 英特尔、AMD等联手推出UALink,希望用它取代Nvidia NVLink接口
英特尔、AMD等联手推出UALink,希望用它取代Nvidia NVLink接口
周四,英特尔、AMD、博通、思科、谷歌、HPE、Meta和微软宣布正在建立一个新的行业组织——Ultra Accelerator Link(UALink)推广组,以指导数据中心AI加速器芯片之间连接组件的发展。作为一项新的开放标准,他们希望用它来取代 Nvidia专有的 NVLink 接口。
去年七月,由英特尔、AMD、思科、Meta等公司支持的超以太网联盟 (UEC) 正式成立,旨在引领高性能网络的发展。现在,UALink横空出世,用于在同一系统或形成pod 的一组系统内连接 GPU/加速器。
如何“连接” GPU ?
Nvidia作为GPU技术的领航者,显著推动了GPU技术在高性能计算、通用人工智能(GenAI)等多个领域的应用发展。通过GPU间的互联,可以实现更复杂问题的处理及应用性能的飞跃。
GPU互连主要有三种基本方式:
1. PCI 总线:一般支持4至8个GPU通过PCI总线相连,而利用GigaIO FabreX内存架构等技术,这一数量可拓展至32个。CXL 技术也展现出了潜力,但是 Nvidia 对此的支持有限。对于多种应用场景,这些可重组的GPU架构作为GPU直接扩展的替代方案,具有吸引力。
2. 服务器间互连:以太网或 InfiniBand 可以连接包含 GPU 的服务器。这种连接级别通常称为横向扩展,其中较快的多 GPU 域通过较慢的网络连接以形成大型计算网络。其中,以太网长期担当计算机网络的核心,超以太网联盟的成立进一步推动其高性能发展。英特尔Gaudi -2 AI 处理器在芯片上拥有 24 个 100-Gigabit以太网连接,强化了在以太网领域的地位。Nvidia未加入Ultra Ethernet联盟,其在 2019 年 3 月收购 Mellanox 后,几乎独占了高性能 InfiniBand 互连市场。超以太网联盟旨在成为其他企业的“InfiniBand”。值得注意的是,英特尔过去曾是InfiniBand的主要推动者。
3. GPU 到 GPU 互连:鉴于快速且可扩展的GPU连接需求,Nvidia开发了NVLink,这是一种目前可在GPU间以每秒1.8TB 的速率传输数据的GPU间连接技术。还有NVLink机架级交换机,能够在无阻塞计算结构中支持多达576个全互联GPU。通过NVLink相连的GPU被称为“pod”,表明它们拥有独立的数据和计算域。
对于其他厂商来说,除了AMD用于连接MI300A APU的Infinity Fabric外,别无选择。如同InfiniBand与以太网的情况,需要一个由竞争对手组成的某种“Ultra”联盟来填补非Nvidia“pod”领域的空白。而UALink正是这一需求的响应。
UALink 剑指 NVLink !
与 NVLink 类似,构建一个强大、低延迟且高效的横向扩展网络至关重要,该网络可以轻松地将计算资源添加到单个实例(即将 GPU 和加速器视为一个大型系统或“pod”)。
在此背景下,UALink 和开放行业规范的出现对于标准化下一代硬件的 AI 和机器学习、HPC 和云应用接口至关重要。该小组将开发一种高速、低延迟的互连规范,旨在加速AI计算Pod中加速器与交换机间的扩展通信。
UALink 1.0规范将支持在AI计算Pod内部连接多达1,024个加速器,并允许Pod内加速器(如GPU)所附着的内存之间进行直接加载与存储操作。UALink发起小组已组建UALink联盟,预计该联盟将于2024年第三季度正式成立。1.0规范预期同样在2024年第三季度面世,并向加入UALink联盟的公司开放。 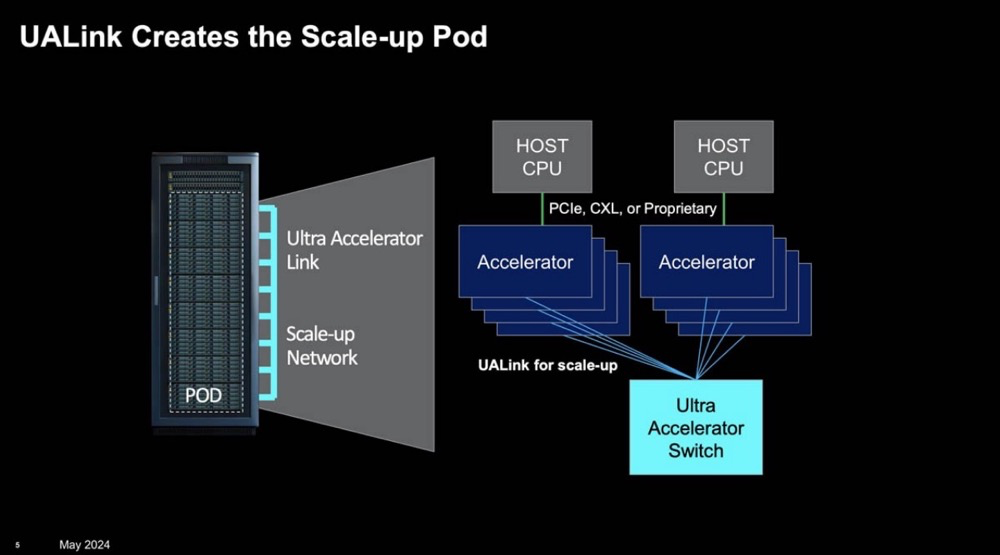
UALink Scale Up Pod
UALink 的一大优势是,它为业内其他厂商提供了一个追赶Nvidia的机会。如今,Nvidia已有能力生产NVSwitch盒,并将这些NVSwitch托盘集成进诸如Nvidia DGX GB200 NVL72之类的高端产品中。相比之下,英特尔今年销售了价值数亿美元的 AI 加速器,AMD凭借MI300X预计将售出数十亿美元的产品,但尽管如此,其在AI领域的规模仍无法与Nvidia相提并论。
UALink的出现,使得像博通这样的企业能够制造UALink交换机,助力其他企业实现规模扩展,并且这些交换机能跨不同厂商的多种加速器使用。此前,博通就制定了Atlas交换机计划,即利用AMD Infinity Fabric作为与Nvidia NVLink竞争的规模化升级方案,并应用于PCIe Gen7的博通交换机中,这些交换机可能会实现 UALink V1.0。
超以太网将继续作为向更多节点扩展的关键技术。博通可能会在其 800Gbps Thor 产品系列的早期型号中集成超以太网 NIC,但考虑到规范标准化的当前进程,全面实现UEC标准的支持可能还需等待下一代产品的问世。 
UALink Ultra Ethernet
为了支持 UALink,超以太网联盟主席 J Metz 博士表达了其积极的支持态度:“在很短的时间内,科技行业已经接受了AI和HPC揭示的挑战。在追求效率与性能提升的过程中,加速器,尤其是GPU的互连,需要一个全面的视角。我们相信UALink所采取的针对Pod集群问题的扩展解决方案,与UEC的横向扩展协议相得益彰。我们满怀期待,未来能携手合作,共同打造一个既开放又利于生态系统建设、覆盖全行业的解决方案,以全面满足不同场景下的扩展需求。”
最后
如今,许多企业都在尝试采用标准 PCIe 交换机,并构建基于 PCIe 的架构以扩展到更多加速器。然而,行业巨头们似乎视其更多为权宜之计。相比之下,Nvidia的NVLink成为了业内公认的横向扩展技术标杆。现在,一个开放标准的阵营正崛起,旨在打破其专有技术壁垒。
对于 AMD 和英特尔等公司来说,这提供了一条复制 NVLink 和 NVSwitch 功能的道路,同时能够与其他企业共享开发成果。博通这样的公司很可能是最大的赢家,无论是在横向还是纵向扩展场景下,它都将成为非Nvidia系统连接解决方案的首选供应商。无论AMD或英特尔谁能领先,博通都将作为连接技术的供应商而受益。对于超大规模数据中心运营商来说,投资标准化架构极具意义,无论最终采用哪家的终端设备。
这一切都需要时间。
审核编辑:刘清
-
英特尔
+关注
关注
61文章
9969浏览量
171809 -
以太网
+关注
关注
40文章
5427浏览量
171764 -
交换机
+关注
关注
21文章
2641浏览量
99664 -
GPU芯片
+关注
关注
1文章
303浏览量
5816 -
AI加速器
+关注
关注
1文章
69浏览量
8637
原文标题:“复仇者联盟”集结!英特尔、AMD等联手推出 UALink,剑指英伟达NVLink!
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
让x86再次伟大!英特尔AMD破天荒联手,要搞定软硬件兼容性

挑战英伟达NVLink!英特尔/谷歌等成立联盟,推出UALink 1.0

英特尔推出全新英特尔锐炫B系列显卡






 工商网监
工商网监
评论