的猎鹰影像系统、通义独家定制大
Meta发布新AI模型Meta Motivo,旨在提升元宇宙体验
Meta公司近日宣布,将推出一款名为Meta Motivo的全新人工智能模型。该模型具备控制类似人类的数字代理动作的能力,有望为元宇宙的用户体验带来显著提升。 Meta Motivo的发布
微软预览版Copilot Vision AI功能上线
微软公司近日宣布,将面向美国地区的Copilot Pro用户推出预览版的Copilot Vision AI功能。这一创新功能旨在通过人工智能技术,进一步提升用户的网页浏览体验。 Cop
AI干货补给站04 | 工业AI视觉检测项目实施第三步:模型构建
在当今智能制造的浪潮中,AI视觉检测技术凭借其高效、精准的特性,已然成为提升产品质量和生产效率的重要工具。为了助力从业者更好地理解和实施AI

微软发布Azure AI Foundry,推动云服务增长
。 Azure AI Foundry为用户提供了一个更为便捷的平台,使得在支持人工智能的大型语言模型之间切换变得轻松自如。这一创新工具的发布,无疑将极大地降低AI应用的开发门槛,进一步
在英特尔酷睿Ultra7处理器上优化和部署Phi-3-min模型
2024年4月23日,微软研究院公布Phi-3系列AI大模型,包含三个版本:mini(3.8B参数)、small(7B参数)以及medium(14B参数)。
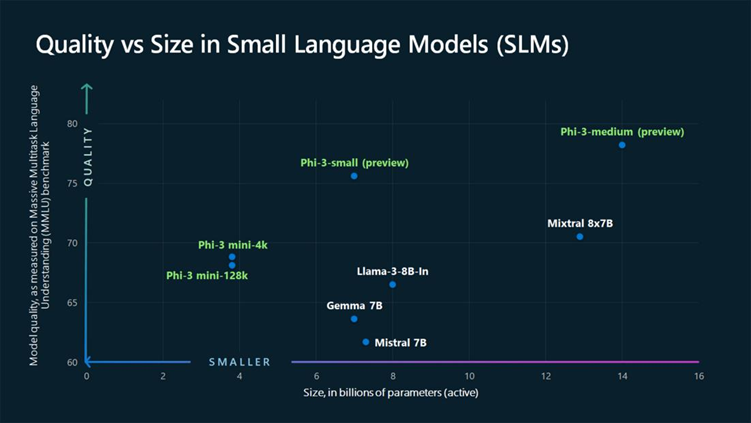
英特尔联手微软,推动移动设备低功耗计算及AI解决方案
据报道,微软于4月至5月间相继推出了多款Phi-3小型语言模型(SLM),这些模型以其“轻便易携且能在移动设备中运行”以及强大的视觉处理能力
微软发布视觉型AI新模型:Phi-3-vision
据悉,Phi-3-vision 作为微软 Phi-3 家族的首款多模态模型,继承自 Phi-3-mini 的文本理解能力,兼具轻巧便携特性
英特尔优化AI产品组合,助力微软Phi-3家族模型
近日,英特尔宣布针对微软的Phi-3家族开放模型,成功验证并优化了其跨客户端、边缘及数据中心的AI产品组合。这一重要举措旨在提供更为灵活和高效的AI
英特尔与微软合作在其AI PC及边缘解决方案中支持多种Phi-3模型
近日,英特尔针对微软的多个Phi-3家族的开放模型,验证并优化了其跨客户端、边缘和数据中心的AI产品组合。
NVIDIA加速微软最新的Phi-3 Mini开源语言模型
NVIDIA 宣布使用 NVIDIA TensorRT-LLM 加速微软最新的 Phi-3 Mini 开源语言模型。TensorRT-LLM 是一个开源库,用于优化从 PC 到云端的 NVIDIA GPU 上运行的大语言
微软发布phi-3AI模型,性能超越GPT-3.5
微软称,带有38亿参数的phi-3-mini经过3.3万亿token的强化学习,其基础表现已经超过Mixtral 8x7B及GPT-3.5;此外,该模型可在手机等移动设备上运行,并在phi





 工商网监
工商网监
评论