 浪潮信息发布源2.0-M32开源大模型,模算效率大幅提升
浪潮信息发布源2.0-M32开源大模型,模算效率大幅提升
5月28日,浪潮信息发布“源2.0-M32”开源大模型。“源2.0-M32”在基于”源2.0”系列大模型已有工作基础上,创新性地提出和采用了“基于注意力机制的门控网络”技术,构建包含32个专家(Expert)的混合专家模型(MoE),并大幅提升了模型算力效率,模型运行时激活参数为37亿,在业界主流基准评测中性能全面对标700亿参数的LLaMA3开源大模型。
■ 算法层面,源2.0-M32提出并采用了一种新型的算法结构:基于注意力机制的门控网络(Attention Router),针对MoE模型核心的专家调度策略,这种新的算法结构关注专家模型之间的协同性度量,有效解决传统门控网络下,选择两个或多个专家参与计算时关联性缺失的问题,使得专家之间协同处理数据的水平大为提升。源2.0-M32采用源2.0-2B为基础模型设计,沿用并融合局部过滤增强的注意力机制(LFA, Localized Filtering-based Attention),通过先学习相邻词之间的关联性,然后再计算全局关联性的方法,能够更好地学习到自然语言的局部和全局的语言特征,对于自然语言的关联语义理解更准确,进而提升了模型精度。
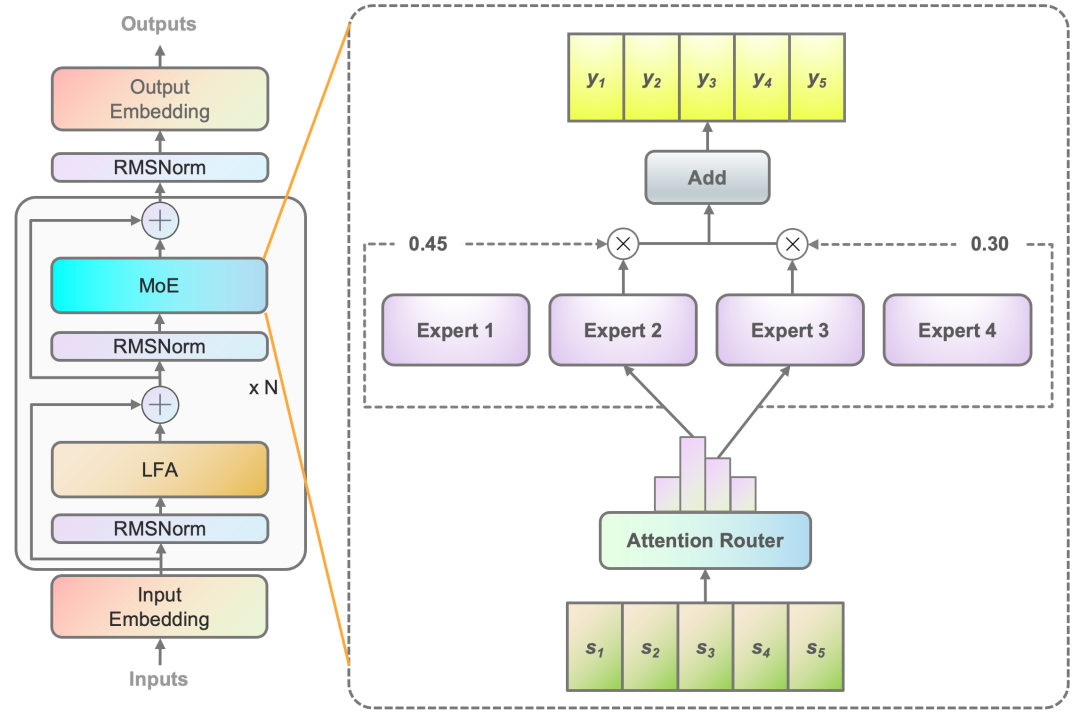
Figure1基于注意力机制的门控网络(Attention Router)
■ 数据层面,源2.0-M32基于2万亿的token进行训练、覆盖万亿量级的代码、中英文书籍、百科、论文及合成数据。大幅扩展代码数据占比至47.5%,从6类最流行的代码扩充至619类,并通过对代码中英文注释的翻译,将中文代码数据量增大至1800亿token。结合高效的数据清洗流程,满足大模型训练“丰富性、全面性、高质量”的数据集需求。基于这些数据的整合和扩展,源2.0-M32在代码生成、代码理解、代码推理、数学求解等方面有着出色的表现。
■ 算力层面,源2.0-M32采用了非均匀流水并行的方法,综合运用流水线并行+数据并行的策略,显著降低了大模型对芯片间P2P带宽的需求,为硬件差异较大训练环境提供了一种高性能的训练方法。针对MoE模型的稀疏专家计算,采用合并矩阵乘法的方法,模算效率得到大幅提升。
基于在算法、数据和算力方面全面创新,源2.0-M32的性能得以大幅提升,在多个业界主流的评测任务中,展示出了较为先进的能力表现,在MATH(数学竞赛)、ARC-C(科学推理)榜单上超越了拥有700亿参数的LLaMA3大模型。
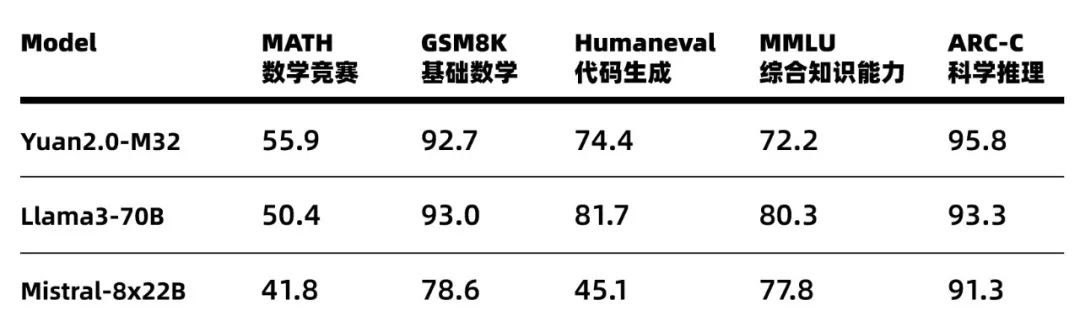
Figure2 源2.0-M32业界主流评测任务表现
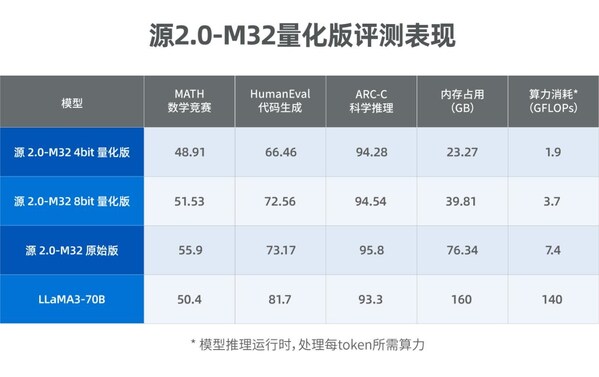
源2.0-M32大幅提升了模型算力效率,在实现与业界领先开源大模型性能相当的同时,显著降低了在模型训练、微调和推理所需的算力开销。在模型推理运行阶段,M32处理每token所需算力为7.4GFLOPs,而LLaMA3-70B所需算力为140GFLOPs。在模型微调训练阶段,对1万条平均长度为1024 token的样本进行全量微调,M32消耗算力约0.0026PD(PetaFLOPs/s-day),而LLaMA3消耗算力约为0.05PD。M32凭借特别优化设计的模型架构,在仅激活37亿参数的情况下,取得了和700亿参数LLaMA3相当的性能水平,而所消耗算力仅为LLaMA3的1/19,从而实现了更高的模算效率。
浪潮信息人工智能首席科学家吴韶华表示:当前业界大模型在性能不断提升的同时,也面临着所消耗算力大幅攀升的问题,对企业落地应用大模型带来了极大的困难和挑战。源2.0-M32是浪潮信息在大模型领域持续耕耘的最新探索成果,通过在算法、数据、算力等方面的全面创新,M32不仅可以提供与业界领先开源大模型相当的性能,更可以大幅降低大模型所需算力消耗。大幅提升的模算效率将为企业开发应用生成式AI提供模型高性能、算力低门槛的高效路径。M32开源大模型配合企业大模型开发平台EPAI(Enterprise Platform of AI),将助力企业实现更快的技术迭代与高效的应用落地,为人工智能产业的发展提供坚实的底座和成长的土壤,加速产业智能化进程。
-
人工智能
+关注
关注
1791文章
47135浏览量
238113 -
大模型
+关注
关注
2文章
2406浏览量
2621 -
生成式AI
+关注
关注
0文章
499浏览量
470
原文标题:浪潮信息发布源2.0-M32开源大模型,模算效率大幅提升,37亿激活参数性能对标LLaMA3-700亿
文章出处:【微信号:浪潮AIHPC,微信公众号:浪潮AIHPC】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
浪潮信息发布“源”Yuan-EB助力RAG检索精度新高
浪潮信息发布KOS AI定制版,大幅提升大模型训练效率
浪潮信息源2.0大模型与百度PaddleNLP全面适配
浪潮信息:元脑企智EPAI助力金融大模型快速落地

源2.0-M32大模型发布量化版 运行显存仅需23GB 性能可媲美LLaMA3
浪潮信息携全栈智算产品和方案亮相WAIC 2024
浪潮信息发布为大模型专门优化的分布式全闪存储AS13000G7-N系列

浪潮信息发布企业大模型开发平台"元脑企智"EPAI,加速AI创新落地

浪潮信息发布企业大模型开发平台“元脑企智”EPAI

浪潮信息"源2.0"大模型YuanChat支持英特尔最新商用AI PC

浪潮信息与英特尔合作推出一种大模型效率工具“YuanChat”

潞晨科技Colossal-AI与浪潮信息AIStation完成兼容性互认证
潞晨科技Colossal-AI + 浪潮信息AIStation,大模型开发效率提升10倍





 工商网监
工商网监
评论